

Em um cenário dominado pela filosofia de “escalar a qualquer custo” — onde modelos como Flux.2 e Hunyuan-Image-3.0 empurram a contagem de parâmetros para a faixa massiva de 30B a 80B — um novo concorrente surgiu para abalar o status quo. Z-Image, desenvolvido pelo Tongyi Lab da Alibaba, foi lançado oficialmente, quebrando expectativas com uma arquitetura enxuta de 6 bilhões de parâmetros que rivaliza com a qualidade de saída dos gigantes do setor, ao mesmo tempo em que roda em hardware de consumo.
Lançado no fim de 2025, Z-Image (e sua variante extremamente rápida Z-Image-Turbo) cativou instantaneamente a comunidade de IA, superando 500.000 downloads nas primeiras 24 horas após sua estreia. Ao entregar imagens fotorrealistas em apenas 8 passos de inferência, o Z-Image não é apenas mais um modelo; é uma força democratizadora na IA generativa, permitindo criação de alta fidelidade em laptops que travariam com seus concorrentes.
O que é o Z-Image?
Z-Image é um novo modelo fundamental de geração de imagens de código aberto desenvolvido pela equipe de pesquisa Tongyi-MAI / Alibaba Tongyi Lab. É um modelo generativo de 6 bilhões de parâmetros construído sobre uma arquitetura inédita de Transformador de Difusão de Fluxo Único Escalável (S3-DiT) que concatena tokens de texto, tokens semânticos visuais e tokens de VAE em um único fluxo de processamento. O objetivo do design é explícito: oferecer fotorrealismo de alto nível e aderência às instruções enquanto reduz drasticamente o custo de inferência e permite o uso prático em hardware de consumo. O projeto Z-Image publica código, pesos do modelo e uma demonstração online sob licença Apache-2.0.
O Z-Image é disponibilizado em várias variantes. O lançamento mais discutido é o Z-Image-Turbo — uma versão destilada, de poucos passos, otimizada para implantação — além do Z-Image-Base não destilado (checkpoint base, mais adequado para ajuste fino) e Z-Image-Edit (ajustado por instruções para edição de imagens).
A vantagem “Turbo”: inferência em 8 passos
A variante principal, Z-Image-Turbo, utiliza uma técnica de destilação progressiva conhecida como Decoupled-DMD (Distribution Matching Distillation). Isso permite que o modelo comprima o processo de geração dos 30–50 passos padrão para meros 8 passos.
Resultado: Tempos de geração sub-segundo em GPUs corporativas (H800) e desempenho praticamente em tempo real em placas de consumo (RTX 4090), sem o aspecto “plástico” ou “desbotado” típico de outros modelos turbo/lightning.
4 recursos principais do Z-Image
O Z-Image vem repleto de recursos que atendem tanto a desenvolvedores técnicos quanto a profissionais criativos.
1. Fotorrealismo e estética sem igual
Apesar de ter apenas 6 bilhões de parâmetros, o Z-Image produz imagens com uma clareza impressionante. Ele se destaca em:
- Textura de pele: Reprodução de poros, imperfeições e iluminação natural em sujeitos humanos.
- Física de materiais: Renderização precisa de vidro, metal e texturas de tecido.
- Iluminação: Manipulação superior de iluminação cinematográfica e volumétrica em comparação ao SDXL.
2. Renderização nativa de texto bilíngue
Um dos pontos de maior dor na geração de imagens por IA tem sido a renderização de texto. O Z-Image resolve isso com suporte nativo a inglês e chinês.
- Ele pode gerar pôsteres, logotipos e sinalizações complexos com ortografia e caligrafia corretas em ambos os idiomas, um recurso frequentemente ausente em modelos centrados no Ocidente.
3. Z-Image-Edit: edição baseada em instruções
Junto com o modelo base, a equipe lançou o Z-Image-Edit. Esta variante é ajustada para tarefas de image-to-image, permitindo que usuários modifiquem imagens existentes com instruções em linguagem natural (por exemplo, “Faça a pessoa sorrir”, “Mude o fundo para uma montanha nevada”). Ele mantém alta consistência de identidade e iluminação durante essas transformações.
4. Acessibilidade em hardware de consumo
- Eficiência de VRAM: Roda confortavelmente com 6GB de VRAM (com quantização) até 16GB de VRAM (precisão total).
- Execução local: Suporta totalmente implantação local via ComfyUI e
diffusers, livrando os usuários de dependências da nuvem.
Como o Z-Image funciona?
Transformador de difusão de fluxo único (S3-DiT)
O Z-Image se afasta dos designs clássicos de fluxo duplo (encoders/fluxos separados para texto e imagem) e, em vez disso, concatena tokens de texto, tokens de VAE de imagem e tokens semânticos visuais em uma única entrada do transformador. Essa abordagem de fluxo único melhora a utilização de parâmetros e simplifica o alinhamento intermodal dentro do backbone do transformador, o que, segundo os autores, produz uma relação eficiência/qualidade favorável para um modelo de 6B.
