

A API Llama 4 é uma interface poderosa que permite aos desenvolvedores integrar MetaOs mais recentes modelos de linguagem multimodais de grande porte, permitindo recursos avançados de processamento de texto, imagem e vídeo em vários aplicativos.

Visão geral da série Llama 4
A série Llama 4 da Meta apresenta modelos de IA de ponta projetados para processar e traduzir vários formatos de dados, incluindo texto, vídeo, imagens e áudio, aumentando assim a versatilidade entre aplicativos. A série inclui:
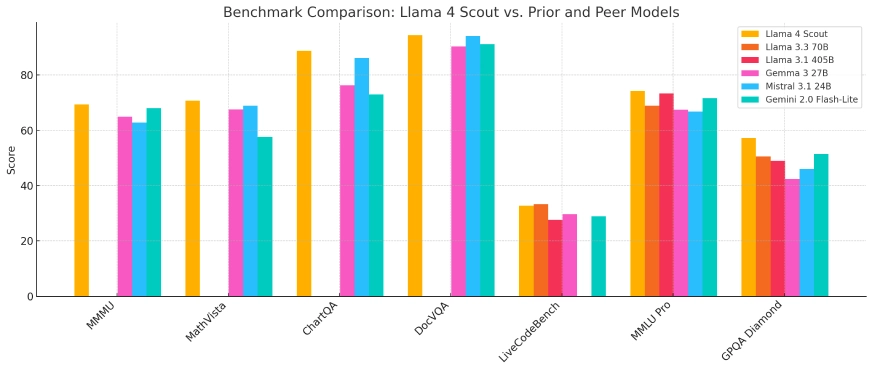
- Lhama 4 Scout: Um modelo compacto otimizado para implantação em uma única GPU Nvidia H100, apresentando uma janela de contexto de 10 milhões de tokens. Ele supera concorrentes como Gemma 3 e Mistral 3.1 do Google em vários benchmarks.
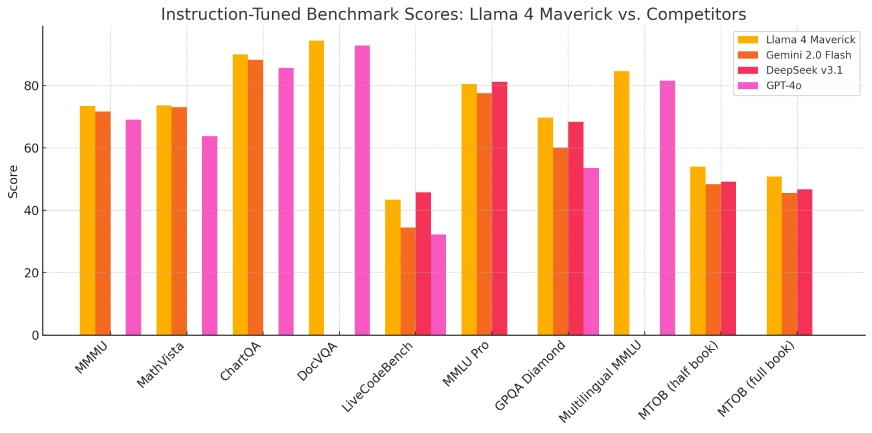
- Lhama 4 Maverick: Um modelo maior comparável em desempenho ao GPT-4o e ao DeepSeek-V3 da OpenAI em tarefas de codificação e raciocínio, utilizando menos parâmetros ativos.
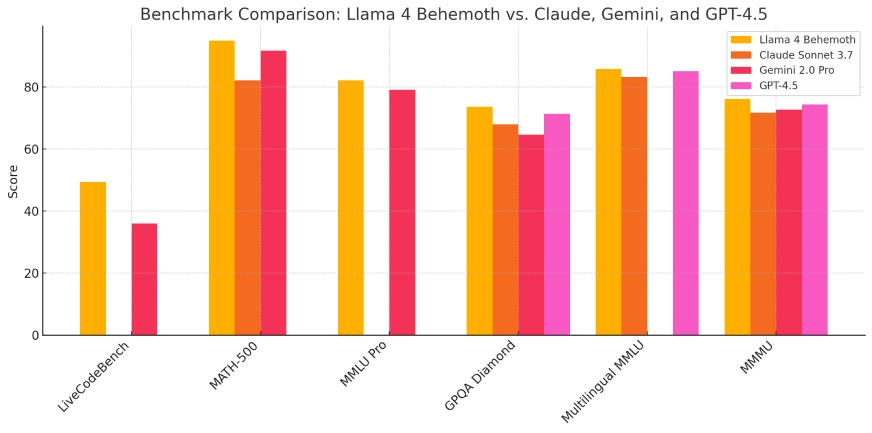
- Lhama 4 Behemoth:Atualmente em desenvolvimento, este modelo possui 288 bilhões de parâmetros ativos e um total de 2 trilhões, com o objetivo de superar modelos como GPT-4.5 e Claude Sonnet 3.7 em benchmarks STEM.
Esses modelos são integrados ao assistente de IA da Meta em plataformas como WhatsApp, Messenger, Instagram e web, aprimorando as interações do usuário com recursos avançados de IA.
| Modelo | Parâmetros totais | Parâmetros Ativos | Especialistas | Comprimento do contexto | Corre em | Acesso público | Ideal para |
|---|---|---|---|---|---|---|---|
| batedor | 109B | 17B | 16 | 10 milhões de tokens | Único Nvidia H100 | ✅ Sim | Tarefas leves de IA, aplicativos de longo contexto |
| Dissidente | 400B | 17B | 128 | Não especificado | GPU única ou múltipla | ✅ Sim | Pesquisa, aplicações empresariais, codificação |
| Behemoth | ~ 2T | 288B | 16 | Não especificado | Meta infra interna | ❌ Não | Treinamento e benchmarking de modelos internos |
Arquitetura Técnica e Inovações
A série Llama 4 emprega uma arquitetura de “mistura de especialistas” (MoE), uma abordagem inovadora que otimiza a utilização de recursos ativando apenas subconjuntos relevantes dos parâmetros do modelo durante tarefas específicas. Este design aprimora a eficiência computacional e o desempenho, permitindo que os modelos lidem com tarefas complexas de forma mais eficaz.
