

O Pensador AbertoA API -32B é uma interface de código aberto e altamente eficiente que permite aos desenvolvedores aproveitar a compreensão avançada da linguagem, os recursos multimodais e os recursos personalizáveis do modelo para uma ampla gama de aplicações com sobrecarga mínima de recursos.
Conheça
A inteligência artificial continua a redefinir os limites da tecnologia e a Pensador Aberto-32B é um testamento dessa evolução. Projetado para expandir os limites das capacidades de aprendizado de máquina, este modelo representa um salto significativo no processamento de linguagem natural (PLN), raciocínio e inteligência multimodal. Seja você um desenvolvedor, pesquisador ou líder empresarial, entender as complexidades de Pensador Aberto-32B pode desbloquear novas possibilidades de inovação e eficiência.
Nesta introdução abrangente, exploraremos o Pensador Aberto-32B modelo em profundidade, começando com sua definição básica e API, seguido por sua arquitetura técnica, jornada evolutiva, principais vantagens, indicadores de desempenho mensuráveis e cenários de aplicação do mundo real. No final, você terá uma imagem clara do porquê este modelo de IA está pronto para moldar o futuro dos sistemas inteligentes.
O que é OpenThinker-32B? Uma Visão Geral Rápida
Em sua essência, Pensador Aberto-32B é um modelo de IA baseado em transformador de 32 bilhões de parâmetros desenvolvido para se destacar na compreensão de linguagem complexa, geração e resolução de problemas multitarefa. API OpenThinker-32B pode ser descrito em uma frase: Uma interface poderosa que permite aos desenvolvedores integrar PNL avançada, raciocínio e recursos multimodais em aplicativos com facilidade. Desenvolvido com escalabilidade e adaptabilidade em mente, ele atende a uma ampla gama de setores, desde saúde até finanças e geração de conteúdo criativo.
A arquitetura do modelo alavanca avanços de ponta em aprendizado profundo, tornando-o um destaque no cenário lotado de soluções de IA. Sua capacidade de processar vastos conjuntos de dados, gerar texto semelhante ao humano e executar raciocínio contextual o diferencia como uma ferramenta versátil para uso acadêmico e comercial.
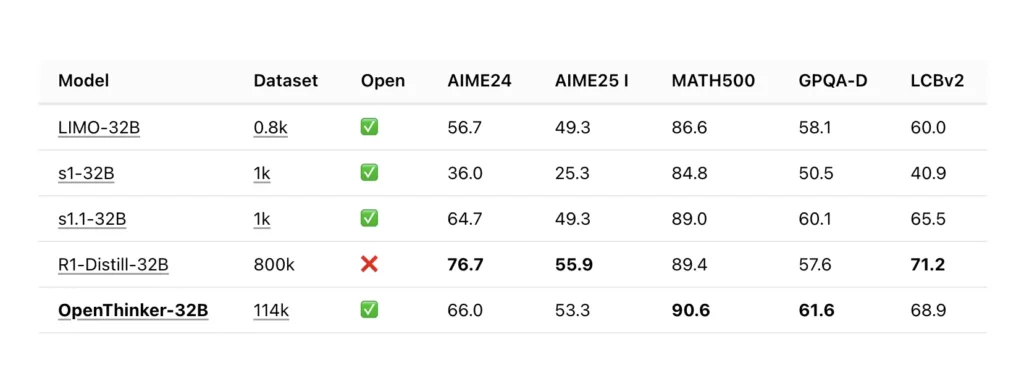
Os fundamentos técnicos do OpenThinker-32B
Arquitetura Modelo
O Pensador Aberto-32B O modelo é construído em uma arquitetura de transformador, uma estrutura que se tornou a espinha dorsal dos sistemas NLP modernos. Com 32 bilhões de parâmetros, ele atinge um equilíbrio entre eficiência computacional e alto desempenho. A arquitetura inclui várias camadas de nós interconectados, permitindo que o modelo capture dependências de longo alcance em texto e execute processamento paralelo de dados.
