

O mais recente avanço da Alibaba em inteligência artificial, Codificador Qwen3, marca um marco significativo no cenário em rápida evolução do desenvolvimento de software orientado por IA. Revelado em 23 de julho de 2025, o Qwen3-Coder é um modelo de codificação agêntico de código aberto, projetado para lidar de forma autônoma com tarefas complexas de programação, desde a geração de código boilerplate até a depuração em bases de código inteiras. Construído em uma arquitetura de ponta de mistura de especialistas (MoE) e ostentando 480 bilhões de parâmetros, com 35 bilhões ativados por token, o modelo alcança um equilíbrio ideal entre desempenho e eficiência computacional. Neste artigo, exploramos o que diferencia o Qwen3-Coder, examinamos seu desempenho de referência, desvendamos suas inovações técnicas, orientamos os desenvolvedores sobre o uso ideal e consideramos a recepção e as perspectivas futuras do modelo.
O que é Qwen3‑Coder?
Qwen3‑Coder é o mais recente modelo de codificação agêntica da família Qwen, anunciado oficialmente em 22 de julho de 2025. Projetado como o "modelo de código mais agêntico até o momento", sua variante principal, Qwen3‑Coder‑480B‑A35B‑Instruct, apresenta 480 bilhões de parâmetros no total com um design de Mistura de Especialistas (MoE) que ativa 35 bilhões de parâmetros por token. Ele suporta nativamente janelas de contexto de até 256 mil tokens e escala para um milhão de tokens por meio de técnicas de extrapolação, atendendo à demanda por compreensão e geração de código em escala de repositório.
Código aberto no Apache 2.0
Mantendo o compromisso do Alibaba com o desenvolvimento orientado pela comunidade, o Qwen3-Coder é lançado sob a licença Apache 2.0. Essa disponibilidade de código aberto garante transparência, incentiva contribuições de terceiros e acelera a adoção tanto no meio acadêmico quanto na indústria. Pesquisadores e engenheiros podem acessar pesos pré-treinados e ajustar o modelo para domínios especializados, desde fintech até computação científica.
Evolução do Qwen2.5
Com base no sucesso do Qwen2.5-Coder, que oferecia modelos com parâmetros variando de 0.5 bilhão a 32 bilhões e alcançava resultados SOTA em benchmarks de geração de código, o Qwen3-Coder amplia os recursos de seu antecessor por meio de maior escala, pipelines de dados aprimorados e novos regimes de treinamento. O Qwen2.5-Coder foi treinado em mais de 5.5 trilhões de tokens com limpeza meticulosa de dados e geração de dados sintéticos; o Qwen3-Coder avança nesse quesito ao ingerir 7.5 trilhões de tokens com uma taxa de código de 70%, aproveitando modelos anteriores para filtrar e reescrever entradas ruidosas para qualidade de dados superior.
Quais são as principais inovações que diferenciam o Qwen3-Coder?
Várias inovações importantes diferenciam o Qwen3-Coder:
- Orquestração de Tarefas Agentic: Em vez de apenas gerar snippets, o Qwen3-Coder pode encadear autonomamente diversas operações — leitura de documentação, invocação de utilitários e validação de saídas — sem intervenção humana.
- Orçamento de Pensamento Aprimorado: Os desenvolvedores podem configurar a quantidade de computação dedicada a cada etapa do raciocínio, permitindo um equilíbrio personalizável entre velocidade e rigor, o que é crucial para a síntese de código em larga escala.
- Integração perfeita de ferramentas: A interface de linha de comando do Qwen3-Coder, “Qwen Code”, adapta protocolos de chamada de função e prompts personalizados para integração com ferramentas populares para desenvolvedores, facilitando a incorporação em pipelines de CI/CD e IDEs existentes.
Como o Qwen3‑Coder se sai em comparação aos concorrentes?
