Especificações Técnicas do GPT-5.4 Mini
| Item | GPT-5.4 Mini (estimado com base em fontes oficiais + validação cruzada) |
|---|---|
| Família do modelo | Série GPT-5.4 (variante “mini” com boa relação custo-benefício) |
| Provedor | OpenAI |
| Tipos de entrada | Texto, Imagem |
| Tipos de saída | Texto |
| Janela de contexto | 400.000 tokens |
| Máx. de tokens de saída | 128.000 tokens |
| Corte de conhecimento | ~31 de maio de 2024 (herda a linhagem mini) |
| Suporte a raciocínio | Sim (mais leve em comparação ao GPT-5.4 completo) |
| Suporte a ferramentas | Chamada de funções, busca na web, busca em arquivos, agentes (inferido da família GPT-5) |
| Posicionamento | Modelo quase de fronteira, de alta velocidade e com boa relação custo-benefício |
O que é o GPT-5.4 Mini?
O GPT-5.4 Mini é uma variante de alta velocidade e com boa relação custo-benefício do GPT-5.4, projetada para cargas de trabalho sensíveis à latência e de alto volume. Ele traz uma parte significativa das capacidades de raciocínio, programação e multimodalidade do GPT-5.4 para um modelo menor e mais rápido, otimizado para sistemas em escala de produção.
Em comparação com modelos “mini” anteriores, o GPT-5.4 Mini é posicionado como um pequeno modelo quase de fronteira, o que significa que se aproxima do desempenho de modelos flagship enquanto reduz drasticamente o custo e o tempo de resposta.
Principais recursos do GPT-5.4 Mini
- Inferência de alta velocidade: otimizado para aplicações de baixa latência, como chatbots, copilotos e sistemas em tempo real
- Grande janela de contexto (400K): suporta documentos longos, fluxos de trabalho em várias etapas e memória de agentes
- Forte suporte a programação e agentes: projetado para uso de ferramentas, raciocínio em várias etapas e tarefas delegadas a subagentes
- Entrada multimodal: aceita entradas de texto e imagem para fluxos de trabalho mais ricos
- Escalabilidade com boa relação custo-benefício: significativamente mais barato que o GPT-5.4, mantendo forte capacidade de raciocínio
- Otimização para pipelines de agentes: ideal para arquiteturas multimodelo em que modelos grandes planejam e modelos mini executam
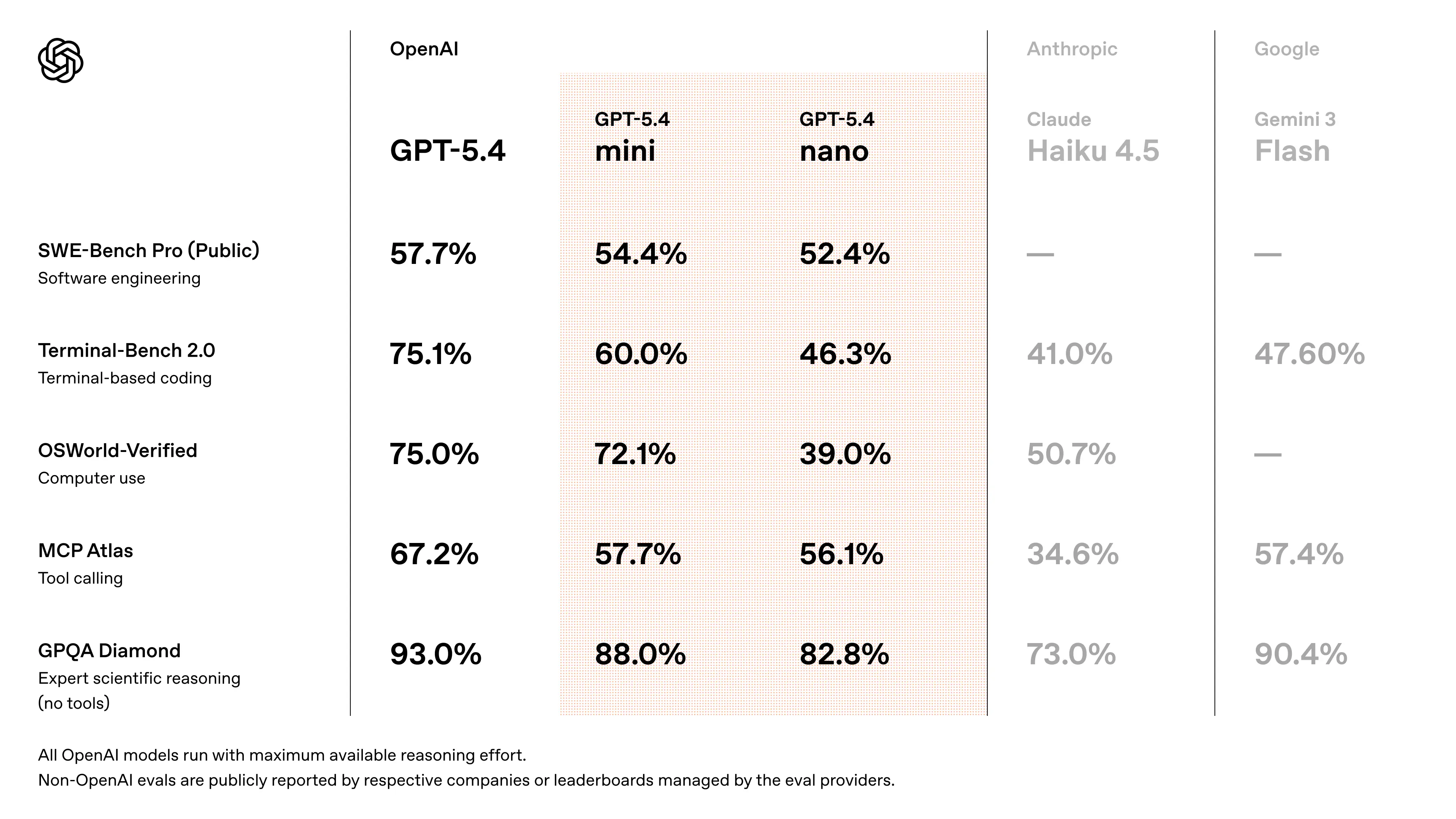
Desempenho de benchmark do GPT-5.4 Mini
- Aproxima-se do desempenho do GPT-5.4 em tarefas de programação no estilo SWE-Bench (~94–95% do desempenho do flagship) (estimativa validada de forma cruzada com base em discussões de lançamento)
- Melhorias significativas em relação ao GPT-5 Mini em:
- precisão de raciocínio
- confiabilidade no uso de ferramentas
- compreensão multimodal
- Projetado para superar gerações “mini” anteriores em fluxos de trabalho com agentes e benchmarks de programação
