

O que é o Llama 4?
Meta A Platforms revelou seu mais recente conjunto de modelos de grande linguagem (LLMs) da série Llama 4, marcando um avanço significativo na tecnologia de inteligência artificial. A coleção Llama 4 apresentará dois modelos principais em abril de 2025: Llama 4 Scout e Llama 4 Maverick. Esses modelos são projetados para processar e traduzir diversos formatos de dados, incluindo texto, vídeo, imagens e áudio, demonstrando suas capacidades multimodais. Além disso, a Meta apresentou o Llama 4 Behemoth, um modelo futuro, considerado um dos LLMs mais poderosos até o momento, com o objetivo de auxiliar no treinamento de futuros modelos.

Como o Llama 4 difere dos modelos anteriores?
Capacidades multimodais aprimoradas
Ao contrário de seus antecessores, o Llama 4 foi projetado para lidar com múltiplas modalidades de dados perfeitamente. Isso significa que ele pode analisar e gerar respostas com base em entradas de texto, imagens, vídeos e áudio, tornando-o altamente adaptável a diversas aplicações.
Introdução de Modelos Especializados
A Meta introduziu duas versões especializadas dentro da série Llama 4:
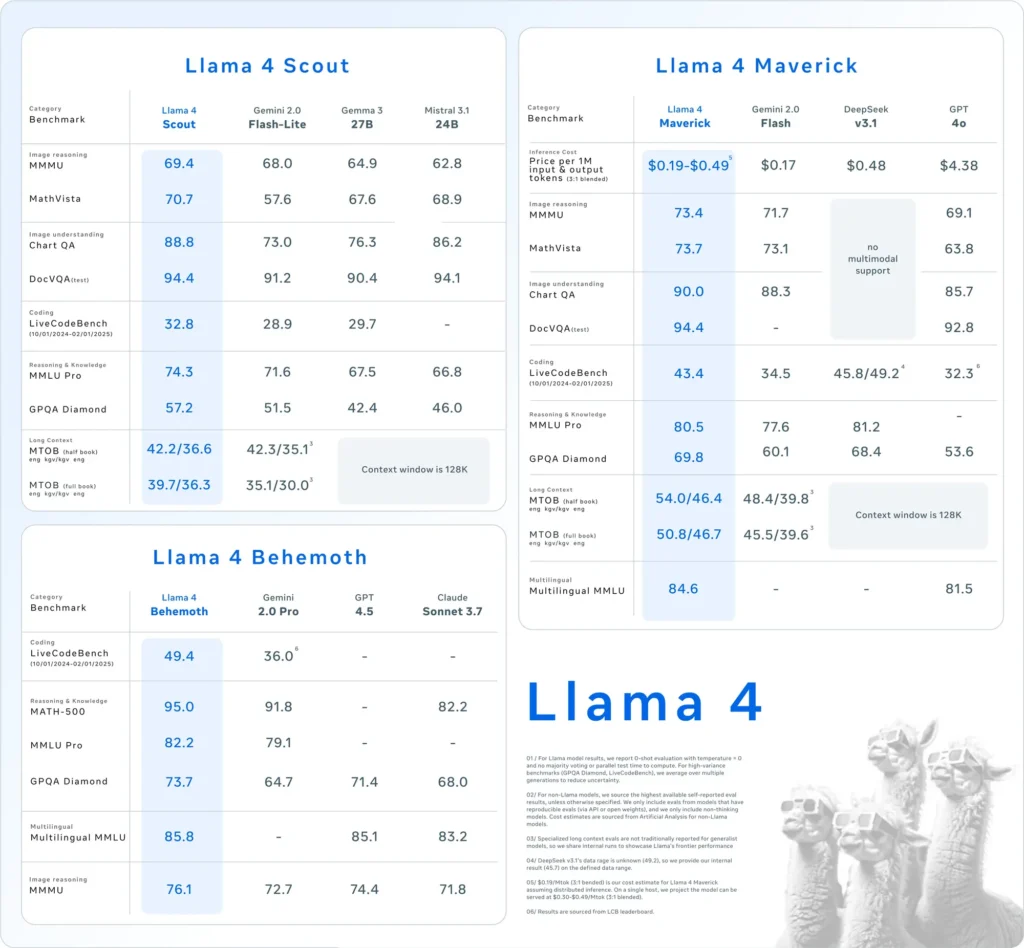
- Lhama 4 Scout: Um modelo compacto otimizado para rodar eficientemente em uma única GPU Nvidia H100. Possui uma janela de contexto de 10 milhões de tokens e demonstrou desempenho superior a concorrentes como Gemma 3 e Mistral 3.1 do Google em vários benchmarks.
