
Qwen3-Max-Preview é o mais recente modelo de pré-visualização da Alibaba na família Qwen3 — um modelo estilo Mixture-of-Experts (MoE) com mais de um trilhão de parâmetros e uma janela de contexto de token ultralonga de 262 mil, lançado em pré-visualização para uso corporativo/na nuvem. Ele tem como alvo *raciocínio profundo, compreensão de documentos longos, codificação e fluxos de trabalho de agência.
Informações básicas e recursos do título
- Nome / Rótulo:
qwen3-max-preview(Instruir). - Escala: Mais de 1 trilhão de parâmetros (alcance de trilhão de parâmetros). Este é o principal marco de marketing/estatística para o lançamento.
- Janela de contexto: Tokens 262,144 (suporta entradas muito longas e transcrições de vários arquivos).
- Modo (s): Variante “Instruct” ajustada por instrução com suporte para pensando (cadeia de pensamento deliberada) e não-pensante modos rápidos na família Qwen3.
- Disponibilidade: Acesso de pré-visualização via Bate-papo Qwen, Estúdio de modelo de nuvem Alibaba (pontos de extremidade compatíveis com OpenAI ou DashScope) e provedores de roteamento como CometAPI.
Detalhes técnicos (arquitetura e modos)
- Arquitetura: O Qwen3-Max segue a linhagem de design do Qwen3 que usa uma mistura de denso + Mistura de Especialistas (MoE) componentes em variantes maiores, além de opções de engenharia para otimizar a eficiência de inferência para contagens de parâmetros muito grandes.
- Modo de pensar vs modo de não pensar: A série Qwen3 introduziu um modo de pensar (para saídas de estilo de cadeia de pensamento de várias etapas) e modo não pensante para respostas mais rápidas e concisas; a plataforma expõe parâmetros para alternar esses comportamentos.
- Recursos de cache de contexto/desempenho: Listas de estúdio de modelos cache de contexto suporte para grandes solicitações para reduzir custos de entrada repetidos e melhorar o rendimento em contextos repetidos.
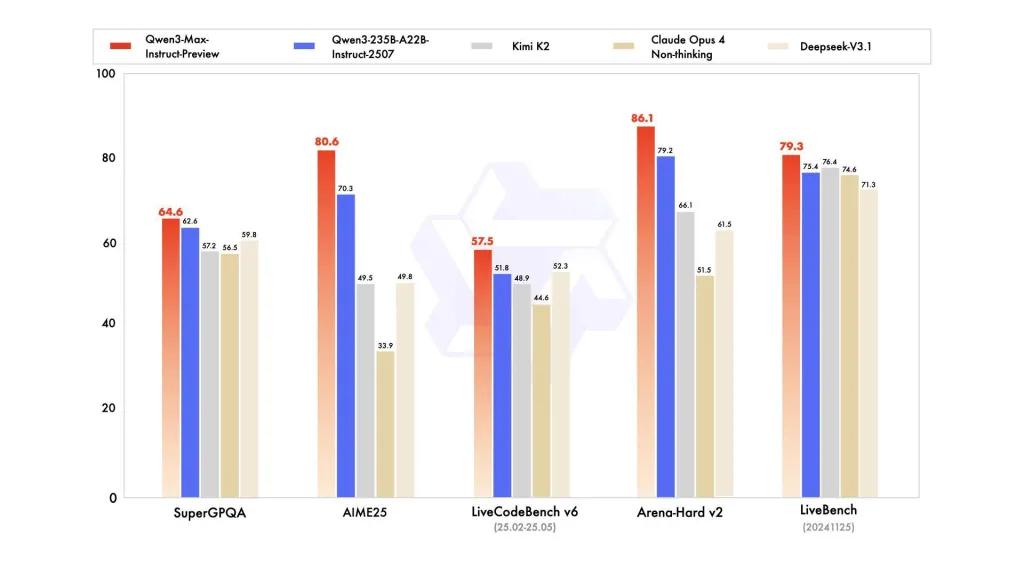
Desempenho de referência
relatórios fazem referência a variantes do SuperGPQA, LiveCodeBench, AIME25 e outros conjuntos de concursos/benchmarks onde o Qwen3-Max parece competitivo ou líder.
