

Kimi K2 Thinking é a nova variante "pensante" da família Kimi K2 da Moonshot AI: um modelo de Mistura de Especialistas (MoE) esparso com um trilhão de parâmetros, explicitamente projetado para Pense enquanto age. — ou seja, intercalar raciocínio complexo com chamadas de ferramentas confiáveis, planejamento de longo prazo e autoverificações automatizadas. Combina uma grande infraestrutura esparsa (≈1T de parâmetros totais, ~32B ativados por token), um pipeline de quantização INT4 nativo e um design escalável. tempo de inferência raciocínio (mais "tokens de pensamento" e mais rodadas de chamadas de ferramentas) em vez de simplesmente aumentar a contagem de parâmetros estáticos.
Em termos simples: o K2 Thinking trata o modelo como uma ferramenta de resolução de problemas. agente em vez de um gerador de linguagem de uso único. Essa mudança — de “modelo de linguagem” para “modelo de pensamento” — é o que torna este lançamento notável e por que muitos profissionais o consideram um marco na IA agente de código aberto.
O que exatamente é o “Pensamento Kimi K2”?
Arquitetura e especificações principais
O K2 Thinking é construído como um modelo MoE esparso (384 especialistas, 8 especialistas selecionados por token) com cerca de 1 trilhão de parâmetros totais e ~32B parâmetros ativados por inferência. Utiliza escolhas arquitetônicas híbridas (atenção MLA, ativações SwiGLU) e foi treinada com o otimizador Muon/MuonClip da Moonshot em grandes orçamentos de tokens, conforme descrito em seu relatório técnico. A variante de raciocínio estende o modelo base com quantização pós-treinamento (suporte nativo a INT4), uma janela de contexto de 256k e engenharia para expor e estabilizar o rastreamento de raciocínio interno do modelo durante o uso real.
O que significa “pensar” na prática
O conceito de "pensamento" aqui se refere a um objetivo de engenharia: permitir que o modelo (1) gere longas cadeias estruturadas de raciocínio interno (tokens de cadeia de pensamento), (2) invoque ferramentas externas (busca, ambientes de teste Python, navegadores, bancos de dados) como parte desse raciocínio, (3) avalie e verifique automaticamente afirmações intermediárias e (4) itere por muitos desses ciclos sem perder a coerência. A documentação e o cartão do modelo do Moonshot mostram o K2 Thinking explicitamente treinado e ajustado para intercalar raciocínio e chamadas de função, e para manter um comportamento estável ao longo de centenas de etapas.
Qual é o objetivo principal?
As limitações dos modelos tradicionais de grande escala são:
- O processo de geração é míope, carecendo de lógica transversal;
- O uso de ferramentas é limitado (normalmente, apenas ferramentas externas podem ser chamadas uma ou duas vezes);
- Eles não conseguem se autocorrigir em problemas complexos.
O principal objetivo do projeto K2 Thinking é resolver esses três problemas. Na prática, o K2 Thinking consegue, sem intervenção humana: executar de 200 a 300 chamadas de ferramentas consecutivas; manter centenas de etapas de raciocínio logicamente coerente; e resolver problemas complexos por meio de autoverificação contextual.
Reposicionamento: modelo de linguagem → modelo de pensamento
O projeto K2 Thinking ilustra uma mudança estratégica mais ampla na área: ir além da geração condicional de texto em direção a solucionadores de problemas agentesO objetivo principal não é primordialmente melhorar a perplexidade ou a previsão do próximo token, mas sim criar modelos que possam:
- Planejamento suas próprias estratégias de várias etapas;
- Coordenada ferramentas e atuadores externos (busca, execução de código, bases de conhecimento);
- verificar resultados intermediários e correção de erros;
- Sustentar coerência em contextos extensos e cadeias de ferramentas complexas.
Essa reformulação altera tanto a avaliação (os parâmetros de referência enfatizam processos e resultados, não apenas a qualidade do texto) quanto a engenharia (estruturas para roteamento de ferramentas, contagem de etapas, autocrítica, etc.).