- medições de velocidade: testadores iniciais da API relatam ~180–190 tokens/seg no GPT-5.4 Mini (vs ~55–120 t/s para variantes mini mais antigas do GPT-5, dependendo dos modos de prioridade).
👉 Principal conclusão: o GPT-5.4 Mini oferece desempenho quase de fronteira por uma fração do custo e da latência, tornando-o ideal para sistemas escaláveis.
Casos de uso representativos
- Assistentes de programação e editores (plugins de IDE, Copilot): análise rápida de contexto, exploração de bases de código e conclusões rápidas tornam o GPT-5.4 Mini ideal para sugestões no editor, em que o tempo até o primeiro token é importante. O GitHub Copilot é uma integração inicial.
- Subagentes / trabalhadores delegados: quando um agente mestre delega tarefas curtas e rápidas (formatação, pequenos passos de raciocínio, buscas no estilo grep) a um trabalhador barato e veloz. A OpenAI posiciona mini/nano para esses papéis.
- Automação de API em alto volume: geração de código em massa, triagem automatizada de tickets, resumo de logs em escala, em que o custo por chamada e a latência são as principais restrições. Números de throughput da comunidade indicam vantagens operacionais materiais para o mini.
- Encapsulamento de ferramentas e toolchains: chamadas rápidas de ferramentas, nas quais o modelo orquestra chamadas para ferramentas externas (busca, grep, execução de testes) e retorna saídas compactas e acionáveis. A família GPT-5.4 inclui capacidades aprimoradas de “uso do computador”.
Como acessar a API do GPT-5.4 Mini
Etapa 1: Cadastre-se para obter a chave de API
Faça login em cometapi.com. Se você ainda não for nosso usuário, registre-se primeiro. Entre no seu console do CometAPI. Obtenha a credencial de acesso, a chave de API da interface. Clique em “Add Token” na área de token de API no centro pessoal, obtenha a chave de token: sk-xxxxx e envie.

Etapa 2: Envie solicitações para a API do GPT-5.4 Mini
Selecione o endpoint “gpt-5.4-mini” para enviar a solicitação de API e defina o corpo da solicitação. O método da solicitação e o corpo da solicitação são obtidos na documentação de API do nosso site. Nosso site também fornece teste no Apifox para sua conveniência. Substitua <YOUR_API_KEY> pela sua chave real do CometAPI da sua conta. A base url é Chat Completions e Responses.
Insira sua pergunta ou solicitação no campo content — é isso ao que o modelo responderá. Processe a resposta da API para obter a resposta gerada.
Etapa 3: Recupere e verifique os resultados
Processe a resposta da API para obter a resposta gerada. Após o processamento, a API responde com o status da tarefa e os dados de saída.