Decoupled-DMD e DMDR (destilação + RL)
Para viabilizar geração com poucos passos (8 passos) sem a penalidade usual de qualidade, a equipe desenvolveu uma abordagem de destilação Decoupled-DMD. A técnica separa a augmentação de CFG (classifier-free guidance) da correspondência de distribuição, permitindo que cada uma seja otimizada de forma independente. Em seguida, eles aplicam uma etapa de aprendizado por reforço pós-treinamento (DMDR) para refinar o alinhamento semântico e a estética. Juntas, essas técnicas produzem o Z-Image-Turbo com muito menos NFEs do que os modelos de difusão típicos, mantendo alto realismo.
Otimização de throughput e custo de treinamento
O Z-Image foi treinado com uma abordagem de otimização do ciclo de vida: pipelines de dados curados, um currículo simplificado e escolhas de implementação conscientes de eficiência. Os autores relatam a conclusão de todo o fluxo de treinamento em aproximadamente 314K horas de GPU H800 (≈ USD $630K) — uma métrica de engenharia explícita e reproduzível que posiciona o modelo como eficiente em custo em relação a alternativas muito grandes (>20B).
Resultados de benchmark do modelo Z-Image
O Z-Image-Turbo obteve pontuações elevadas em vários rankings contemporâneos, incluindo uma posição de topo entre open-source no Artificial Analysis Text-to-Image e forte desempenho nas avaliações de preferência humana do Alibaba AI Arena.
Mas a qualidade no mundo real também depende da formulação do prompt, resolução, pipeline de upscaling e processamento pós-geraçao adicional.
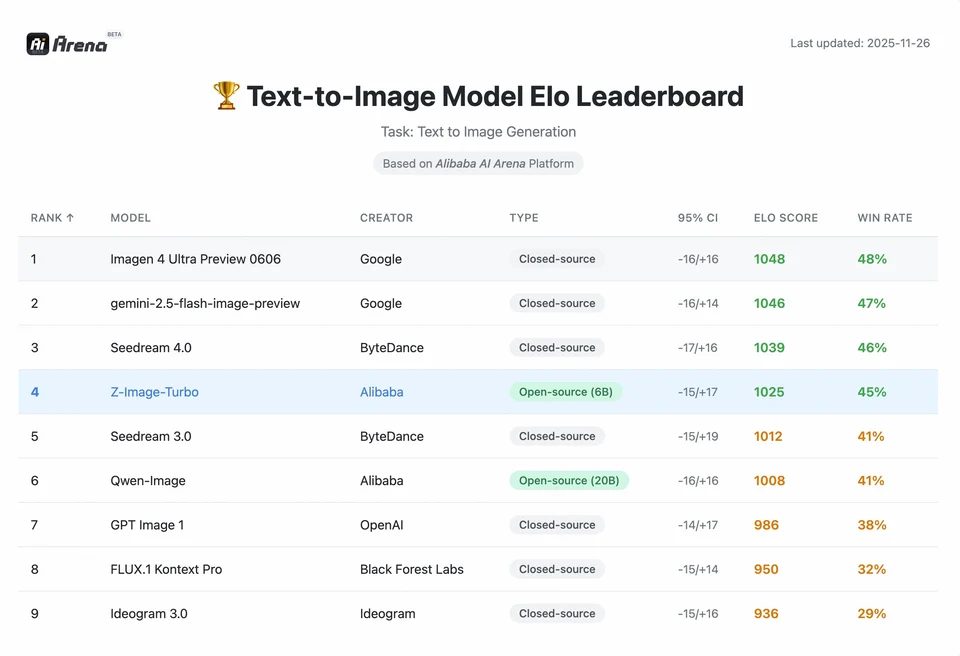
Para entender a magnitude da conquista do Z-Image, precisamos olhar para os dados. Abaixo está uma análise comparativa do Z-Image em relação a modelos líderes open-source e proprietários.
Resumo comparativo de benchmarks
| Recurso / Métrica | Z-Image-Turbo | Flux.2 (Dev/Pro) | SDXL Turbo | Hunyuan-Image |
|---|---|---|---|---|
| Arquitetura | S3-DiT (Fluxo único) | MM-DiT (Fluxo duplo) | U-Net | Transformador de Difusão |
| Parâmetros | 6 bilhões | 12B / 32B | 2,6B / 6,6B | ~30B+ |
| Passos de inferência | 8 passos | 25 - 50 passos | 1 - 4 passos | 30 - 50 passos |
| VRAM necessária | ~6GB - 12GB | 24GB+ | ~8GB | 24GB+ |
| Renderização de texto | Alta (EN + CN) | Alta (EN) | Moderada (EN) | Alta (CN + EN) |
| Velocidade de geração (4090) | ~1,5 - 3,0 segundos | ~15 - 30 segundos | ~0,5 segundo | ~20 segundos |
| Pontuação de fotorrealismo | 9,2/10 | 9,5/10 | 7,5/10 | 9,0/10 |
| Licença | Apache 2.0 | Não comercial (Dev) | OpenRAIL | Personalizada |
Análise de dados e insights de desempenho
- Velocidade vs. qualidade: Embora o SDXL Turbo seja mais rápido (1 passo), sua qualidade degrada significativamente em prompts complexos. O Z-Image-Turbo encontra o “ponto ideal” em 8 passos, igualando a qualidade do Flux.2 enquanto é 5x a 10x mais rápido.