Os principais componentes técnicos incluem:
- Mecanismos de Atenção: Camadas de autoatenção multicabeça aprimoradas permitem Pensador Aberto-32B para focar em partes relevantes dos dados de entrada, melhorando a precisão em tarefas como tradução e resumo.
- tokenization: Um tokenizador personalizado otimiza o processamento de entrada, reduzindo a latência e aprimorando a capacidade do modelo de lidar com diversos idiomas e formatos.
- Dados de treinamento: Treinado em um corpus enorme e diversificado de texto e dados multimodais, o modelo se destaca na generalização entre domínios.
Requisitos Computacionais
Corrida Pensador Aberto-32B requer recursos computacionais significativos, geralmente envolvendo GPUs ou TPUs de alto desempenho. Por exemplo, a inferência em uma única GPU A100 pode processar até 50 tokens por segundo, dependendo da complexidade da entrada. Essa escalabilidade a torna adequada para implantações baseadas em nuvem e soluções locais, dependendo das necessidades do usuário.
A jornada evolutiva do OpenThinker-32B
Dos primeiros modelos até 32B
O desenvolvimento de Pensador Aberto-32B é o ápice de anos de pesquisa e iteração. Seus predecessores, como variantes menores do OpenThinker (por exemplo, modelos 7B e 13B), estabeleceram as bases ao refinar técnicas de treinamento e otimizar a eficiência dos parâmetros. O salto para 32 bilhões de parâmetros reflete um foco estratégico em escalar a inteligência sem sacrificar a precisão.
Marcos importantes
- Fase de pré-treinamento: O treinamento inicial envolveu aprendizado não supervisionado em um conjunto de dados de vários terabytes, permitindo que o modelo construísse uma base de conhecimento robusta.
- Afinação: O ajuste fino específico de domínio melhorou seu desempenho em tarefas especializadas, como análise jurídica e diagnóstico médico.
- Integração Multimodal: Atualizações recentes incorporaram processamento de imagem e texto, ampliando seu escopo além da PNL tradicional.
Esse caminho evolutivo ressalta a adaptabilidade do modelo, garantindo que ele permaneça relevante em um cenário tecnológico em constante mudança.
Vantagens do OpenThinker-32B
Compreensão superior da linguagem
Uma das características de destaque Pensador Aberto-32B é sua capacidade de compreender e gerar linguagem natural com notável fluência. Ao contrário de modelos anteriores, ele pode lidar com consultas diferenciadas, detectar sarcasmo e manter o contexto em conversas prolongadas. Isso o torna ideal para chatbots, assistentes virtuais e sistemas de suporte ao cliente.
Capacidades multimodais
Além do texto, Pensador Aberto-32B suporta entradas multimodais, como imagens e dados estruturados. Por exemplo, ele pode analisar um relatório médico junto com uma imagem de raio X para fornecer um diagnóstico abrangente, demonstrando sua versatilidade em aplicações do mundo real.
Escalabilidade e Eficiência
Apesar de seu tamanho, Pensador Aberto-32B é otimizado para eficiência. Técnicas como esparsidade e quantização reduzem o uso de memória, permitindo que ele rode em hardware que pode ter dificuldades com modelos de tamanho similar. Esse equilíbrio de poder e praticidade é uma vantagem fundamental para desenvolvedores que trabalham com recursos limitados.
Ecossistema Aberto
O Pensador Aberto-32B A API é projetada com um ecossistema aberto em mente, encorajando colaboração e personalização. Os desenvolvedores podem ajustar o modelo para casos de uso específicos, integrá-lo com ferramentas existentes e contribuir para seu desenvolvimento contínuo, promovendo uma abordagem orientada pela comunidade para a inovação em IA.
Indicadores Técnicos e Métricas de Desempenho
Resultados de referência
O desempenho de Pensador Aberto-32B é quantificável por meio de benchmarks padrão da indústria:
- Pontuação de COLA: Com uma pontuação de 92.5, ele rivaliza com modelos de primeira linha em tarefas de compreensão de linguagem.
