

Gemini Embedding 2 é o primeiro modelo de embedding nativamente multimodal do Google que mapeia texto, imagens, áudio, vídeo e PDFs para um único espaço vetorial semântico de 3,072 dimensões (com tamanhos de saída configuráveis). Ele introduz Matryoshka Representation Learning para fornecer embeddings aninhados/truncados, desempenho multilíngue aprimorado (100+ idiomas) e controles otimizados para embeddings específicos de tarefa (por exemplo, task:search, task:code).
O que é o Gemini Embedding 2?
O Gemini Embedding 2 é um modelo de embedding unificado do Google que mapeia várias modalidades de entrada — texto, imagens, áudio, vídeo e documentos — para um único espaço vetorial semântico. Cada embedding é (por padrão) um vetor de ponto flutuante de 3,072 dimensões que representa o significado semântico da entrada, de modo que itens semanticamente semelhantes (independentemente da modalidade) fiquem próximos no espaço vetorial.As principais capacidades são:
- Ampla cobertura de idiomas e formatos: um único modelo que aceita texto, imagens, áudio, vídeo e documentos e os posiciona em um único espaço vetorial semântico. O Gemini Embedding 2 está documentado para capturar intenção semântica em 100+ idiomas e aceitar formatos de arquivo comuns (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), com limites concretos por requisição (por exemplo, até algumas imagens ou dezenas de segundos de áudio/vídeo por requisição — veja “Como usar” abaixo).
- Verdadeira multimodalidade: um único modelo que aceita texto, imagens, áudio, vídeo e documentos e os posiciona em um único espaço vetorial semântico, permitindo comparar ou recuperar entre modalidades (por exemplo, texto → imagem, áudio → texto).
- Alta dimensionalidade padrão com truncamento flexível: o modelo produz vetores de 3072 dimensões por padrão, mas usa Matryoshka Representation Learning (MRL) para concentrar o conteúdo semântico mais importante nas primeiras dimensões, de modo que você possa truncar para 1536, 768 (ou menos) com apenas quedas modestas na qualidade de recuperação. Isso reduz os trade-offs de armazenamento e computação.
Por que isso importa. Historicamente, embeddings eram majoritariamente somente de texto ou exigiam codificadores separados por modalidade com camadas complexas de alinhamento intermodal. O Gemini Embedding 2 elimina essa barreira ao oferecer suporte nativo a vários formatos — assim, uma consulta em texto pode recuperar uma imagem ou um clipe curto por similaridade semântica sem transcrição intermediária ou mapeamento manual. Isso simplifica pipelines de RAG (retrieval-augmented generation), busca semântica e recuperação multimodal.
Principais recursos e capacidades (o que há de novo)
1. Multimodalidade nativa de verdade (um único espaço de embedding)
Um único modelo que aceita texto, imagens, áudio, vídeo e documentos e os posiciona em um único espaço vetorial semântico. O Gemini Embedding 2 mapeia texto, imagens, áudio, vídeo e documentos no mesmo espaço de embedding, de modo que a recuperação intermodal (texto→imagem, áudio→texto) funcione diretamente sem alinhamento entre modelos. Isso reduz a complexidade da pipeline e simplifica stacks de RAG (Retrieval-Augmented Generation).
2. Vetores padrão de 3,072 dimensões com saída ajustável
O Gemini Embedding 2 produz vetores de 3072 dimensões por padrão, mas utiliza Matryoshka Representation Learning (MRL) para concentrar o conteúdo semântico mais relevante nas primeiras dimensões, permitindo truncar para 1536, 768 (ou menos) com queda apenas modesta na qualidade de recuperação. Isso reduz os trade-offs de armazenamento e custo computacional.
3. Matryoshka Representation Learning (MRL)
O MRL produz embeddings “aninhados” — como bonecas russas — de modo que fatias de menor dimensionalidade preservem semânticas de nível mais alto. Isso permite que os sistemas escolham um ponto de operação (trade-off armazenamento/precisão) sem manter vários modelos de embedding separados. Análises iniciais em blogs e a documentação descrevem essa técnica como uma inovação central para flexibilidade.
4. Dicas de tarefa / objetivos de embedding personalizados
A API aceita dicas de task (por exemplo, task:search, task:code retrieval, task:semantic-similarity) para que o modelo possa otimizar a geometria do embedding para relações específicas de downstream — semelhante ao condicionamento por tarefa usado em sistemas de embedding anteriores, mas estendido a entradas multimodais.
