Gemini 2.5 Flash foi projetado para fornecer respostas rápidas sem comprometer a qualidade do resultado. Ele oferece suporte a entradas multimodais, incluindo texto, imagens, áudio e vídeo, tornando-o adequado para aplicações diversas. O modelo é acessível por meio de plataformas como Google AI Studio e Vertex AI, fornecendo aos desenvolvedores as ferramentas necessárias para integração perfeita em vários sistemas.
Informações básicas (Recursos)
Gemini 2.5 Flash apresenta vários recursos de destaque que o diferenciam dentro da família Gemini 2.5:
- Raciocínio híbrido: Os desenvolvedores podem definir o parâmetro thinking_budget para controlar com precisão quantos tokens o modelo dedica ao raciocínio interno antes da saída .
- Fronteira de Pareto: Posicionada no ponto ótimo de custo-desempenho, a Flash oferece a melhor relação preço-inteligência entre os modelos 2.5 .
- Suporte multimodal: Processa texto, imagens, vídeo e áudio de forma nativa, permitindo capacidades de conversação e análise mais ricas .
- Contexto de 1 milhão de tokens: Comprimento de contexto sem rival permite análise profunda e entendimento de documentos longos em uma única solicitação .
Versionamento do modelo
Gemini 2.5 Flash passou pelas seguintes versões principais:
- gemini-2.5-flash-lite-preview-09-2025: Melhor usabilidade de ferramentas: desempenho aprimorado em tarefas complexas e de múltiplas etapas, com aumento de 5% nas pontuações do SWE-Bench Verified (de 48.9% para 54%). Maior eficiência: ao habilitar o raciocínio, obtém-se saída de maior qualidade com menos tokens, reduzindo latência e custos.
- Preview 04-17: Lançamento de acesso antecipado com capacidade de “thinking”, disponível via gemini-2.5-flash-preview-04-17.
- Disponibilidade geral estável (GA): A partir de 17 de junho de 2025, o endpoint estável gemini-2.5-flash substitui a prévia, garantindo confiabilidade em produção sem mudanças na API em relação à prévia de 20 de maio .
- Descontinuação da prévia: Os endpoints de prévia foram programados para desligamento em 15 de julho de 2025; os usuários devem migrar para o endpoint GA antes dessa data .
Em julho de 2025, Gemini 2.5 Flash está agora publicamente disponível e estável (sem alterações em relação ao gemini-2.5-flash-preview-05-20 ).If you are using gemini-2.5-flash-preview-04-17, the existing preview pricing will continue until the scheduled retirement of the model endpoint on July 15, 2025, when it will be shut down. You can migrate to the generally available model "gemini-2.5-flash" .
Mais rápido, mais barato, mais inteligente:
- Metas de design: baixa latência + alta taxa de transferência + baixo custo;
- Aceleração geral no raciocínio, no processamento multimodal e em tarefas de textos longos;
- O uso de tokens é reduzido em 20–30%, reduzindo significativamente os custos de raciocínio.
Especificações técnicas
Janela de contexto de entrada: Até 1 milhão de tokens, permitindo ampla retenção de contexto.
Tokens de saída: Capaz de gerar até 8.192 tokens por resposta.
Modalidades compatíveis: Texto, imagens, áudio e vídeo.
Plataformas de integração: Disponível por meio do Google AI Studio e do Vertex AI.
Preços: Modelo competitivo baseado em tokens, facilitando implantação econômica.
Detalhes técnicos
Nos bastidores, Gemini 2.5 Flash é um grande modelo de linguagem baseado em Transformer, treinado com uma mistura de dados da web, de código, de imagem e de vídeo. As principais especificações técnicas incluem:
Treinamento multimodal: Treinado para alinhar múltiplas modalidades, o Flash pode combinar perfeitamente texto com imagens, vídeo ou áudio, útil para tarefas como sumarização de vídeo ou legendagem de áudio .
Processo de raciocínio dinâmico: Implementa um loop interno de raciocínio no qual o modelo planeja e decompõe prompts complexos antes da saída final .
Orçamentos de raciocínio configuráveis: O thinking_budget pode ser definido de 0 (sem raciocínio) até 24.576 tokens, permitindo equilibrar latência e qualidade da resposta .
Integração de ferramentas: Suporta Grounding with Google Search, Execução de código, Contexto de URL e Chamadas de função, possibilitando ações no mundo real diretamente a partir de prompts em linguagem natural .
Desempenho em benchmarks
Em avaliações rigorosas, Gemini 2.5 Flash demonstra desempenho líder no setor:
- LMArena Hard Prompts: Ficou em segundo lugar, atrás apenas do 2.5 Pro no desafiador benchmark Hard Prompts, demonstrando fortes capacidades de raciocínio em múltiplas etapas .
