

Qwen2.5-VL-32B A API atraiu atenção por sua desempenho excepcional em diversas tarefas complexas, combinando ambos dados de imagem e texto para uma compreensão enriquecida do mundo. Desenvolvido por Alibaba, este modelo de 32 bilhões de parâmetros é uma atualização do anterior Qwen2.5-VL série, ultrapassando os limites da Raciocínio baseado em IA e compreensão visual.

Visão geral do Qwen2.5-VL-32B
Qwen2.5-VL-32B é um modelo multimodal de ponta e de código aberto projetado para lidar com uma variedade de tarefas envolvendo texto e imagens. Com seu 32 bilhões de parâmetros, oferece um arquitetura poderosa for reconhecimento de imagem, raciocínio matemático, geração de diálogo, e muito mais. Sua aprimorada capacidades de aprendizagem, com base no aprendizado por reforço, permitem gerar respostas que se alinham melhor com as preferências humanas.
Principais recursos e funções
Qwen2.5-VL-32B demonstra capacidades notáveis em vários domínios:
Compreensão e descrição de imagens:Este modelo se destaca em análise de imagem, identificando objetos e cenas com precisão. Ele pode gerar descrições detalhadas em linguagem natural e até mesmo fornecer percepções refinadas em atributos de objetos e seus relacionamentos.
Raciocínio Matemático e Lógica:O modelo está equipado para resolver problemas matemáticos complexos, que vão desde geometria para álgebra—empregando raciocínio multietapas com lógica clara e resultados estruturados.
Geração de texto e diálogo: Com seu modelo de linguagem avançado, o Qwen2.5-VL-32B gera respostas coerentes e contextualmente relevantes com base em texto de entrada ou imagens. Ele também suporta diálogo multi-turno, permitindo interações mais naturais e contínuas.
Resposta visual a perguntas: O modelo pode responder a perguntas relacionadas ao conteúdo da imagem, como Reconhecimento de objeto e descrição da cena, fornecendo lógica visual sofisticada e recursos de inferência.
Fundamentos técnicos do Qwen2.5-VL-32B
Para entender o poder por trás do Qwen2.5-VL-32B, é crucial explorar seus princípios técnicos. Abaixo estão os principais aspectos que contribuem para seu desempenho:
- Pré-treinamento multimodal:O modelo foi pré-treinado usando conjuntos de dados em grande escala consistindo de ambos dados de texto e imagem. Isso permite que ele aprenda diversas características visuais e linguísticas, facilitando a compreensão multimodal perfeita.
- Arquitetura do Transformador:Construído sobre o robusto Arquitetura do transformador, o modelo aproveita tanto o encoder e decodificador estruturas para processar entradas de imagem e texto, gerando saídas altamente precisas. mecanismo de auto-atenção permite que ele se concentre em componentes críticos dentro dos dados de entrada, aumentando sua precisão.
- Otimização de Aprendizagem por Reforço: Qwen2.5-VL-32B se beneficia do aprendizado por reforço, onde é ajustado com base no feedback humano. Este processo garante que as respostas do modelo sejam mais alinhado com as preferências humanas ao mesmo tempo que otimiza múltiplos objetivos, como precisão, lógica e fluência.
- Alinhamento visual-linguístico: Através aprendizagem contrastiva e estratégias de alinhamento, o modelo garante que ambos recursos visuais e informação textual estão devidamente integrados no espaço da linguagem, tornando-o altamente eficaz para tarefas multimodais.
Destaques de Desempenho
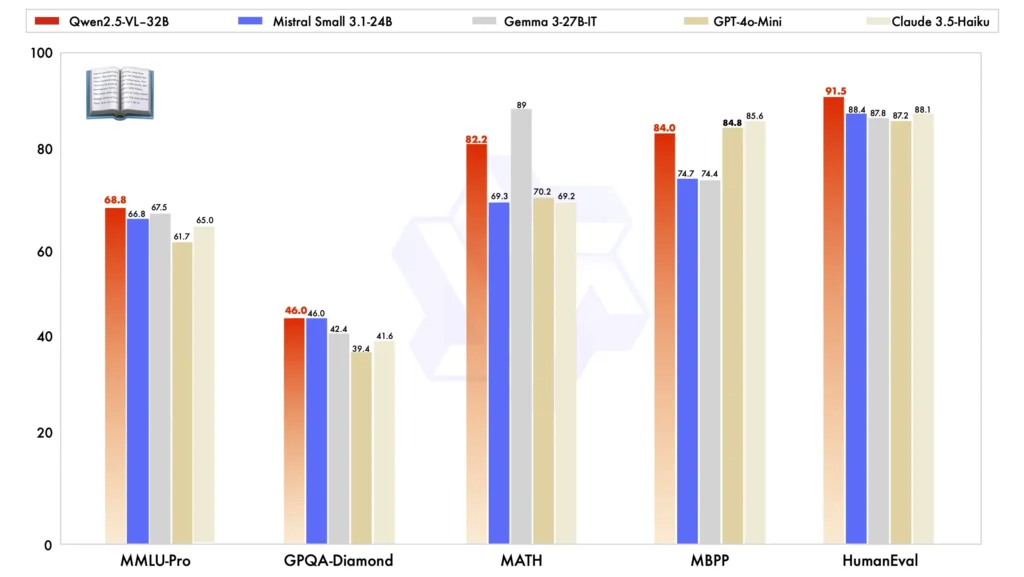
Quando comparado com outros modelos de grande porte, o Qwen2.5-VL-32B se destaca em vários benchmarks importantes, mostrando sua desempenho superior em ambos multimodal e tarefas de texto simples:
Comparação de modelos:Contra outros modelos como Mistral-Pequeno-3.1-24B e Gema-3-27B-IT, Qwen2.5-VL-32B demonstra capacidades significativamente melhoradas. Notavelmente, ele ainda supera o maior Qwen2-VL-72B em várias tarefas.