Confrontos de referência
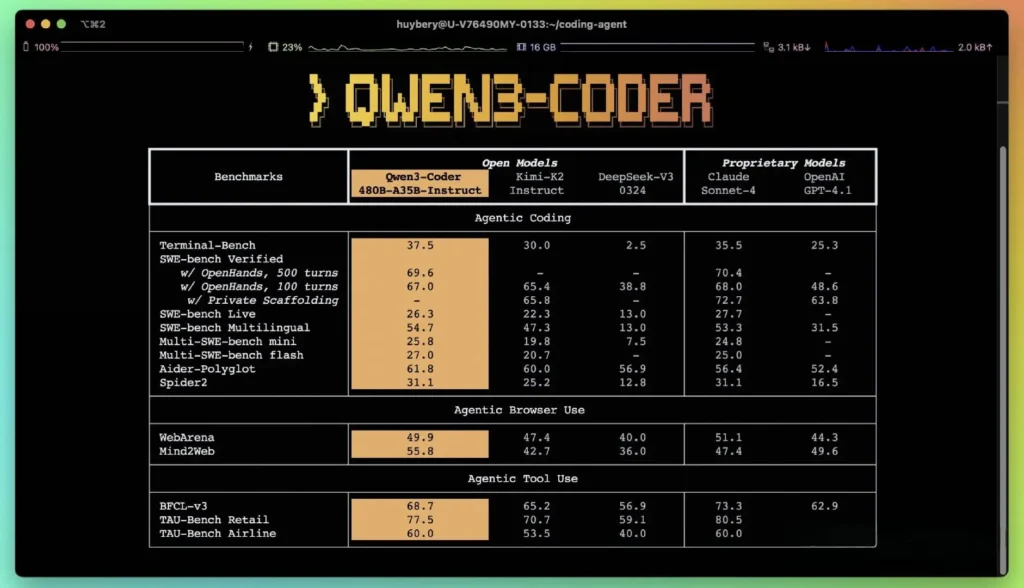
De acordo com as métricas de desempenho publicadas pelo Alibaba, o Qwen3-Coder supera as principais alternativas nacionais — como os modelos estilo códice da DeepSeek e o K2 da Moonshot AI — e iguala ou excede as capacidades de codificação das principais ofertas americanas em diversos benchmarks. Em avaliações de terceiros:
- Aider Poliglota: Qwen3-Coder-480B obteve uma pontuação de 61.8%, ilustrando forte geração de código multilíngue e raciocínio.
- MBPP e HumanEval: Testes independentes relatam que o Qwen3-Coder-480B-A35B supera o GPT-4.1 tanto em correção funcional quanto em tratamento de prompts complexos, especialmente em desafios de codificação de várias etapas.
- A variante do parâmetro 480B obteve mais de 85% de sucesso na execução Banco SWE Suíte verificada — superando o modelo principal da DeepSeek (78%) e o K2 da Moonshot (82%), e se aproximando do Claude Sonnet 4 com 86%.
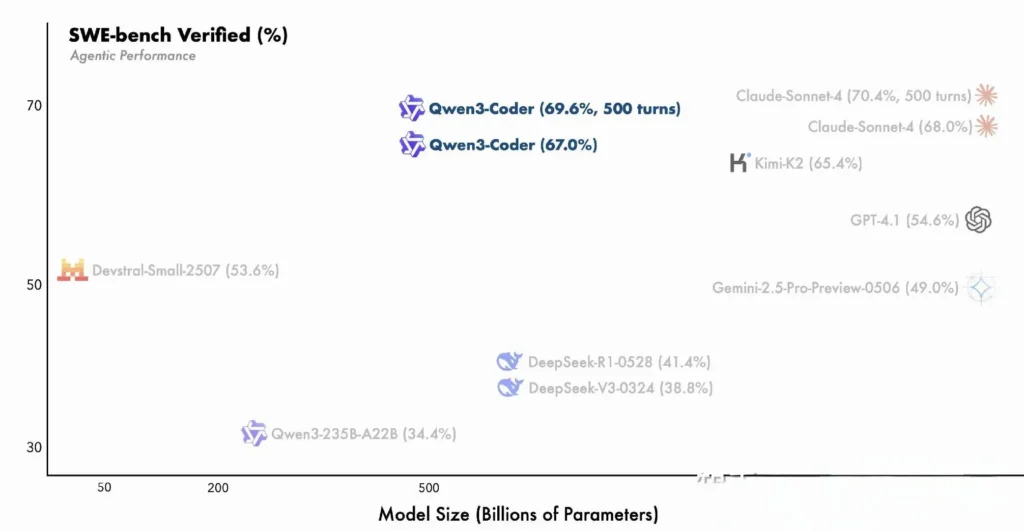
Comparação com modelos proprietários
A Alibaba afirma que os recursos agênticos do Qwen3-Coder se alinham com o Claude da Anthropic e o GPT-4 da OpenAI em fluxos de trabalho de codificação de ponta a ponta, um feito notável para um modelo de código aberto. Os primeiros testadores relatam que seu planejamento multi-turno, invocação dinâmica de ferramentas e correção automatizada de erros podem lidar com tarefas complexas — como a construção de aplicações web full-stack ou a integração de pipelines de CI/CD — com o mínimo de solicitações humanas. Esses recursos são reforçados pela capacidade do modelo de se autovalidar por meio da execução de código, um recurso menos pronunciado em LLMs puramente generativos.
Quais são as inovações técnicas por trás do Qwen3‑Coder?