- Lhama 4 Maverick: Um modelo maior, comparável em desempenho ao GPT-4o e ao DeepSeek-V3 da OpenAI, destacando-se particularmente em tarefas de codificação e raciocínio, ao mesmo tempo em que utiliza menos parâmetros ativos.
Além disso, a Meta está desenvolvendo Lhama 4 Behemoth, um modelo com 288 bilhões de parâmetros ativos e um total de 2 trilhões, com o objetivo de superar modelos como GPT-4.5 e Claude Sonnet 3.7 em benchmarks STEM.
Adoção da Arquitetura de Mistura de Especialistas (MoE)
O Llama 4 utiliza uma arquitetura de “mistura de especialistas” (MoE), dividindo o modelo em unidades especializadas para otimizar a utilização de recursos e aprimorar o desempenho. Essa abordagem permite um processamento mais eficiente, ativando apenas subconjuntos relevantes do modelo para tarefas específicas.
Como o Llama 4 se compara a outros modelos de IA?
O Llama 4 se posiciona competitivamente entre os principais modelos de IA:
- Benchmarks de desempenho: O desempenho do Llama 4 Maverick está no mesmo nível do GPT-4o e do DeepSeek-V3 da OpenAI em tarefas de codificação e raciocínio, enquanto o Llama 4 Scout supera modelos como o Gemma 3 e o Mistral 3.1 do Google em vários benchmarks.
- Abordagem de código aberto: O Meta continua a oferecer modelos Llama como código aberto, promovendo colaboração e integração mais amplas entre plataformas. No entanto, a licença Llama 4 impõe restrições a entidades comerciais com mais de 700 milhões de usuários, gerando discussões sobre a real abertura do modelo.
| Categoria | referência | Lhama 4 Maverick | GPT-4o | Gêmeos 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Raciocínio de Imagem | MMMU | 73.4 | 69.1 | 71.7 | Sem suporte multimodal |
| MathVista | 73.7 | 63.8 | 73.1 | Sem suporte multimodal | |
| Compreensão da imagem | GráficoQA | 90.0 | 85.7 | 88.3 | Sem suporte multimodal |
| DocVQA (teste) | 94.4 | 92.8 | - | Sem suporte multimodal | |
| Codificação | Banco de Códigos ao Vivo | 43.4 | 32.3 | 34.5 | 45.8/49.2 |
| Raciocínio e Conhecimento | MMLU Profissional | 80.5 | - | 77.6 | 81.2 |
| GPQA Diamante | 69.8 | 53.6 | 60.1 | 68.4 | |
| Multilíngue | MMLU multilíngue | 84.6 | 81.5 | - | - |
| Contexto longo | MTOB (meio livro) eng→kgv/kgv→eng | 54.0/46.4 | Contexto limitado a 128K | 48.4/39.8 | Contexto limitado a 128K |
| MTOB (livro completo) eng→kgv/kgv→eng | 50.8/46.7 | Contexto limitado a 128K | 45.5/39.6 | Contexto limitado a 128K |
Como o Llama 4 se sai em testes de benchmark?
As avaliações de benchmark fornecem insights sobre o desempenho dos modelos Llama 4:
- Lhama 4 Scout: Este modelo supera diversos concorrentes, incluindo o Gemma 3 e o Mistral 3.1 do Google, em vários benchmarks. Sua capacidade de operar com uma janela de contexto de 10 milhões de tokens em uma única GPU destaca sua eficiência e eficácia no processamento de tarefas complexas.
- Lhama 4 MaverickComparável em desempenho ao GPT-4o e ao DeepSeek-V3 da OpenAI, o Llama 4 Maverick se destaca em tarefas de codificação e raciocínio, utilizando menos parâmetros ativos. Essa eficiência não compromete a capacidade, tornando-o um forte concorrente no cenário de LLM.
- Lhama 4 BehemothCom 288 bilhões de parâmetros ativos e um total de 2 trilhões, o Llama 4 Behemoth supera modelos como GPT-4.5 e Claude Sonnet 3.7 em benchmarks STEM. Sua extensa contagem de parâmetros e desempenho indicam seu potencial como um modelo fundamental para futuros desenvolvimentos de IA.