5. Amplitude de idiomas e modalidades
O Gemini Embedding 2 está documentado para capturar intenção semântica em 100+ idiomas e aceitar formatos de arquivo comuns (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF), com limites concretos por requisição (por exemplo, até algumas imagens ou dezenas de segundos de áudio/vídeo por requisição — veja “Como usar” abaixo).
Benchmarks de desempenho
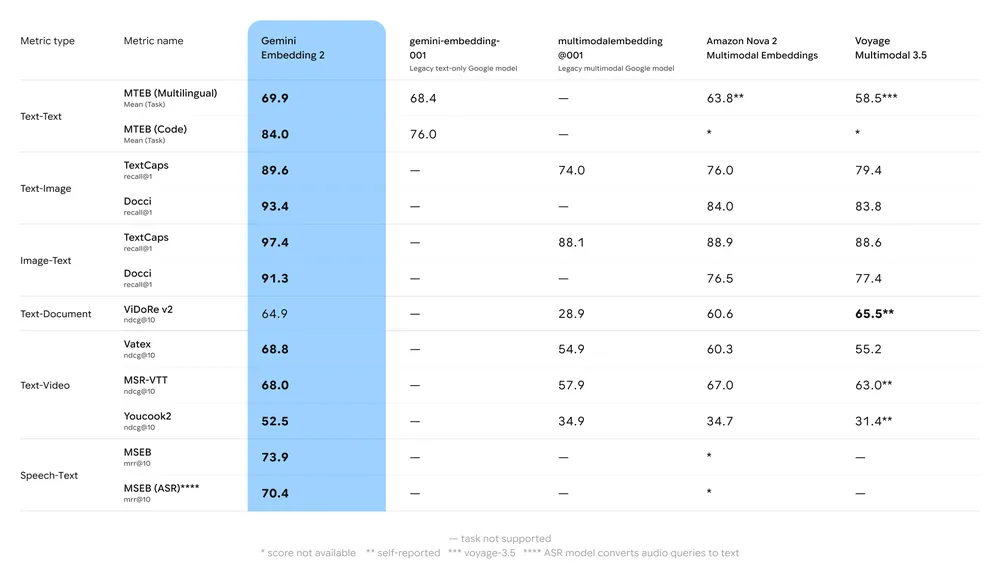
Resumo dos principais benchmarks:
- MTEB (Massive Text Embedding Benchmark): Apresenta colocação forte nos rankings MTEB multilíngues para tarefas em inglês e multilíngues; análises mostram ganho significativo vs. os modelos de embedding anteriores do Gemini e muitas alternativas proprietárias.
- Recuperação multimodal: Supera ou iguala embeddings de modalidade única líderes quando usado para similaridade intermodal (por exemplo, recuperação texto→imagem), graças ao treinamento multimodal nativo.
- Latência e throughput: Geração de embeddings hospedada na nuvem, mas casos sensíveis à latência podem preferir vetores truncados ou modelos alternativos leves de embedding para necessidades na borda.
Gemini Embedding 2 vs gemini-embedding-001 e text-embedding-3-large
| Atributo | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Lançamento / disponibilidade | Mar 10, 2026 — public preview (Gemini API / Vertex AI). | Modelo Gemini de embedding anterior (variantes somente texto) — GA anteriormente. | Anunciado em Jan 2024 (somente texto GA). |
| Modalidades suportadas | Texto, imagens, áudio, vídeo, documentos (PDF) — espaço vetorial unificado. | Texto (principalmente). | Somente texto (multilíngue de alta qualidade). |
| Dimensão de embedding padrão | 3072 (MRL / truncamento recomendado: 1536, 768). | 3072 (para o grande) — somente texto. | 3072 (text-embedding-3-large). |
| MTEB reportado (exemplo) | Alta casa dos 60s no MTEB; mostra 68.17 em 1536 na tabela do fornecedor (ver docs). | gemini-embedding-001 reportado ~68.32 de média em alguns leaderboards. | ~64.6 (média MTEB reportada pela OpenAI para text-embedding-3-large). |
| Suporte nativo a áudio/vídeo | Sim (embedding direto de áudio/vídeo). | Não (somente texto). | Não (somente texto). |
| Casos de uso típicos | Recuperação multimodal, RAG, busca semântica entre tipos de arquivo, recuperação de fala, busca em vídeo. | Recuperação de texto, RAG multilíngue. | Recuperação de texto, busca semântica, RAG — forte desempenho em texto multilíngue. |
Especificações técnicas e limites
Tamanho de embedding padrão e ajustável
- Padrão: 3,072 dimensões.
