

Em 19–20 de novembro de 2025, a OpenAI lançou duas atualizações relacionadas, porém distintas: GPT-5.1-Codex-Max, um novo modelo de codificação agêntico para o Codex que enfatiza codificação de longo horizonte, eficiência de tokens e “compactação” para sustentar sessões com várias janelas; e GPT-5.1 Pro, um modelo ChatGPT da camada Pro atualizado e ajustado para respostas mais claras e mais capazes em trabalhos complexos e profissionais.
O que é o GPT-5.1-Codex-Max e qual problema ele busca resolver?
GPT-5.1-Codex-Max é um modelo Codex especializado da OpenAI, ajustado para fluxos de trabalho de programação que exigem raciocínio e execução sustentados de longo horizonte. Onde modelos comuns podem tropeçar em contextos extremamente longos — por exemplo, refatorações multi-arquivo, loops de agentes complexos ou tarefas persistentes de CI/CD — o Codex-Max foi projetado para compactar e gerenciar automaticamente o estado da sessão em várias janelas de contexto, permitindo que continue trabalhando de forma coerente à medida que um projeto se estende por milhares (ou mais) de tokens. A OpenAI posiciona o Codex-Max como o próximo passo para tornar agentes capazes de código realmente úteis para trabalhos de engenharia estendidos.
O que é o GPT-5.1-Codex-Max e qual problema ele busca resolver?
GPT-5.1-Codex-Max é um modelo Codex especializado da OpenAI, ajustado para fluxos de trabalho de programação que exigem raciocínio e execução sustentados de longo horizonte. Onde modelos comuns podem tropeçar em contextos extremamente longos — por exemplo, refatorações multi-arquivo, loops de agentes complexos ou tarefas persistentes de CI/CD — o Codex-Max foi projetado para compactar e gerenciar automaticamente o estado da sessão em várias janelas de contexto, permitindo que continue trabalhando de forma coerente à medida que um projeto se estende por muitos milhares (ou mais) de tokens.
Ele é descrito pela OpenAI como “mais rápido, mais inteligente e mais eficiente em tokens em todas as etapas do ciclo de desenvolvimento” e é explicitamente destinado a substituir o GPT-5.1-Codex como o modelo padrão nas superfícies do Codex.
Instantâneo de recursos
- Compactação para continuidade entre janelas: poda e preserva o contexto crítico para trabalhar de forma coerente ao longo de milhões de tokens e horas. 0
- Eficiência de tokens aprimorada em comparação ao GPT-5.1-Codex: até ~30% menos tokens de “pensamento” para esforço de raciocínio semelhante em alguns benchmarks de código.
- Durabilidade agêntica de longo horizonte: observado internamente sustentando loops de agentes por várias horas/dias (a OpenAI documentou execuções internas >24 horas).
- Integrações de plataforma: disponível hoje no CLI do Codex, extensões de IDE, nuvem e ferramentas de revisão de código; acesso via API a ser disponibilizado.
- Suporte ao ambiente Windows: a OpenAI observa especificamente que o Windows é suportado pela primeira vez nos fluxos de trabalho do Codex, ampliando o alcance real para desenvolvedores.
Como ele se compara a produtos concorrentes (por exemplo, GitHub Copilot, outras IAs de codificação)?
O GPT-5.1-Codex-Max é apresentado como um colaborador mais autônomo e de longo horizonte em comparação com ferramentas de autocompletar por requisição. Enquanto o Copilot e assistentes semelhantes se destacam em conclusões de curto prazo dentro do editor, os pontos fortes do Codex-Max estão em orquestrar tarefas de múltiplas etapas, manter estado coerente entre sessões e lidar com fluxos de trabalho que exigem planejamento, testes e iteração. Dito isso, a melhor abordagem na maioria das equipes será híbrida: use o Codex-Max para automação complexa e tarefas agênticas sustentadas e use assistentes mais leves para conclusões em nível de linha.
Como o GPT-5.1-Codex-Max funciona?
O que é “compactação” e como ela permite trabalho de longa duração?
Um avanço técnico central é a compactação — um mecanismo interno que poda o histórico da sessão enquanto preserva as partes salientes do contexto para que o modelo possa continuar um trabalho coerente em múltiplas janelas de contexto. Na prática, isso significa que sessões do Codex que se aproximam do limite de contexto serão compactadas (tokens mais antigos ou de menor valor são resumidos/preservados) para que o agente tenha uma janela nova e possa continuar iterando repetidamente até a conclusão da tarefa. A OpenAI relata execuções internas nas quais o modelo trabalhou em tarefas continuamente por mais de 24 horas.