Desempenho de tarefas multimodais: Em complexo tarefas multimodais tais como MMMU, MMMU-Pro e MathVistaO Qwen2.5-VL-32B se destaca, oferecendo resultados precisos que o diferenciam de outros modelos de tamanho similar.
MM-MT-Bench Benchmark:Comparado ao seu antecessor, Qwen2-VL-72B-Instruct, a nova versão mostra uma melhoria significativa, particularmente em seu raciocínio lógico e raciocínio multimodal capacidades.
Desempenho de texto simples:Em tarefas baseadas em texto simples, Qwen2.5-VL-32B surgiu como o melhor desempenho na sua classe, oferecendo geração de texto aprimorada, raciocínio, e precisão geral.
Recursos do projeto
Para desenvolvedores e entusiastas de IA que desejam explorar mais o Qwen2.5-VL-32B, vários recursos importantes estão disponíveis:
- Website oficial: Projeto Qwen2.5-VL-32B
- Modelo HuggingFace: HuggingFace Qwen2.5-VL-32B-Instrução
Aplicações do mundo real
A versatilidade do Qwen2.5-VL-32B o torna adequado para uma ampla gama de aplicações práticas em vários setores:
Atendimento Inteligente ao Cliente: O modelo pode ser empregado para lidar automaticamente com as consultas dos clientes, aproveitando sua capacidade de entender e gerar respostas baseadas em texto e imagens.
Assistência Educacional: Resolvendo problemas matemáticos, interpretando conteúdo da imagem, e explicando conceitos, pode melhorar significativamente o processo de aprendizagem dos alunos.
Anotação de imagem:Em sistemas de gerenciamento de conteúdo, o Qwen2.5-VL-32B pode automatizar a geração de legendas da imagem e descrições, tornando-se uma ferramenta inestimável para as indústrias de mídia e criativas.
Condução Autônoma:Ao analisar sinais de trânsito e condições de tráfego por meio de seus recursos de processamento visual, o modelo pode fornecer insights em tempo real para melhorar segurança de condução.
Criação de Conteúdo:Na mídia e na publicidade, o modelo pode gerar texto com base em estímulos visuais, auxiliando criadores de conteúdo a produzir narrativas atraentes para vídeos e anúncios.
Perspectivas e desafios futuros
Embora o Qwen2.5-VL-32B represente um avanço na IA multimodal, ainda há desafios e oportunidades pela frente. Afinação o modelo para tarefas mais específicas, integrando-o com aplicações em tempo real e melhorando sua escalabilidade lidar com conjuntos de dados multimodais mais complexos são áreas que exigem pesquisa e desenvolvimento contínuos.
Além disso, à medida que mais modelos de IA são lançados com capacidades semelhantes, preocupações éticas conteúdo gerado por IA em torno, viés e privacidade de dados continuam a ganhar atenção. Garantir que o Qwen2.5-VL-32B e modelos similares sejam treinados e utilizados de forma responsável será crítico para seu sucesso a longo prazo.
Tópicos relacionados:Comparação dos 8 melhores modelos de IA mais populares de 2025
Conclusão
Qwen2.5-VL-32B é uma ferramenta poderosa no arsenal de modelos de IA projetados para lidar com tarefas multimodais com precisão e sofisticação impressionantes. Ao integrar avançados aprendizagem de reforço, arquitetura do transformador e alinhamento visual-linguagem, não só supera modelos anteriores mas também abre possibilidades interessantes para indústrias que vão desde educação para condução autônoma. Como tecnologia de código aberto, ela oferece um tremendo potencial para desenvolvedores e usuários de IA experimentarem, otimizarem e implementarem em aplicações do mundo real.
Como chamar Qwen2.5-VL-32B API do CometAPI
1.Entrar para cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro
2.Obtenha a chave da API de credencial de acesso da interface. Clique em “Add Token” no token da API no centro pessoal, pegue a chave do token: sk-xxxxx e envie.
-
Obtenha a URL deste site: https://api.cometapi.com/
-
Selecione o endpoint Qwen2.5-VL-32B para enviar a solicitação de API e defina o corpo da solicitação. O método de solicitação e o corpo da solicitação são obtidos de nosso site API doc. Nosso site também oferece o teste Apifox para sua conveniência.
-
Processe a resposta da API para obter a resposta gerada. Após enviar a solicitação da API, você receberá um objeto JSON contendo a conclusão gerada.