Arquitetura de mistura de especialistas (MoE)
No coração do Qwen3‑Coder está um design MoE de última geração. Ao contrário dos modelos densos que ativam todos os parâmetros para cada token, as arquiteturas MoE envolvem seletivamente sub-redes especializadas (especialistas) adaptadas a tipos de token ou tarefas específicas. No Qwen3‑Coder, 480 bilhões de parâmetros no total são distribuídos entre vários especialistas, com apenas 35 bilhões de parâmetros ativos por token. Essa abordagem reduz os custos de inferência em mais de 60% em comparação com modelos densos equivalentes, mantendo alta fidelidade na síntese e depuração do código.
Modo de pensar e modo de não pensar
Tomando emprestado as inovações da família Qwen3 mais ampla, o Qwen3‑Coder integra um inferência de modo duplo estrutura:
- Modo de Pensamento aloca um “orçamento de pensamento” maior para tarefas de raciocínio complexas e de várias etapas, como design de algoritmos ou refatoração entre arquivos.
- Modo Não Pensante fornece respostas rápidas e orientadas ao contexto, adequadas para conclusões de código simples e trechos de uso de API.
Essa alternância de modo unificada elimina a necessidade de manipular modelos separados para tarefas otimizadas para bate-papo e tarefas otimizadas para raciocínio, simplificando os fluxos de trabalho do desenvolvedor.
Aprendizado por Reforço com Síntese Automatizada de Casos de Teste
Uma inovação de destaque é a janela de contexto nativa de 3K tokens do Qwen256-Coder — o dobro da capacidade típica dos principais modelos abertos — e o suporte para até um milhão de tokens por meio de métodos de extrapolação (por exemplo, YaRN). Isso permite que o modelo processe repositórios inteiros, conjuntos de documentação ou projetos com vários arquivos em uma única passagem, preservando dependências entre arquivos e reduzindo prompts repetitivos. Testes empíricos mostram que a expansão da janela de contexto produz ganhos decrescentes, mas ainda significativos, no desempenho de tarefas de longo prazo, especialmente em cenários de aprendizado por reforço orientados pelo ambiente.
Como os desenvolvedores podem acessar e usar o Qwen3‑Coder?
A estratégia de lançamento do Qwen3-Coder enfatiza a abertura e a facilidade de adoção:
- Pesos de modelos de código aberto: Todos os pontos de verificação do modelo estão disponíveis no GitHub no Apache 2.0, permitindo total transparência e melhorias conduzidas pela comunidade.
- Interface de linha de comando (código Qwen): Bifurcado do Google Gemini Code, o CLI oferece suporte a prompts personalizados, chamadas de função e arquiteturas de plug-in para integração perfeita com sistemas de compilação e IDEs existentes.
- Implantações em nuvem e no local: Imagens Docker pré-configuradas e gráficos Kubernetes Helm facilitam implantações escaláveis em ambientes de nuvem, enquanto receitas de quantização local (quantização dinâmica de 2 a 8 bits) permitem inferência eficiente no local, mesmo em GPUs comuns.
- Acesso à API via CometAPI: Os desenvolvedores também podem interagir com o Qwen3-Coder por meio de endpoints hospedados em plataformas como CometAPI, que oferecem código aberto(
qwen3-coder-480b-a35b-instruct) e versões comerciais(qwen3-coder-plus; qwen3-coder-plus-2025-07-22)pelo mesmo preço.A versão comercial tem 1M de comprimento. - Abraçando o rosto:Alibaba disponibilizou gratuitamente os pesos do Qwen3‑Coder e as bibliotecas que os acompanham no Hugging Face e no GitHub, empacotados sob uma licença Apache 2.0 que permite uso acadêmico e comercial sem royalties.
Integração de API e SDK via CometAPI
A CometAPI é uma plataforma de API unificada que agrega mais de 500 modelos de IA de provedores líderes — como a série GPT da OpenAI, a Gemini do Google, a Claude da Anthropic, a Midjourney e a Suno, entre outros — em uma interface única e amigável ao desenvolvedor. Ao oferecer autenticação, formatação de solicitações e tratamento de respostas consistentes, a CometAPI simplifica drasticamente a integração de recursos de IA em seus aplicativos. Seja para criar chatbots, geradores de imagens, compositores musicais ou pipelines de análise baseados em dados, a CometAPI permite iterar mais rapidamente, controlar custos e permanecer independente de fornecedores — tudo isso enquanto aproveita os avanços mais recentes em todo o ecossistema de IA.
