Detalhes técnicos
- Raciocínio adaptativo:
Gemini 2.5 Flash-Liteoferece raciocínio sob demanda, permitindo que os desenvolvedores aloque(m) recursos de computação apenas quando for necessário um raciocínio mais profundo. - Integrações de ferramentas: Compatibilidade total com as ferramentas nativas do Gemini 2.5, incluindo Grounding with Google Search, Code Execution, URL Context e Function Calling, para fluxos de trabalho multimodais contínuos.
- Model Context Protocol (MCP): Aproveita o MCP do Google para buscar dados da web em tempo real, garantindo que as respostas estejam atualizadas e contextualmente relevantes.
- Opções de implantação: Disponível por meio da CometAPI, Gemini API, Vertex AI e Google AI Studio, com uma trilha de prévia para que adotantes iniciais experimentem e forneçam feedback .
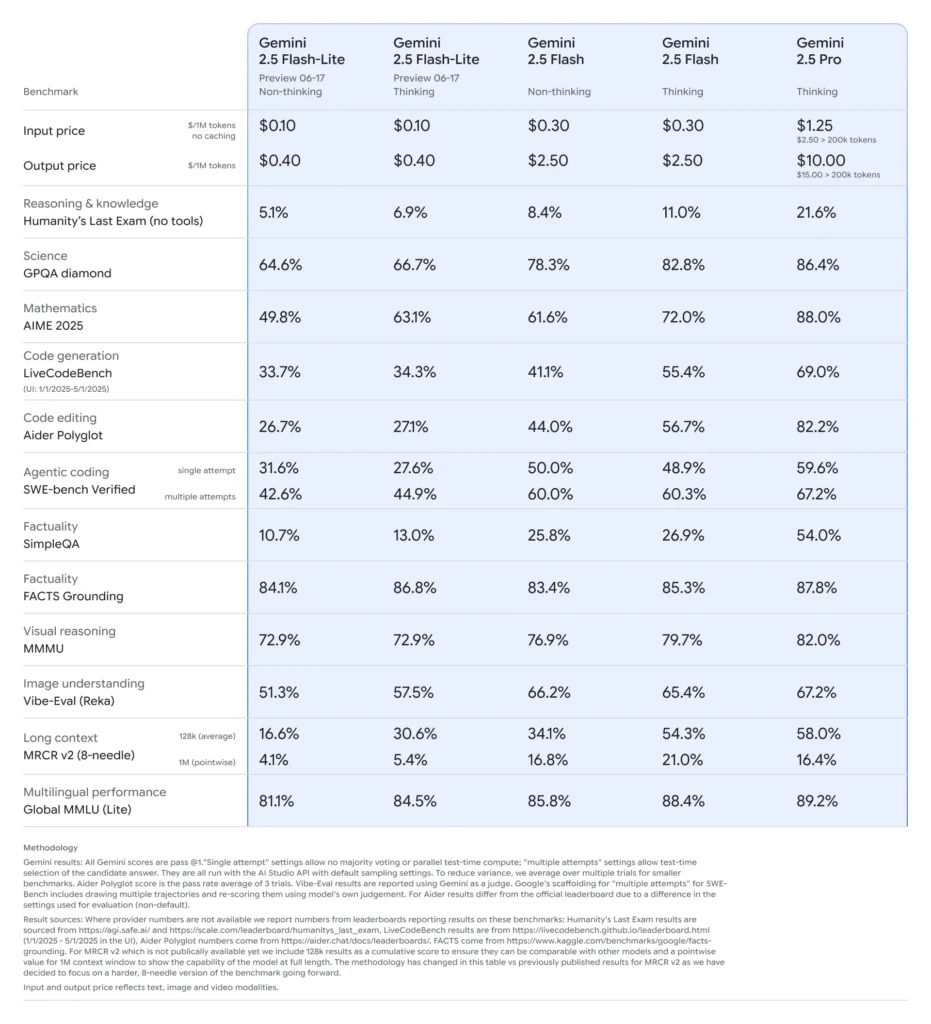
Desempenho em benchmarks de Gemini 2.5 Flash-Lite
- Latência: Atinge até 50% de redução no tempo de resposta mediano em comparação com o Gemini 2.5 Flash, com latências típicas abaixo de 100 ms em benchmarks padrão de classificação e sumarização.
- Vazão: Otimizado para cargas de trabalho de alto volume, sustentando dezenas de milhares de solicitações por minuto sem degradação de desempenho.
- Relação preço-desempenho: Demonstra redução de 25% no custo por 1.000 tokens em relação à versão Flash, tornando-o a escolha ótima de Pareto para implantações sensíveis a custos.
- Adoção no setor: Usuários iniciais relatam integração perfeita em pipelines de produção, com métricas de desempenho alinhadas ou superiores às projeções iniciais .
Casos de uso ideais
- Tarefas de alta frequência e baixa complexidade: marcação automática, análise de sentimento e tradução em lote
- Pipelines sensíveis a custos: extração de dados de grandes corpora de documentos, sumarização periódica em lote
- Cenários de borda e dispositivos móveis: quando a latência é crítica, mas os orçamentos de recursos são limitados
Limitações de Gemini 2.5 Flash-Lite
- Status de prévia: pode passar por mudanças na API antes do GA; as integrações devem considerar possíveis incrementos de versão.
- Sem ajuste fino em tempo real: não é possível enviar pesos personalizados; conte com engenharia de prompts e mensagens de sistema.
- Criatividade reduzida: ajustado para tarefas determinísticas e de alta vazão; menos indicado para geração aberta ou escrita “criativa”.
- Teto de recursos: escala linearmente apenas até ~16 vCPUs; além disso, os ganhos de vazão diminuem.
- Restrições multimodais: oferece suporte a entradas de imagem/áudio, porém com fidelidade limitada; não é ideal para tarefas pesadas de visão ou transcrição de áudio.
- Trade-off da janela de contexto : embora aceite até 1 M tokens, a inferência prática nessa escala pode apresentar degradação de vazão.