Limitações e riscos (notas práticas e de segurança)
- Opacidade para receita de treinamento completo/pesos: Como prévia, o lançamento completo de treinamento/dados/peso e os materiais de reprodutibilidade podem ser limitados em comparação com as versões anteriores do Qwen3 com peso aberto. Alguns modelos da família Qwen3 foram lançados com peso aberto, mas o Qwen3-Max está sendo entregue como uma prévia controlada para acesso à nuvem. reduz a reprodutibilidade para pesquisadores independentes.
- Alucinações e factualidade: Relatórios de fornecedores afirmam reduções nas alucinações, mas o uso no mundo real ainda encontrará erros factuais e afirmações excessivamente confiantes — aplicam-se as ressalvas padrão do LLM. Uma avaliação independente é necessária antes de uma implementação de alto risco.
- Custo em escala: Com uma enorme janela de contexto e alta capacidade, custos simbólicos pode ser substancial para prompts muito longos ou para produtividade de produção. Use cache, fragmentação e controles de orçamento.
- Considerações sobre regulamentação e soberania de dados: Usuários corporativos devem verificar as regiões, a residência de dados e as implicações de conformidade do Alibaba Cloud antes de processar informações confidenciais. (A documentação do Model Studio inclui pontos de extremidade e notas específicos da região.)
Os casos de uso
- Compreensão/resumo de documentos em escala: resumos jurídicos, especificações técnicas e bases de conhecimento multiarquivo (benefício: Token 262K janela).
- Raciocínio de código de contexto longo e assistência de código em escala de repositório: compreensão de código de vários arquivos, grandes revisões de RP, sugestões de refatoração em nível de repositório.
- Tarefas complexas de raciocínio e cadeia de pensamento: competições de matemática, planejamento em várias etapas, fluxos de trabalho agênticos onde rastros de “pensamento” ajudam na rastreabilidade.
- Perguntas e respostas empresariais multilíngues e extração de dados estruturados: grandes corpora multilíngues suportam e recursos de saída estruturados (JSON / tabelas).
Como chamar a API Qqwen3-max-preview do CometAPI
qwen3-max-preview Preços da API no CometAPI, 20% de desconto sobre o preço oficial:
| Tokens de entrada | $0.24 |
| Tokens de saída | $2.42 |
Etapas Necessárias
- Faça o login no cometapi.com. Se você ainda não é nosso usuário, registre-se primeiro
- Obtenha a chave de API da credencial de acesso da interface. Clique em "Adicionar Token" no token da API no centro pessoal, obtenha a chave de token: sk-xxxxx e envie.
- Obtenha a URL deste site: https://api.cometapi.com/
Use o método
- Selecione o endpoint “qwen3-max-preview” para enviar a solicitação de API e definir o corpo da solicitação. O método e o corpo da solicitação são obtidos na documentação da API do nosso site. Nosso site também oferece o teste Apifox para sua conveniência.
- Substituir com sua chave CometAPI real da sua conta.
- Insira sua pergunta ou solicitação no campo de conteúdo — é a isso que o modelo responderá.
- . Processe a resposta da API para obter a resposta gerada.
Chamada de API
A CometAPI fornece uma API REST totalmente compatível — para uma migração perfeita. Detalhes importantes para Doc API:
- Parâmetros principais:
prompt,max_tokens_to_sample,temperature,stop_sequences - Endpoint:
https://api.cometapi.com/v1/chat/completions - Parâmetro do modelo: qwen3-max-prévia
- Autenticação:
Bearer YOUR_CometAPI_API_KEY - Tipo de conteúdo:
application/json.
Substituir
CometAPI_API_KEYcom sua chave; observe o URL base.
Python (solicitações) — compatível com OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Dica: usar max_input_tokens, max_output_tokens, e Model Studio's cache de contexto recursos ao enviar contextos muito grandes para controlar custos e produtividade.
Veja também Codificador Qwen3