O treinamento desses modelos exigiu recursos computacionais substanciais. A Meta utilizou um cluster de GPU compreendendo mais de 100,000 chips Nvidia H100, representando uma das maiores infraestruturas de treinamento de IA até o momento. Esse amplo poder computacional facilitou o desenvolvimento de modelos com capacidades e métricas de desempenho aprimoradas.
Evolução dos modelos anteriores
Com base na fundação estabelecida por iterações anteriores, a série Llama 4 representa uma evolução significativa no desenvolvimento do modelo de IA da Meta. A integração de recursos de processamento multimodal e a adoção da arquitetura MoE abordam limitações observadas em modelos anteriores, como desafios em raciocínio e tarefas matemáticas. Esses avanços posicionam o Llama 4 como um concorrente formidável no cenário de IA.
Desempenho de referência e indicadores técnicos
Em avaliações de benchmark, o Llama 4 Scout demonstrou desempenho superior em relação a modelos como o Gemma 3 e o Mistral 3.1 do Google, particularmente em tarefas que exigem processamento de contexto extensivo. O Llama 4 Maverick exibiu capacidades equivalentes a modelos líderes como o GPT-4o da OpenAI, especialmente em tarefas de codificação e raciocínio, mantendo uma utilização de parâmetros mais eficiente. Esses resultados ressaltam a eficácia da arquitetura MoE e o regime de treinamento extensivo empregado.
Lhama 4 Scout
Lhama 4 Maverick
Lhama 4 Behemoth:
Cenários de Aplicativos
A versatilidade da série Llama 4 permite sua aplicação em vários domínios:
- Social Media Integration: Melhorando as interações do usuário em plataformas como WhatsApp, Messenger e Instagram por meio de recursos avançados baseados em IA, incluindo recomendações de conteúdo aprimoradas e agentes de conversação.
- Criação de Conteúdo: Auxiliar criadores na geração de conteúdo multimodal de alta qualidade por meio do processamento e síntese de texto, imagens e vídeos, agilizando assim o processo criativo.
- Ferramentas educacionais: Facilitar o desenvolvimento de sistemas de tutoria inteligentes que podem interpretar e responder a vários formatos de dados, proporcionando uma experiência de aprendizagem mais envolvente.
- Analista de negócios: Permitindo que as empresas analisem e interpretem conjuntos de dados complexos, incluindo informações textuais e visuais, para obter insights acionáveis e informar processos de tomada de decisão.
A integração dos modelos Llama 4 nas plataformas da Meta exemplifica sua utilidade prática e potencial para melhorar as experiências do usuário em diversas aplicações.
Considerações éticas e estratégia de código aberto
Enquanto a Meta promove a série Llama 4 como open-source, os termos de licenciamento incluem restrições para entidades comerciais com mais de 700 milhões de usuários. Essa abordagem gerou críticas da Open Source Initiative, destacando o debate em andamento sobre o equilíbrio entre acesso aberto e interesses comerciais no desenvolvimento de IA.
O investimento substancial da Meta, supostamente de até US$ 65 bilhões em infraestrutura de IA, ressalta o comprometimento da empresa em avançar os recursos de IA e manter uma vantagem competitiva no cenário de IA em rápida evolução.
Conclusão
A introdução da série Llama 4 da Meta marca um avanço fundamental na inteligência artificial, apresentando melhorias significativas no processamento multimodal, eficiência e desempenho. Por meio de designs arquitetônicos inovadores e investimentos computacionais substanciais, esses modelos estabelecem novos padrões em capacidades de IA. À medida que a Meta continua a integrar esses modelos em suas plataformas e a explorar novos desenvolvimentos, a série Llama 4 está pronta para desempenhar um papel crucial na formação da trajetória futura de aplicativos e serviços de IA.
Como chamar a API Llama 4 da CometAPI
1.Entrar para cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro
2.Obtenha a chave da API de credencial de acesso da interface. Clique em “Add Token” no token da API no centro pessoal, pegue a chave do token: sk-xxxxx e envie.
-
Obtenha a URL deste site: https://api.cometapi.com/
-
Selecione o Llama 4 (Nome do modelo: lhama-4-maverick; lhama-4-scout) endpoint para enviar a solicitação de API e definir o corpo da solicitação. O método de solicitação e o corpo da solicitação são obtidos de nosso site API doc. Nosso site também oferece o teste Apifox para sua conveniência.
- Para obter informações sobre o modelo lançado na API Comet, consulte https://api.cometapi.com/new-model.
- Para obter informações sobre o preço do modelo na API Comet, consulte https://api.cometapi.com/pricing
| Categoria | lhama-4-maverick | lhama-4-scout |
| Preços da API | Tokens de entrada: $ 0.48 / M tokens | Tokens de entrada: $ 0.216 / M tokens |
| Tokens de saída: $ 1.44/ M tokens | Tokens de saída: $ 1.152/ M tokens |
- Processe a resposta da API para obter a resposta gerada. Após enviar a solicitação da API, você receberá um objeto JSON contendo a conclusão gerada.