- Ajustável: o parâmetro
output_dimensionalitypermite solicitar saídas de menor dimensionalidade para economizar armazenamento / CPU. Casos com bases vetoriais massivas frequentemente reduzem dimensões para 512–1,024 por razões de custo, aceitando algum trade-off de qualidade.
Modalidades suportadas e limites por requisição
- Imagens: PNG, JPEG — até 6 imagens por requisição (limites reportados pelo fornecedor).
- Vídeo: MP4, MOV — o fornecedor reporta até ~128 segundos por vídeo em embedding de requisição única.
- Áudio: MP3, WAV — o fornecedor reporta até ~80 segundos por entrada de áudio.
- Documentos: PDFs — até 6 páginas por requisição (relato do fornecedor).
- Limite de tokens para conteúdo textual: o modelo suporta entradas de tokens grandes; existem limites práticos por requisição (consulte a documentação da API e as cotas do Vertex AI).
Disponibilidade e acesso
- Public preview: o Gemini Embedding 2 foi lançado como prévia pública e está disponível por meio da Gemini API e do Vertex AI do Google Cloud para uso experimental imediato
Perguntas frequentes (FAQ)
P1: Quais modalidades o Gemini Embedding 2 suporta?
R: Texto, imagens (PNG/JPEG), vídeo (MP4/MOV), áudio (MP3/WAV) e documentos PDF — todos mapeados para o mesmo espaço vetorial semântico.
P2: Qual é o tamanho padrão do vetor no Gemini Embedding 2?
R: O padrão é 3,072 dimensões. Você pode solicitar dimensionalidade de saída menor via API.
P3: O Gemini Embedding 2 já está disponível?
R: Sim — foi anunciado como prévia pública e está disponível por meio da Gemini API e do Vertex AI (verifique o ID do modelo gemini-embedding-2-preview e o changelog atual).
P4: Como ele se compara a embeddings de outros provedores?
R: Testes independentes de fornecedores reportam que o Gemini Embedding 2 está entre os principais modelos proprietários para texto multilíngue e apresenta desempenho de ponta em várias tarefas multimodais. As classificações exatas variam por tarefa e dataset; teste com seus próprios dados.
P5: Preciso transcrever áudio para usar o Gemini Embedding 2?
R: Não — o Gemini Embedding 2 pode aceitar áudio diretamente e produzir embeddings sem primeiro transcrever para texto, possibilitando recuperação semântica de áudio de ponta a ponta.
P6: Como reduzir os custos de armazenamento para vetores de 3,072 dimensões?
R: As opções incluem solicitar output_dimensionality menor, usar float16/quantização/PQ e armazenar representações compactadas em seu banco de dados vetorial. Postagens do fornecedor fornecem fluxos de trabalho e boas práticas.
O que vem a seguir — devo adotar agora?
O Gemini Embedding 2 é um grande passo na unificação da recuperação multimodal e simplifica arquiteturas que antes exigiam recuperadores separados para texto, visão e fala. Pontos-chave de decisão para adoção:
- Adote mais cedo se seu produto precisa de recuperação intermodal robusta (texto↔imagem/vídeo/áudio) ou se manter múltiplos recuperadores de modalidade única é caro e complexo.
- Pilote agora se quiser avaliar o truncamento via MRL e medir custo vs. qualidade (mantenha um deployment híbrido: 1536 como primário, 3072 para re-ranking).
- Espere se sua carga de trabalho é extremamente sensível a custos e requer apenas recuperação de texto — modelos somente texto de ponta (por exemplo, OpenAI text-embedding-3-large) continuam competitivos e às vezes mais baratos dependendo da sua pipeline e contrato.
Desenvolvedores podem acessar o Gemini Embedding 2 e a API do OpenAI text-embedding-3 via CometAPI agora. Para começar, explore as capacidades do modelo no Playground e consulte o Guia da API para instruções detalhadas. Antes de acessar, verifique se você fez login na CometAPI e obteve a chave de API. A CometAPI oferece um preço muito inferior ao oficial para ajudar na integração.
Pronto para começar?→ Inscreva-se no cometapi hoje !
Se quiser mais dicas, guias e notícias sobre IA, siga-nos no VK, X e Discord!