Raciocínio adaptativo e eficiência de tokens
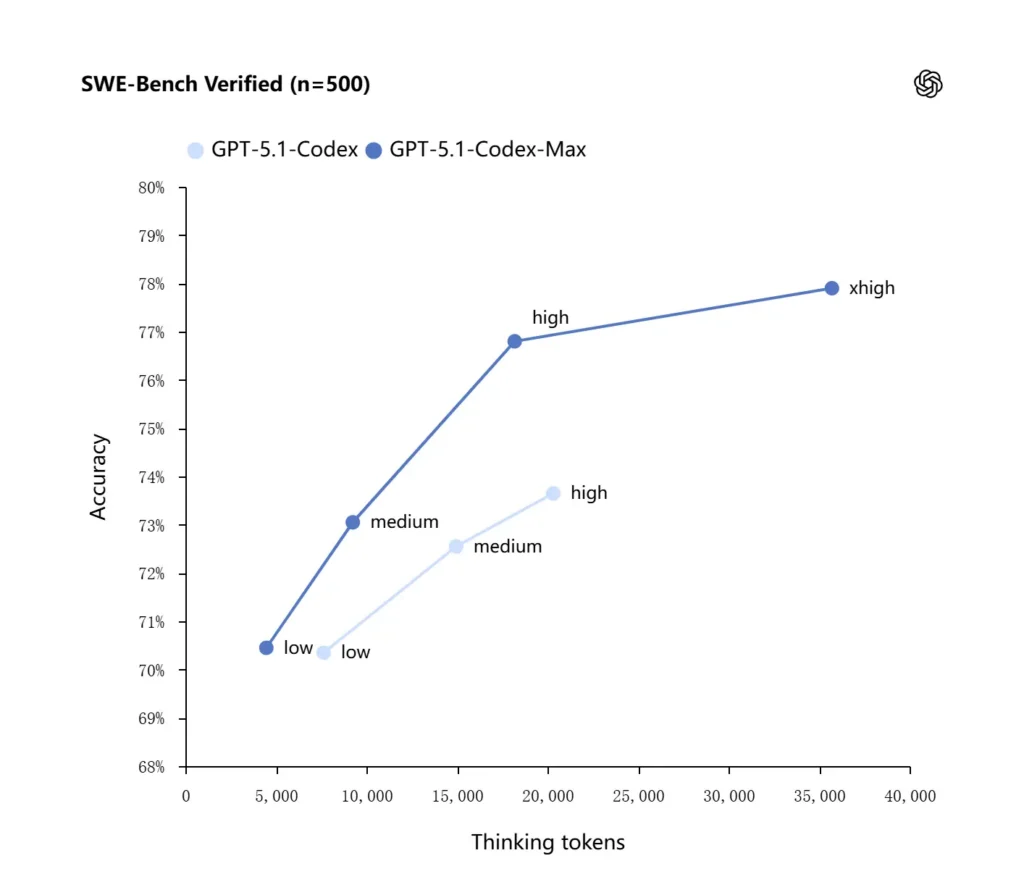
O GPT-5.1-Codex-Max aplica estratégias de raciocínio aprimoradas que o tornam mais eficiente em tokens: em benchmarks internos relatados pela OpenAI, o modelo Max atinge desempenho igual ou melhor do que o GPT-5.1-Codex enquanto usa significativamente menos tokens de “pensamento” — a OpenAI cita cerca de 30% menos tokens de pensamento no SWE-bench Verified quando executado com esforço de raciocínio igual. O modelo também introduz um modo de esforço de raciocínio “Extra High (xhigh)” para tarefas não sensíveis à latência que permite despender mais raciocínio interno para obter saídas de maior qualidade.
Integrações de sistema e ferramentas agênticas
O Codex-Max está sendo distribuído nos fluxos de trabalho do Codex (CLI, extensões de IDE, nuvem e superfícies de revisão de código) para que possa interagir com as ferramentas reais do desenvolvedor. As integrações iniciais incluem o CLI do Codex e agentes de IDE (VS Code, JetBrains, etc.), com acesso via API planejado para seguir. O objetivo de design não é apenas síntese de código mais inteligente, mas uma IA que possa executar fluxos de trabalho de múltiplas etapas: abrir arquivos, executar testes, corrigir falhas, refatorar e executar novamente.