Esses resultados de referência ressaltam a dedicação da Meta em aprimorar os recursos de IA e posicionar a série Llama 4 como um player formidável no setor.
Como os usuários podem acessar o Llama 4?
A Meta integrou os modelos Llama 4 ao seu assistente de IA, tornando-os acessíveis em plataformas como WhatsApp, Messenger, Instagram e web. Essa integração permite que os usuários experimentem os recursos aprimorados do Llama 4 em aplicativos familiares.
Para desenvolvedores e pesquisadores interessados em utilizar o Llama 4 em aplicações personalizadas, a Meta oferece acesso aos pesos do modelo por meio de plataformas como a Hugging Face e seus próprios canais de distribuição. Essa abordagem de código aberto permite que a comunidade de IA inove e desenvolva os recursos do Llama 4.
É importante observar que, embora o Llama 4 seja comercializado como código aberto, a licença impõe restrições a entidades comerciais com mais de 700 milhões de usuários. As organizações devem revisar os termos de licenciamento para garantir a conformidade com as diretrizes do Meta.
Crie rapidamente com o Llama 4 no CometAPI
A CometAPI fornece acesso a mais de 500 modelos de IA, incluindo modelos multimodais de código aberto e especializados para bate-papo, imagens, código e muito mais. Seu principal ponto forte reside na simplificação do processo tradicionalmente complexo de integração de IA. Ao centralizar a agregação de APIs em uma única plataforma, ela economiza tempo e recursos valiosos dos usuários, que, de outra forma, seriam gastos gerenciando plataformas e provedores separados. Com ela, o acesso às principais ferramentas de IA, como Claude, OpenAI, Deepseek e Gemini, está disponível por meio de uma assinatura única e unificada. Você pode usar a API da CometAPI para criar músicas e artes, gerar vídeos e criar seus próprios fluxos de trabalho.
CometAPI oferecemos um preço muito mais baixo do que o preço oficial para ajudá-lo a integrar API do Llama 4, e você receberá $1 em sua conta após registrar e fazer login! Bem-vindo para registrar e experimentar o CometAPI. O CometAPI paga conforme você usa,API do Llama 4 no CometAPI O preço é estruturado da seguinte forma:
| Categoria | lhama-4-maverick | lhama-4-scout |
| Preços da API | Tokens de entrada: $ 0.48 / M tokens | Tokens de entrada: $ 0.216 / M tokens |
| Tokens de saída: $ 1.44/ M tokens | Tokens de saída: $ 1.152/ M tokens |
- Por favor, consulte API do Llama 4 para detalhes de integração.
- Para obter informações sobre o modelo lançado na API Comet, consulte https://api.cometapi.com/new-model.
- Para obter informações sobre o preço do modelo na API Comet, consulte https://api.cometapi.com/pricing
Comece a construir CometAPI hoje – inscreva-se aqui para acesso gratuito ou escala sem limites de taxa atualizando para um Plano pago CometAPI.

Quais são as implicações do lançamento do Llama 4?
Integração entre plataformas meta
O Llama 4 é integrado ao assistente de IA da Meta em plataformas como WhatsApp, Messenger, Instagram e web, aprimorando as experiências do usuário com recursos avançados de IA.
Impacto na indústria de IA
O lançamento do Llama 4 reforça a investida agressiva da Meta em IA, com planos de investir até US$ 65 bilhões na expansão de sua infraestrutura de IA. Essa iniciativa reflete a crescente competição entre gigantes da tecnologia pela liderança em inovação em IA.
Considerações sobre consumo de energia
Os substanciais recursos computacionais necessários para o Llama 4 levantam preocupações sobre consumo de energia e sustentabilidade. Operar um cluster com mais de 100,000 GPUs consome energia significativamente, gerando discussões sobre o impacto ambiental de modelos de IA em larga escala.
O que o futuro reserva para Llama 4?
A Meta planeja discutir novos desenvolvimentos e aplicações do Llama 4 na próxima conferência LlamaCon em 29 de abril de 2025. A comunidade de IA espera insights sobre as estratégias da Meta para enfrentar os desafios atuais e alavancar os recursos do Llama 4 em vários setores.
Em resumo, o Llama 4 representa um avanço significativo em modelos de linguagem de IA, oferecendo recursos multimodais aprimorados e arquiteturas especializadas. Apesar dos desafios de desenvolvimento, os investimentos substanciais e as iniciativas estratégicas da Meta posicionam o Llama 4 como um concorrente formidável no cenário de IA em evolução.