GLM-4.6 é o último grande lançamento da família GLM da Z.ai (anteriormente Zhipu AI): um modelo MoE (Mistura de Especialistas) de 4ª geração, de grande linguagem, ajustado para fluxos de trabalho agentivos, raciocínio de longo contexto e codificação do mundo real. O lançamento enfatiza integração prática de agentes/ferramentas, uma janela de contexto muito grande e disponibilidade de pesos abertos para implantação local.
Key features
- Contexto longo — janela de contexto nativa de 200K tokens (expandida de 128K). (docs.z.ai)
- Capacidade de codificação e agentiva — melhorias divulgadas em tarefas de codificação do mundo real e melhor invocação de ferramentas por agentes.
- Eficiência — consumo de tokens ~30% menor vs GLM-4.5 nos testes da Z.ai.
- Implantação e quantização — primeira integração anunciada de FP8 e Int4 para chips Cambricon; suporte nativo a FP8 em Moore Threads via vLLM.
- Tamanho do modelo e tipo de tensor — artefatos publicados indicam um modelo de ~357B parâmetros (tensores BF16 / F32) no Hugging Face.
Detalhes técnicos
Modalidades e formatos. O GLM-4.6 é um LLM apenas de texto (modalidades de entrada e saída: texto). Comprimento de contexto = 200K tokens; saída máxima = 128K tokens.
Quantização e suporte a hardware. A equipe relata quantização FP8/Int4 em chips Cambricon e execução nativa em FP8 em GPUs Moore Threads usando vLLM para inferência — importante para reduzir o custo de inferência e permitir implantações on-prem e em nuvens domésticas.
Ferramentas e integrações. O GLM-4.6 é distribuído pela API da Z.ai, redes de provedores de terceiros (por exemplo, CometAPI), e integrado em agentes de codificação (Claude Code, Cline, Roo Code, Kilo Code).
Detalhes técnicos
Modalidades e formatos. O GLM-4.6 é um LLM apenas de texto (modalidades de entrada e saída: texto). Comprimento de contexto = 200K tokens; saída máxima = 128K tokens.
Quantização e suporte a hardware. A equipe relata quantização FP8/Int4 em chips Cambricon e execução nativa em FP8 em GPUs Moore Threads usando vLLM para inferência — importante para reduzir o custo de inferência e permitir implantações on-prem e em nuvens domésticas.
Ferramentas e integrações. O GLM-4.6 é distribuído pela API da Z.ai, redes de provedores de terceiros (por exemplo, CometAPI), e integrado em agentes de codificação (Claude Code, Cline, Roo Code, Kilo Code).
Desempenho em benchmarks
- Avaliações publicadas: o GLM-4.6 foi testado em oito benchmarks públicos cobrindo agentes, raciocínio e codificação e mostra ganhos claros em relação ao GLM-4.5. Em testes de codificação do mundo real avaliados por humanos (CC-Bench estendido), o GLM-4.6 usa ~15% menos tokens vs GLM-4.5 e registra uma taxa de vitória de ~48.6% vs Claude Sonnet 4 da Anthropic (quase paridade em muitos rankings).
- Posicionamento: os resultados afirmam que o GLM-4.6 é competitivo com modelos líderes domésticos e internacionais (exemplos citados incluem DeepSeek-V3.1 e Claude Sonnet 4).
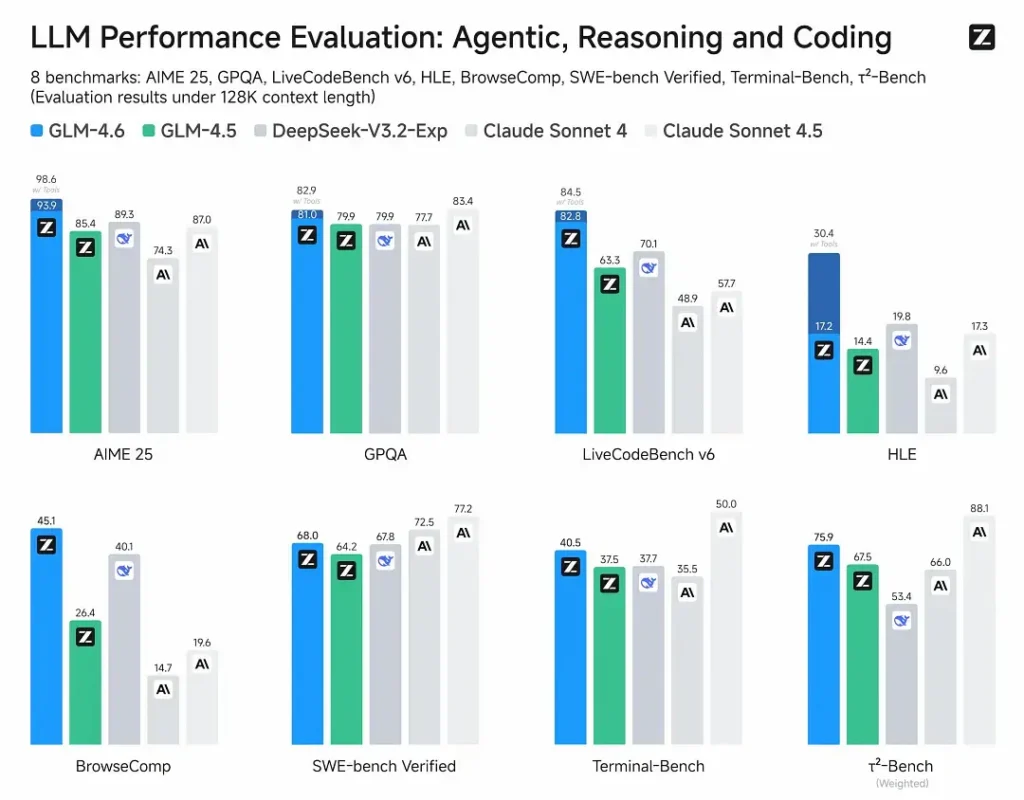
Limitações e riscos
- Alucinações e erros: como todos os LLMs atuais, o GLM-4.6 pode e de fato comete erros factuais — a documentação da Z.ai alerta explicitamente que as saídas podem conter erros. Os usuários devem aplicar verificação e recuperação/RAG para conteúdo crítico.