Métodos de trabalho: como funcionam os modelos de pensamento
Na prática, o K2 Thinking demonstra diversos métodos de trabalho que caracterizam a abordagem do “modelo de pensamento”:
- Vestígios internos persistentes: O modelo produz etapas intermediárias estruturadas (rastros de raciocínio) que são mantidas em contexto e podem ser reutilizadas ou auditadas posteriormente.
- Roteamento dinâmico de ferramentas: Com base em cada etapa interna, o K2 decide qual ferramenta utilizar (busca, interpretador de código, navegador web) e quando utilizá-la.
- Dimensionamento em tempo de teste: Durante a inferência, o sistema pode expandir sua "profundidade de raciocínio" (mais tokens de raciocínio interno) e aumentar o número de chamadas de ferramentas para explorar melhor as soluções.
- Autoverificação e recuperação: O modelo verifica explicitamente os resultados, executa testes de sanidade e replaneja quando as verificações falham.
Esses métodos combinam arquitetura de modelos (MoE + contexto longo) com engenharia de sistemas (orquestração de ferramentas, verificações de segurança).
Que inovações tecnológicas possibilitam o pensamento Kimi K2?
O mecanismo de raciocínio do Kimi K2 Thinking suporta o pensamento intercalado e o uso de ferramentas. O ciclo de raciocínio do K2 Thinking:
- Compreensão do problema (análise sintática e abstração)
- Geração de um plano de raciocínio de várias etapas (cadeia de planos)
- Utilizando ferramentas externas (código, navegador, mecanismo matemático)
- Verificar e revisar os resultados (verificar e revisar)
- Concluir o raciocínio (concluir o raciocínio)
A seguir, apresentarei três técnicas essenciais que tornam possíveis os ciclos de raciocínio em xx.
1) Escalonamento em tempo de teste
O que é: As “Leis de Escala” tradicionais focam no aumento do número de parâmetros ou dados durante o treinamento. A inovação do K2 Thinking reside em: expandir dinamicamente o número de tokens (ou seja, a profundidade do pensamento) durante a “fase de raciocínio”; e expandir simultaneamente o número de chamadas de ferramentas (ou seja, a amplitude da ação). Esse método é chamado de escalonamento em tempo de teste, e sua premissa fundamental é: “Uma cadeia de raciocínio mais longa + ferramentas mais interativas = um salto qualitativo na inteligência real”.
Por que isso é importante: O K2 Thinking otimiza explicitamente isso: o projeto Moonshot demonstra que a expansão dos "tokens de pensamento" e do número/profundidade das chamadas de ferramentas resulta em melhorias mensuráveis em benchmarks de agentes, permitindo que o modelo supere outros modelos de tamanho semelhante ou maior em cenários com número equivalente de operações de ponto flutuante (FLOPs).
2) Raciocínio Aumentado por Ferramentas
O que é: O K2 Thinking foi projetado para analisar esquemas de ferramentas nativamente, decidir autonomamente quando chamar uma ferramenta e incorporar os resultados da ferramenta de volta ao seu fluxo de raciocínio contínuo. A Moonshot treinou e ajustou o modelo para intercalar a linha de raciocínio com chamadas de função e, em seguida, estabilizou esse comportamento em centenas de etapas sequenciais de ferramentas.
Por que isso é importante: Essa combinação — análise sintática confiável + estado interno estável + ferramentas de API — é o que permite ao modelo navegar na web, executar código e orquestrar fluxos de trabalho de várias etapas como parte de uma única sessão.
Em sua arquitetura interna, o modelo forma uma trajetória de execução de um "processo de pensamento visualizado": estímulo → tokens de raciocínio → chamada da ferramenta → observação → próximo raciocínio → resposta final
3) Coerência de longo prazo e autoverificação
O que é: A coerência de longo prazo é a capacidade do modelo de manter um plano coerente e um estado interno consistente ao longo de várias etapas e em contextos muito extensos. A autoverificação significa que o modelo verifica proativamente suas saídas intermediárias e executa novamente ou revisa as etapas quando uma verificação falha. Tarefas longas frequentemente fazem com que os modelos apresentem desvios ou alucinações. O K2 Thinking aborda esse problema com diversas técnicas: janelas de contexto muito longas (256k), estratégias de treinamento que preservam o estado em longas sequências de CoT (Coerência de Tempo) e modelos explícitos de fidelidade/julgamento em nível de sentença para detectar afirmações sem suporte.