Como o GPT-5.1-Codex-Max se sai em benchmarks e no trabalho real?
Raciocínio sustentado e tarefas de longo horizonte
As avaliações apontam melhorias mensuráveis em raciocínio sustentado e tarefas de longo horizonte:
- Avaliações internas da OpenAI: o Codex-Max pode trabalhar em tarefas por “mais de 24 horas” em experimentos internos e a integração do Codex com ferramentas de desenvolvedor aumentou métricas internas de produtividade de engenharia (por exemplo, uso e throughput de pull requests). São alegações internas da OpenAI e indicam melhorias em nível de tarefa na produtividade do mundo real.
- Avaliações independentes (METR): o relatório independente do METR mediu o horizonte de tempo observado de 50% (uma estatística que representa o tempo mediano que o modelo consegue sustentar de forma coerente uma tarefa longa) para o GPT-5.1-Codex-Max em cerca de 2 horas e 40 minutos (com um amplo intervalo de confiança), acima das 2 horas e 17 minutos do GPT-5 em medições comparáveis — uma melhoria significativa na coerência sustentada. A metodologia e o CI do METR enfatizam a variabilidade, mas o resultado apoia a narrativa de que o Codex-Max melhora o desempenho prático de longo horizonte.
Benchmarks de código
A OpenAI relata resultados aprimorados em avaliações de ponta de codificação, notadamente o SWE-bench Verified, onde o GPT-5.1-Codex-Max supera o GPT-5.1-Codex com melhor eficiência de tokens. A empresa destaca que, para o mesmo esforço de raciocínio “medium”, o modelo Max produz melhores resultados ao usar cerca de 30% menos tokens de pensamento; para usuários que permitem raciocínio interno mais longo, o modo xhigh pode elevar ainda mais as respostas ao custo de latência.
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73,7% | 77,9% |
| SWE-Lancer IC SWE | 66,3% | 79,9% |
| Terminal-Bench 2.0 | 52,8% | 58,1% |
Como o GPT-5.1-Codex-Max se compara ao GPT-5.1-Codex?
Diferenças de desempenho e propósito
- Escopo: o GPT-5.1-Codex era uma variante de alto desempenho da família GPT-5.1 voltada para codificação; o Codex-Max é explicitamente um sucessor agêntico de longo horizonte, destinado a ser o padrão recomendado para o Codex e ambientes semelhantes.
- Eficiência de tokens: o Codex-Max apresenta ganhos materiais de eficiência de tokens (a alegação de ~30% menos tokens de pensamento da OpenAI) no SWE-bench e no uso interno.
- Gerenciamento de contexto: o Codex-Max introduz compactação e manipulação nativa de múltiplas janelas para sustentar tarefas que excedem uma única janela de contexto; o Codex não fornecia essa capacidade de forma nativa na mesma escala.
- Prontidão de ferramentas: o Codex-Max é fornecido como o modelo padrão do Codex no CLI, IDE e superfícies de revisão de código, sinalizando uma migração para fluxos de trabalho de desenvolvedor em produção.
Quando usar qual modelo?
- Use GPT-5.1-Codex para assistência interativa de codificação, edições rápidas, pequenas refatorações e casos de menor latência em que todo o contexto relevante cabe facilmente em uma única janela.
- Use GPT-5.1-Codex-Max para refatorações multi-arquivo, tarefas agênticas automatizadas que exigem muitos ciclos de iteração, fluxos de trabalho tipo CI/CD ou quando você precisa que o modelo mantenha uma perspectiva em nível de projeto ao longo de muitas interações.
Padrões práticos de prompts e exemplos para melhores resultados
Padrões de prompting que funcionam bem
- Seja explícito sobre objetivos e restrições: “Refatorar X, preservar a API pública, manter nomes de funções e garantir que os testes A, B, C passem.”
- Forneça um contexto mínimo reprodutível: vincule ao teste com falha, inclua rastros de pilha e trechos de arquivos relevantes em vez de despejar repositórios inteiros. O Codex-Max compactará o histórico conforme necessário.
- Use instruções passo a passo para tarefas complexas: divida trabalhos grandes em uma sequência de subtarefas e deixe o Codex-Max iterar sobre elas (por exemplo, “1) executar os testes 2) corrigir os 3 principais testes com falha 3) executar o linter 4) resumir as mudanças”).
- Peça explicações e diffs: solicite o patch e uma breve justificativa para que revisores humanos possam avaliar rapidamente segurança e intenção.