- Complexidade do modelo e custo de serving: o contexto de 200K e saídas muito grandes aumentam drasticamente as demandas de memória e latência e podem elevar os custos de inferência; são necessárias quantização/engenharia de inferência para operar em escala.
- Lacunas de domínio: embora o GLM-4.6 relate desempenho forte em agentes/codificação, alguns relatos públicos observam que ele ainda fica atrás de certas versões de modelos concorrentes em microbenchmarks específicos (por exemplo, algumas métricas de codificação vs Sonnet 4.5). Avalie por tarefa antes de substituir modelos de produção.
- Segurança e políticas: pesos abertos aumentam a acessibilidade, mas também levantam questões de responsabilização (mitigações, guardrails e red-teaming continuam sendo responsabilidade do usuário).
Casos de uso
- Sistemas agentivos e orquestração de ferramentas: rastros longos de agentes, planejamento com múltiplas ferramentas, invocação dinâmica de ferramentas; o ajuste agentivo do modelo é um ponto de venda chave.
- Assistentes de codificação do mundo real: geração de código multi-turn, revisão de código e assistentes de IDE interativos (integrados no Claude Code, Cline, Roo Code — segundo a Z.ai). As melhorias de eficiência de tokens o tornam atraente para planos de desenvolvedores de uso intenso.
- Fluxos de trabalho com documentos longos: sumarização, síntese multidocumento, revisões jurídicas/técnicas extensas devido à janela de 200K.
- Criação de conteúdo e personagens virtuais: diálogos prolongados, manutenção consistente de persona em cenários multi-turn.
Como o GLM-4.6 se compara a outros modelos
- GLM-4.5 → GLM-4.6: mudança de nível em tamanho de contexto (128K → 200K) e eficiência de tokens (~15% menos tokens no CC-Bench); uso aprimorado de agentes/ferramentas.
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: a Z.ai reporta quase paridade em vários rankings e uma taxa de vitória de ~48.6% nas tarefas de codificação do mundo real do CC-Bench (ou seja, competição próxima, com alguns microbenchmarks onde o Sonnet ainda lidera). Para muitas equipes de engenharia, o GLM-4.6 é posicionado como uma alternativa de custo eficiente.
- GLM-4.6 vs outros modelos de longo contexto (DeepSeek, variantes do Gemini, família GPT-4): o GLM-4.6 enfatiza contexto amplo e fluxos de trabalho de codificação agentiva; os pontos fortes relativos dependem da métrica (eficiência de tokens/integração de agentes vs precisão de síntese de código bruto ou pipelines de segurança). A seleção empírica deve ser orientada por tarefa.
Último modelo carro-chefe da Zhipu AI, GLM-4.6, lançado: 355B de parâmetros totais, 32B ativos. Supera o GLM-4.5 em todas as capacidades centrais.
- Codificação: Alinha-se ao Claude Sonnet 4, melhor na China.
- Contexto: Expandido para 200K (de 128K).
- Raciocínio: Melhorado, suporta chamadas de ferramentas durante a inferência.
- Busca: Chamadas de ferramentas e desempenho de agentes aprimorados.
- Redação: Melhor alinhamento às preferências humanas em estilo, legibilidade e interpretação de papéis.
- Multilíngue: Tradução entre idiomas aprimorada.