Por que isso é importante: O mecanismo de “Memória de Raciocínio Recorrente” mantém a persistência do estado de raciocínio, conferindo-lhe características semelhantes às humanas de “estabilidade de pensamento” e “autossupervisão contextual”. À medida que as tarefas se estendem por muitas etapas (por exemplo, projetos de pesquisa, tarefas de codificação de múltiplos arquivos, longos processos editoriais), manter uma linha de raciocínio coerente torna-se essencial. A autoverificação reduz falhas silenciosas; em vez de retornar uma resposta plausível, mas incorreta, o modelo pode detectar inconsistências e consultar novamente as ferramentas ou replanejar.
capacidades:
- Consistência contextual: Mantém a continuidade semântica em mais de 10 mil tokens;
- Detecção e reversão de erros: Identifica e corrige desvios lógicos nos estágios iniciais do raciocínio;
- Ciclo de autoverificação: Verifica automaticamente a razoabilidade da resposta após a conclusão do raciocínio;
- Fusão de raciocínio de múltiplos caminhos: Seleciona o caminho ideal dentre múltiplas cadeias lógicas.
Quais são as quatro competências essenciais do pensamento K2?
Raciocínio profundo e estruturado
O K2 Thinking foi projetado para gerar rastros de raciocínio explícitos e em múltiplos estágios, utilizando-os para alcançar conclusões robustas. O modelo apresenta excelentes resultados em benchmarks de matemática e raciocínio rigoroso (GSM8K, AIME, benchmarks no estilo IMO) e demonstra a capacidade de manter o raciocínio intacto ao longo de longas sequências — um requisito fundamental para a resolução de problemas em nível de pesquisa. Seu excelente desempenho no Humanity's Last Exam (44.9%) demonstra capacidades analíticas de nível especialista. Ele consegue extrair estruturas lógicas a partir de descrições semânticas imprecisas e gerar grafos de raciocínio.
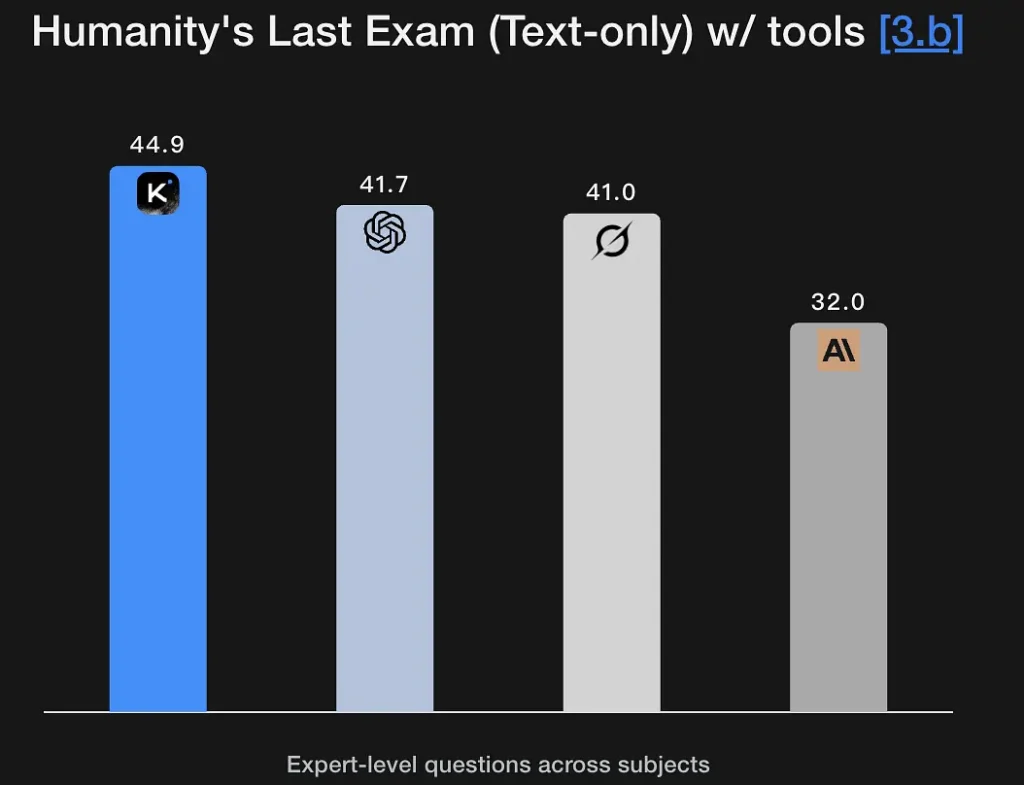
Principais Recursos:
- Suporta raciocínio simbólico: compreende e opera em estruturas matemáticas, lógicas e de programação.