Os desenvolvedores podem interagir com Codificador Qwen3 por meio de uma API compatível com o estilo OpenAI, disponível via CometAPI. CometAPI, que oferecem código aberto(qwen3-coder-480b-a35b-instruct) e versões comerciais(qwen3-coder-plus; qwen3-coder-plus-2025-07-22) pelo mesmo preço. A versão comercial tem 1 milhão de caracteres. Código de exemplo para Python (usando o cliente compatível com OpenAI) com as melhores práticas que recomendam configurações de amostragem de temperatura = 0.7, top_p = 0.8, top_k = 20 e repeat_penalty = 1.05. Os comprimentos de saída podem chegar a 65,536 tokens, tornando-o adequado para grandes tarefas de geração de código.
Para começar, explore as capacidades dos modelos no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API.
Início rápido sobre Hugging Face e Alibaba Cloud
Os desenvolvedores ansiosos para experimentar o Qwen3‑Coder podem encontrar o modelo no Hugging Face no repositório Qwen/Qwen3‑Coder‑480B‑A35B‑Instruct. A integração é simplificada através do transformers biblioteca (versão ≥ 4.51.0 para evitar KeyError: 'qwen3_moe') e clientes Python compatíveis com OpenAI. Um exemplo mínimo:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen3-480B-A35B-Instruct")
input_ids = tokenizer("def fibonacci(n):", return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, temperature=0.7, top_p=0.8, top_k=20, repetition_penalty=1.05)
print(tokenizer.decode(output))
Definindo ferramentas personalizadas e fluxos de trabalho de agência
Um dos recursos de destaque do Qwen3‑Coder é invocação de ferramenta dinâmicaOs desenvolvedores podem registrar utilitários externos — linters, formatadores, executores de testes — e permitir que o modelo os chame de forma autônoma durante uma sessão de codificação. Esse recurso transforma o Qwen3-Coder de um assistente de código passivo em um agente de codificação ativo, capaz de executar testes, ajustar o estilo do código e até mesmo implantar microsserviços com base em intenções conversacionais.
Quais aplicações potenciais e direções futuras são possibilitadas pelo Qwen3‑Coder?
Ao combinar a liberdade do código aberto com o desempenho de nível empresarial, o Qwen3-Coder abre caminho para uma nova geração de ferramentas de desenvolvimento orientadas por IA. De auditorias automatizadas de código e verificações de conformidade de segurança a serviços de refatoração contínua e assistentes de desenvolvimento com tecnologia de IA, a versatilidade do modelo já inspira startups e equipes internas de inovação.
Fluxos de trabalho de desenvolvimento de software
Os primeiros usuários relatam uma redução de 30% a 50% no tempo gasto com codificação boilerplate, gerenciamento de dependências e estruturação inicial, permitindo que os engenheiros se concentrem em tarefas de design e arquitetura de alto valor. Suítes de integração contínua podem utilizar o Qwen3-Coder para gerar testes automaticamente, detectar regressões e até mesmo sugerir otimizações de desempenho com base na análise de código em tempo real.
Empresas jogam
À medida que empresas dos setores financeiro, de saúde e de e-commerce integram o Qwen3-Coder em sistemas de missão crítica, os ciclos de feedback entre as equipes de usuários e o departamento de P&D do Alibaba acelerarão os refinamentos, como ajustes específicos de domínio, protocolos de segurança aprimorados e plugins de IDE mais rigorosos. Além disso, a estratégia de código aberto do Alibaba incentiva contribuições da comunidade global, fomentando um ecossistema vibrante de extensões, benchmarks e bibliotecas de melhores práticas.
Conclusão
Em resumo, o Qwen3-Coder representa um marco na IA de código aberto para engenharia de software: um modelo poderoso e ágil que não apenas escreve código, mas também orquestra pipelines inteiros de desenvolvimento com mínima supervisão humana. Ao tornar a tecnologia disponível gratuitamente e fácil de integrar, o Alibaba está democratizando o acesso a ferramentas avançadas de IA e preparando o cenário para uma era em que a criação de software se tornará cada vez mais colaborativa, eficiente e inteligente.
Perguntas Frequentes
O que torna o Qwen3‑Coder “agente”?
IA agêntica refere-se a modelos que podem planejar e executar tarefas multietapas de forma autônoma. A capacidade do Qwen3-Coder de invocar ferramentas externas, executar testes e gerenciar bases de código sem intervenção humana exemplifica esse paradigma.
O Qwen3‑Coder é adequado para uso em produção?
Embora o Qwen3‑Coder mostre um forte desempenho em benchmarks e testes do mundo real, as empresas devem conduzir avaliações específicas de domínio e implementar proteções (por exemplo, pipelines de verificação de saída) antes de integrá-lo em fluxos de trabalho de produção críticos.
Como a arquitetura Mixture‑of‑Experts beneficia os desenvolvedores?
O MoE reduz os custos de inferência ativando apenas sub-redes relevantes por token, permitindo uma geração mais rápida e menores custos computacionais. Essa eficiência é crucial para escalar assistentes de codificação de IA em ambientes de nuvem.