Modelos de prompt de exemplo
Tarefa de refatoração
“Refatorar o
payment/para extrair o processamento de pagamentos empayment/processor.py. Manter estáveis as assinaturas de funções públicas para os chamadores existentes. Criar testes de unidade paraprocess_payment()que cubram sucesso, falha de rede e cartão inválido. Executar a suíte de testes e retornar testes com falha e um patch em formato diff unificado.”
Correção de bug + teste
“Um teste
tests/test_user_auth.py::test_token_refreshfalha com traceback. Investigue a causa raiz, proponha uma correção com mudanças mínimas e adicione um teste de unidade para evitar regressão. Aplique o patch e execute os testes.”
Geração iterativa de PR
“Implementar a funcionalidade X: adicionar o endpoint
POST /api/export, que transmite resultados de exportação e é autenticado. Criar o endpoint, adicionar documentação, criar testes e abrir um PR com resumo e checklist de itens manuais.”
Para a maioria desses casos, comece com medium; mude para xhigh quando você precisar que o modelo faça raciocínio profundo em muitos arquivos e várias iterações de teste.
Como acessar o GPT-5.1-Codex-Max
Onde está disponível hoje
A OpenAI integrou o GPT-5.1-Codex-Max nas ferramentas do Codex hoje: o CLI do Codex, extensões de IDE, nuvem e fluxos de revisão de código usam o Codex-Max por padrão (você pode optar pelo Codex-Mini). A disponibilidade da API está por vir; o GitHub Copilot tem prévias públicas que incluem modelos GPT-5.1 e da série Codex.
Os desenvolvedores podem acessar o GPT-5.1-Codex-Max e a GPT-5.1-Codex API por meio da CometAPI. Para começar, explore os recursos de modelo da CometAPI no Playground e consulte o guia da API para instruções detalhadas. Antes de acessar, certifique-se de ter feito login na CometAPI e obtido a chave de API. A CometAPI oferece um preço muito inferior ao preço oficial para ajudar você a integrar.
Pronto para começar?→ Inscreva-se na CometAPI hoje!
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos no VK, X e Discord!
Início rápido (passo a passo prático)
- Certifique-se de ter acesso: confirme se seu plano de produto ChatGPT/Codex (Plus, Pro, Business, Edu, Enterprise) ou seu plano de API para desenvolvedores oferece suporte aos modelos da família GPT-5.1/Codex.
- Instale o CLI do Codex ou a extensão de IDE: se quiser executar tarefas de código localmente, instale o CLI do Codex ou a extensão de IDE do Codex para VS Code / JetBrains / Xcode, conforme aplicável. As ferramentas usarão o GPT-5.1-Codex-Max por padrão em configurações compatíveis.
- Escolha o esforço de raciocínio: comece com medium para a maioria das tarefas. Para depuração profunda, refatorações complexas ou quando você quer que o modelo “pense” mais e não se preocupa com a latência de resposta, mude para os modos high ou xhigh. Para correções pequenas rápidas, low é razoável.
- Forneça o contexto do repositório: dê ao modelo um ponto de partida claro — uma URL do repositório ou um conjunto de arquivos e uma instrução curta (por exemplo, “refatorar o módulo de pagamento para usar I/O assíncrono e adicionar testes de unidade, manter os contratos em nível de função”). O Codex-Max compactará o histórico à medida que se aproximar dos limites de contexto e continuará o trabalho.
- Itere com testes: depois que o modelo produzir patches, execute as suítes de teste e retorne as falhas como parte da sessão contínua. A compactação e a continuidade entre janelas permitem que o Codex-Max retenha o contexto importante de testes com falha e itere.
Conclusão:
O GPT-5.1-Codex-Max representa um passo substancial em direção a assistentes de codificação agênticos que podem sustentar tarefas de engenharia complexas e de longa duração com eficiência e raciocínio aprimorados. Os avanços técnicos (compactação, modos de esforço de raciocínio, treinamento em ambiente Windows) o tornam excepcionalmente adequado para organizações de engenharia modernas — desde que as equipes emparelhem o modelo com controles operacionais conservadores, políticas claras de humanos no loop e monitoramento robusto. Para equipes que o adotarem com cuidado, o Codex-Max tem o potencial de mudar como o software é projetado, testado e mantido — transformando o trabalho repetitivo de engenharia em uma colaboração de maior valor entre humanos e modelos.