- Possui capacidade de testar hipóteses: consegue propor e verificar hipóteses espontaneamente.
- Capaz de realizar a decomposição de problemas em múltiplas etapas: divide objetivos complexos em várias subtarefas.
Busca de Agente
Em vez de uma única etapa de recuperação, a busca agética permite que o modelo planeje uma estratégia de busca (o que procurar), execute-a por meio de chamadas repetidas à web/ferramentas, sintetize os resultados recebidos e refine a consulta. As pontuações do BrowseComp e do Seal-0, com suporte de ferramentas, indicam um desempenho sólido nessa capacidade; o modelo é explicitamente projetado para suportar buscas na web com múltiplas rodadas e planejamento com estado.
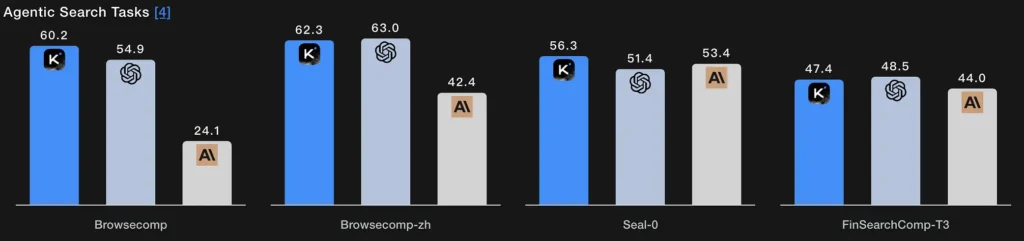
Essência técnica:
- O módulo de busca e o modelo de linguagem formam um ciclo fechado: geração de consulta → recuperação de página web → filtragem semântica → fusão de raciocínio.
- O modelo pode ajustar sua estratégia de busca de forma adaptativa, por exemplo, buscando primeiro por definições, depois por dados e, finalmente, verificando hipóteses.
- Essencialmente, trata-se de uma inteligência composta de “recuperação de informação + compreensão + argumentação”.
Codificação Agentic
Esta é a capacidade de Escrever, executar, testar e iterar. O K2 Thinking utiliza o código como parte de um ciclo de raciocínio. Ele apresenta resultados competitivos em benchmarks de codificação ao vivo e verificação de código, oferece suporte a toolchains Python em suas chamadas de ferramentas e pode executar loops de depuração em várias etapas, chamando um sandbox, lendo erros e reparando o código em execuções repetidas. Suas pontuações no EvalPlus/LiveCodeBench refletem esses pontos fortes. Alcançar uma pontuação de 71.3% no teste SWE-Bench Verified significa que ele pode concluir corretamente mais de 70% das tarefas de reparo de software do mundo real.
O sistema também demonstra desempenho estável no ambiente de competição LiveCodeBench V6, evidenciando suas capacidades de implementação e otimização de algoritmos.

Essência técnica:
- Adota um processo de “análise semântica + refatoração em nível de AST + verificação automática”;
- A execução e o teste do código são realizados por meio de chamadas de ferramentas na camada de execução;
- Ele realiza um desenvolvimento automatizado em circuito fechado, desde a compreensão do código → diagnóstico de erros → geração de correções → verificação do sucesso.
