

No cenário em rápida evolução da inteligência artificial, 2025 testemunhou avanços significativos em modelos de grande linguagem (LLMs). Entre os pioneiros estão o Qwen2.5 da Alibaba, os modelos V3 e R1 da DeepSeek e o ChatGPT da OpenAI. Cada um desses modelos traz recursos e inovações únicos. Este artigo analisa os desenvolvimentos mais recentes em torno do Qwen2.5, comparando seus recursos e desempenho com o DeepSeek e o ChatGPT para determinar qual modelo lidera atualmente a corrida da IA.
O que é Qwen2.5?
Visão geral
O Qwen 2.5 é o mais recente modelo de linguagem densa e de grande porte do Alibaba Cloud, disponível apenas para decodificadores, em diversos tamanhos, de 0.5B a 72B de parâmetros. Ele é otimizado para acompanhamento de instruções, saídas estruturadas (por exemplo, JSON, tabelas), codificação e resolução de problemas matemáticos. Com suporte para mais de 29 idiomas e um comprimento de contexto de até 128K tokens, o Qwen 2.5 foi projetado para aplicações multilíngues e de domínio específico.
Principais funcionalidades
- Suporte multilingue: Suporta mais de 29 idiomas, atendendo a uma base de usuários global.
- Comprimento de contexto estendido: Processa até 128 mil tokens, permitindo o processamento de documentos e conversas longas.
- Variantes Especializadas: Inclui modelos como Qwen2.5-Coder para tarefas de programação e Qwen2.5-Math para resolução de problemas matemáticos.
- Acessibilidade: Disponível em plataformas como Hugging Face, GitHub e uma interface web recém-lançada em bate-papo.qwenlm.ai.
Como usar o Qwen 2.5 localmente?
Abaixo está um guia passo a passo para o 7 B Bate-papo ponto de verificação; tamanhos maiores diferem apenas nos requisitos de GPU.
1. Pré-requisitos de hardware
| Modelo | vRAM para 8 bits | vRAM para 4 bits (QLoRA) | Tamanho do disco |
|---|---|---|---|
| Qwen 2.5‑7B | 14 GB | 10 GB | 13 GB |
| Qwen 2.5‑14B | 26 GB | 18 GB | 25 GB |
Uma única RTX 4090 (24 GB) é suficiente para inferência de 7 B com precisão total de 16 bits; duas dessas placas ou descarregamento de CPU mais quantização podem lidar com 14 B.
2. Instalação
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Script de inferência rápida
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
O trust_remote_code=True a bandeira é necessária porque Qwen envia um personalizado Encaixe de posição rotativa embrulho.
4. Ajuste fino com LoRA
Graças aos adaptadores LoRA com parâmetros eficientes, você pode treinar Qwen de forma especializada em ~50 K pares de domínios (por exemplo, médicos) em menos de quatro horas em uma única GPU de 24 GB:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
O arquivo adaptador resultante (~120 MB) pode ser mesclado novamente ou carregado sob demanda.
Opcional: Execute o Qwen 2.5 como uma API
O CometAPI atua como um hub centralizado para APIs de vários modelos líderes de IA, eliminando a necessidade de interagir com vários provedores de API separadamente. CometAPI A CometAPI oferece um preço bem menor que o preço oficial para ajudar você a integrar a API do Qwen, e você receberá US$ 1 na sua conta após se registrar e fazer login! Bem-vindo ao cadastro e à experiência do CometAPI. Para desenvolvedores que desejam incorporar o Qwen 2.5 em aplicativos:
Etapa 1: instalar as bibliotecas necessárias:
bash
pip install requests
Etapa 2: obter a chave da API
- Acessar CometAPI.
- Entre com sua conta CometAPI.
- Selecione os Painel de controle.
- Clique em “Obter chave de API” e siga as instruções para gerar sua chave.
- Implementar chamadas de API
Utilize as credenciais da API para fazer solicitações ao Qwen 2.5.Substituir com sua chave CometAPI real da sua conta.
Por exemplo, em Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Essa integração permite a incorporação perfeita dos recursos do Qwen 2.5 em vários aplicativos, aprimorando a funcionalidade e a experiência do usuário. Selecione o “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” endpoint para enviar a solicitação de API e definir o corpo da solicitação. O método e o corpo da solicitação são obtidos da documentação da API do nosso site. Nosso site também oferece o teste Apifox para sua conveniência.
Por favor, consulte Qwen 2.5 API Máxima para detalhes de integração. O CometAPI atualizou o mais recente API QwQ-32BPara obter mais informações sobre o modelo na API Comet, consulte Doc API.
Melhores práticas e dicas
| Cenário | Recomendação |
|---|---|
| Perguntas e respostas sobre documentos longos | Divida as passagens em ≤16 K tokens e use prompts de recuperação aumentados em vez de contextos ingênuos de 100 K para reduzir a latência. |
| Resultados estruturados | Prefixe a mensagem do sistema com: You are an AI that strictly outputs JSON. O treinamento de alinhamento do Qwen 2.5 se destaca na geração restrita. |
| Conclusão de código | Conjunto temperature=0.0 e top_p=1.0 para maximizar o determinismo, então amostrar múltiplos feixes (num_return_sequences=4) para classificação. |
| Filtragem de segurança | Use o pacote de regex “Qwen‑Guardrails” de código aberto do Alibaba ou o text‑moderation‑004 do OpenAI como primeira tentativa. |
Limitações conhecidas do Qwen 2.5
- Suscetibilidade imediata à injeção. Auditorias externas mostram taxas de sucesso de jailbreak de 18% no Qwen 2.5-VL — um lembrete de que o tamanho do modelo não imuniza contra instruções adversárias.