- Pontuação MMLU de 0.809: Supera o desempenho médio de modelos com 0.809 de acurácia no MMLU, refletindo amplo conhecimento de domínio e capacidade de raciocínio .
- Latência e taxa de transferência: Atinge 271.4 tokens/sec de velocidade de decodificação com 0.29 s de Time-to-First-Token, tornando-o ideal para cargas de trabalho sensíveis à latência.
- Líder em preço-desempenho: A \$0.26/1 M tokens, a Flash supera muitos concorrentes enquanto iguala ou supera seus resultados em benchmarks-chave .
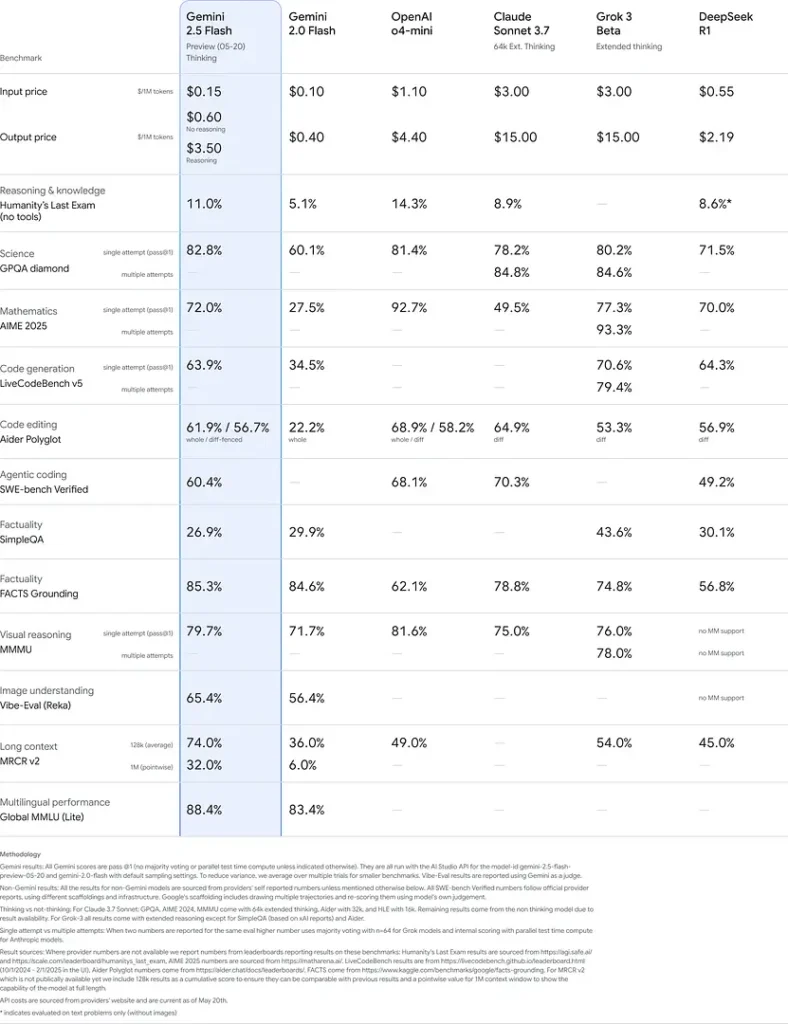
Esses resultados indicam a vantagem competitiva do Gemini 2.5 Flash em raciocínio, compreensão científica, resolução de problemas matemáticos, programação, interpretação visual e capacidades multilíngues:
Limitações
Embora poderoso, Gemini 2.5 Flash apresenta algumas limitações:
- Riscos de segurança: O modelo pode exibir um tom “pregador” e pode produzir respostas verossímeis, porém incorretas ou tendenciosas (alucinações), especialmente em consultas de borda. Supervisão humana rigorosa continua essencial.
- Limites de taxa: O uso da API é restrito por limites de taxa (10 RPM, 250.000 TPM, 250 RPD nos níveis padrão), o que pode impactar processamento em lote ou aplicações de alto volume.
- Patamar de inteligência: Embora excepcionalmente capaz para um modelo de flash, ainda é menos preciso que o 2.5 Pro nas tarefas de agentes mais exigentes, como programação avançada ou coordenação multiagente.
- Compensações de custo: Embora ofereça a melhor relação preço-desempenho, o uso extensivo do modo de thinking aumenta o consumo total de tokens, elevando os custos para prompts que exigem raciocínio profundo .