Escrita Agencial
Além da prosa criativa, a escrita proativa é a produção estruturada e orientada a objetivos de documentos, que pode exigir pesquisa externa, citações, geração de tabelas e refinamento iterativo (por exemplo, produzir um rascunho → verificar fatos → revisar). O contexto amplo e a orquestração de ferramentas do K2 Thinking o tornam adequado para fluxos de trabalho de escrita em várias etapas (resumos de pesquisa, sumários de regulamentos, conteúdo com vários capítulos). As taxas de sucesso do modelo em testes no estilo Arena e as métricas de escrita de textos longos corroboram essa afirmação.
Essência técnica:
- Gera automaticamente segmentos de texto usando planejamento de pensamento agentivo;
- Controla internamente a lógica do texto por meio de tokens de raciocínio;
- É possível invocar simultaneamente ferramentas como pesquisa, cálculo e geração de gráficos para alcançar a "escrita multimodal".
Como você pode usar o K2 Thinking hoje?
Modos de acesso
O K2 Thinking está disponível como uma versão de código aberto (pesos e pontos de verificação do modelo) e por meio de endpoints de plataforma e hubs da comunidade (Hugging Face, plataforma Moonshot). Você pode hospedar por conta própria se tiver recursos computacionais suficientes ou usar . CometAPIAPI/interface de usuário hospedada para integração mais rápida. Também documenta um reasoning_content Campo que, quando ativado, expõe os tokens de pensamento internos ao chamador.
Dicas práticas de utilização
- Comece com blocos de construção de agentesExponha inicialmente um pequeno conjunto de ferramentas determinísticas (busca, ambiente de teste Python e um banco de dados de fatos confiável). Forneça esquemas de ferramentas claros para que o modelo possa analisar/validar as chamadas.
- Ajustar o cálculo em tempo de testePara a resolução de problemas complexos, permita orçamentos de pensamento mais longos e mais rodadas de consulta de ferramentas; meça como a qualidade melhora em relação à latência/custo. A Moonshot defende a escalabilidade em tempo de teste como uma alavanca principal.
- **Utilize os modos INT4 para maior eficiência de custos.**O K2 Thinking suporta quantização INT4, o que oferece ganhos de velocidade significativos; porém, valide o comportamento em casos extremos nas suas tarefas.
- Raciocínio superficial do conteúdo cuidadosamenteExpor as cadeias internas pode ajudar na depuração, mas também aumenta a exposição a erros brutos do modelo. Trate o raciocínio interno como diagnóstico Não é uma fonte confiável; combine-a com verificação automatizada.
Conclusão
Kimi K2 Thinking é uma resposta projetada especificamente para a próxima era da IA: não apenas modelos maiores, mas agentes que pensam, agem e verificamA plataforma reúne escalabilidade MoE, estratégias de computação em tempo de teste, inferência nativa de baixa precisão e orquestração explícita de ferramentas para permitir a resolução sustentada de problemas em várias etapas. Para equipes que precisam de resolução de problemas em várias etapas e possuem a disciplina de engenharia para integrar, testar e monitorar sistemas de agentes, o K2 Thinking representa um grande avanço prático — e um importante teste de estresse para como a indústria e a sociedade irão governar a IA cada vez mais capaz e orientada à ação.
Os desenvolvedores podem acessar API de pensamento Kimi K2 através do CometAPI, a versão mais recente do modelo está sempre atualizado com o site oficial. Para começar, explore as capacidades do modelo no Playground e consulte o Guia de API para obter instruções detalhadas. Antes de acessar, certifique-se de ter feito login no CometAPI e obtido a chave da API. CometAPI oferecem um preço muito mais baixo que o preço oficial para ajudar você a se integrar.
Pronto para ir?→ Inscreva-se no CometAPI hoje mesmo !
Se você quiser saber mais dicas, guias e novidades sobre IA, siga-nos em VK, X e Discord!