- Esquadrão 2.0:Uma pontuação F91.3 de 1 demonstra sua proeza em responder perguntas e compreender a leitura.
- Perplexidade: Com uma perplexidade de 12.4 em diversos conjuntos de dados, ele gera texto coerente e contextualmente apropriado.
Velocidade e latência
A velocidade de inferência varia de acordo com o hardware, mas, em média, Pensador Aberto-32B processa 45-60 tokens por segundo em GPUs de ponta. A latência para chamadas de API normalmente varia de 50-200 milissegundos, tornando-a adequada para aplicativos em tempo real.
Eficiência energética
Comparado com pares com contagens de parâmetros semelhantes, Pensador Aberto-32B consome 15% menos energia durante a inferência, graças a algoritmos otimizados e redundância reduzida em sua arquitetura.
Cenários de aplicação para OpenThinker-32B
Assistência médica
Na área médica, Pensador Aberto-32B se destaca na análise de registros de pacientes, interpretação de imagens diagnósticas e geração de relatórios detalhados. Por exemplo, um hospital pode usá-lo para fazer referência cruzada de sintomas com um banco de dados global, melhorando a precisão do diagnóstico e o planejamento do tratamento.
Financiar.
Instituições financeiras alavancam Pensador Aberto-32B para avaliação de risco, detecção de fraude e análise de mercado. Sua capacidade de processar dados não estruturados — como artigos de notícias e relatórios de lucros — permite uma tomada de decisão mais informada.
Educação
Educadores e estudantes se beneficiam de Pensador Aberto-32B por meio de ferramentas de aprendizagem personalizadas. Ele pode gerar materiais de estudo personalizados, classificar redações com feedback contextual e até simular sessões de tutoria.
Indústrias criativas
Escritores, profissionais de marketing e designers usam Pensador Aberto-32B para fazer brainstorming de ideias, rascunhar conteúdo e criar narrativas visualmente inspiradas. Seus recursos multimodais permitem sugerir edições com base em texto e imagens que o acompanham.
Atendimento ao cliente
As empresas implantam Pensador Aberto-32B em chatbots e agentes virtuais para lidar com consultas complexas de clientes. Sua fluência em linguagem natural reduz as taxas de escalonamento e melhora a satisfação do usuário.
Tópicos relacionados:Os 3 melhores modelos de geração de música de IA de 2025
Conclusão
O Pensador Aberto-32B O modelo é mais do que apenas uma IA — é uma ferramenta transformadora que une a engenhosidade humana e a inteligência da máquina. De sua sólida base técnica a suas amplas aplicações, ele exemplifica o potencial da IA moderna para resolver desafios do mundo real. Quer você esteja procurando otimizar operações, inovar em sua área ou expandir os limites da pesquisa, Pensador Aberto-32B fornece as capacidades para fazer isso acontecer.
Com seus 32 bilhões de parâmetros trabalhando em harmonia, este modelo está pronto para liderar a carga para a próxima era da inteligência artificial. Explore o API OpenThinker-32B hoje e descubra como ele pode elevar seus projetos a novos patamares.
Como ligar Pensador Aberto-32B API do nosso CometAPI
1.Entrar para cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro
2.Obtenha a chave da API de credencial de acesso da interface. Clique em “Add Token” no token da API no centro pessoal, pegue a chave do token: sk-xxxxx e envie.
-
Obtenha a URL deste site: https://api.cometapi.com/
-
Selecione a Pensador Aberto-32B endpoint para enviar a solicitação da API e definir o corpo da solicitação. O método de solicitação e o corpo da solicitação são obtidos de nosso site API doc. Nosso site também oferece o teste Apifox para sua conveniência.
-
Processe a resposta da API para obter a resposta gerada. Após enviar a solicitação da API, você receberá um objeto JSON contendo a conclusão gerada.