- Ruído de OCR não latino. Quando ajustado para tarefas de visão e linguagem, o pipeline de ponta a ponta do modelo às vezes confunde glifos chineses tradicionais e simplificados, exigindo camadas de correção específicas do domínio.
- Penhasco de memória da GPU em 128 K. O FlashAttention‑2 compensa a RAM, mas um encaminhamento denso de 72 B por 128 K tokens ainda exige >120 GB de vRAM; os profissionais devem usar o window-attendment ou o KV-cache.
Roteiro e ecossistema comunitário
A equipe Qwen deu a entender que Qwen 3.0, visando uma infraestrutura de roteamento híbrida (Dense + MoE) e pré-treinamento unificado de fala-visão-texto. Enquanto isso, o ecossistema já hospeda:
- Agente Q – um agente de cadeia de pensamento no estilo ReAct usando Qwen 2.5‑14B como política.
- Alpaca Financeira Chinesa – um LoRA em Qwen2.5‑7B treinado com 1 M de registros regulatórios.
- Plug-in Open Interpreter – troca GPT‑4 por um ponto de verificação Qwen local no VS Code.
Confira a página “Coleção Qwen2.5” da Hugging Face para uma lista continuamente atualizada de pontos de verificação, adaptadores e chicotes de avaliação.
Análise Comparativa: Qwen2.5 vs. DeepSeek e ChatGPT
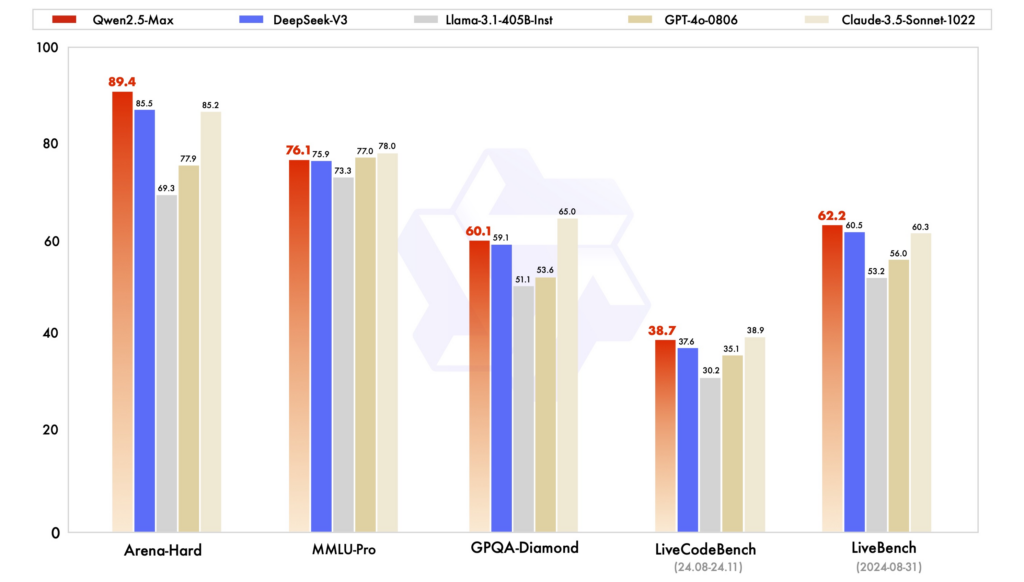
Referências de desempenho: Em diversas avaliações, o Qwen2.5 demonstrou forte desempenho em tarefas que exigem raciocínio, codificação e compreensão multilíngue. O DeepSeek-V3, com sua arquitetura MoE, destaca-se em eficiência e escalabilidade, oferecendo alto desempenho com recursos computacionais reduzidos. O ChatGPT continua sendo um modelo robusto, especialmente em tarefas de linguagem de uso geral.
Eficiência e Custo: Os modelos do DeepSeek se destacam por seu treinamento e inferência econômicos, utilizando arquiteturas MoE para ativar apenas os parâmetros necessários por token. O Qwen2.5, embora denso, oferece variantes especializadas para otimizar o desempenho de tarefas específicas. O treinamento do ChatGPT envolveu recursos computacionais substanciais, o que se refletiu em seus custos operacionais.
Acessibilidade e Disponibilidade de Código Aberto: Qwen2.5 e DeepSeek adotaram os princípios de código aberto em graus variados, com modelos disponíveis em plataformas como GitHub e Hugging Face. O lançamento recente de uma interface web pelo Qwen2.5 aprimora sua acessibilidade. O ChatGPT, embora não seja de código aberto, é amplamente acessível por meio da plataforma e das integrações do OpenAI.
Conclusão
Qwen 2.5 fica em um ponto ideal entre serviços premium de peso fechado e modelos amadores totalmente abertos. Sua combinação de licenciamento permissivo, força multilíngue, competência de longo contexto e uma ampla gama de escalas de parâmetros o torna uma base convincente tanto para pesquisa quanto para produção.
À medida que o cenário do LLM de código aberto avança, o projeto Qwen demonstra que transparência e desempenho podem coexistir. Para desenvolvedores, cientistas de dados e formuladores de políticas, dominar o Qwen 2.5 hoje é um investimento em um futuro de IA mais pluralista e favorável à inovação.