- Democratização de hardware: O Flux.2, embora poderoso, fica na prática restrito a placas com 24GB de VRAM (RTX 3090/4090) para desempenho razoável. O Z-Image permite que usuários com placas de médio porte (RTX 3060/4060) gerem imagens profissionais 1024x1024 localmente.
Como os desenvolvedores podem acessar e usar o Z-Image?
Há três abordagens típicas:
- Hospedado / SaaS (UI web ou API): Use serviços como z-image.ai ou outros provedores que implantam o modelo e oferecem uma interface web ou API paga para geração de imagens. Esta é a rota mais rápida para experimentação sem configuração local.
- Hugging Face + pipelines do
diffusers: A bibliotecadiffusersdo Hugging Face incluiZImagePipelineeZImageImg2ImgPipelinee fornece fluxos típicosfrom_pretrained(...).to("cuda"). Este é o caminho recomendado para desenvolvedores Python que querem integração direta e exemplos reproduzíveis. - Inferência nativa local a partir do repositório do GitHub: O repositório Tongyi-MAI inclui scripts de inferência nativa, opções de otimização (FlashAttention, compilação, offload para CPU) e instruções para instalar
diffusersa partir do código-fonte para a integração mais recente. Esta rota é útil para pesquisadores e equipes que desejam controle total ou executar treinamento/ajuste fino personalizados.
Como é um exemplo mínimo em Python?
Abaixo está um snippet conciso em Python usando diffusers do Hugging Face que demonstra geração texto-para-imagem com o Z-Image-Turbo.
# minimal_zimage_turbo.pyimport torchfrom diffusers import ZImagePipelinedef generate(prompt, output_path="zimage_output.png", height=1024, width=1024, steps=9, guidance_scale=0.0, seed=42): # Use bfloat16 where supported for efficiency on modern GPUs pipe = ZImagePipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16) pipe.to("cuda") generator = torch.Generator("cuda").manual_seed(seed) image = pipe( prompt=prompt, height=height, width=width, num_inference_steps=steps, guidance_scale=guidance_scale, generator=generator, ).images[0] image.save(output_path) print(f"Saved: {output_path}")if __name__ == "__main__": generate("A cinematic portrait of a robot painter, studio lighting, ultra detailed")
Notas: guidance_scale padrões e configurações recomendadas diferem para modelos Turbo; a documentação sugere que a orientação pode ser baixa ou zero para Turbo, dependendo do comportamento desejado.
Como executar image-to-image (edição) com o Z-Image?
A ZImageImg2ImgPipeline suporta edição de imagem. Exemplo:
from diffusers import ZImageImg2ImgPipelinefrom diffusers.utils import load_imageimport torchpipe = ZImageImg2ImgPipeline.from_pretrained("Tongyi-MAI/Z-Image-Turbo", torch_dtype=torch.bfloat16)pipe.to("cuda")init_image = load_image("sketch.jpg").resize((1024, 1024))prompt = "Turn this sketch into a fantasy river valley with vibrant colors"result = pipe(prompt, image=init_image, strength=0.6, num_inference_steps=9, guidance_scale=0.0, generator=torch.Generator("cuda").manual_seed(123))result.images[0].save("zimage_img2img.png")
Isso reflete os padrões de uso oficiais e é adequado para tarefas criativas de edição e inpainting.
Como abordar prompts e orientação?
- Seja explícito com a estrutura: Para cenas complexas, estruture os prompts para incluir composição da cena, objeto focal, câmera/lente, iluminação, clima e quaisquer elementos textuais. O Z-Image se beneficia de prompts detalhados e lida bem com indícios posicionais/narrativos.
- Ajuste o
guidance_scalecom cuidado: Modelos Turbo podem recomendar valores de orientação mais baixos; é necessário experimentar. Para muitos fluxos Turbo,guidance_scale=0.0–1.0com semente e passos fixos produz resultados consistentes. - Use image-to-image para edições controladas: Quando você precisa preservar a composição, mas mudar estilo/colorização/objetos, comece com uma imagem inicial e use
strengthpara controlar a magnitude da mudança.
Melhores casos de uso e melhores práticas
1. Prototipagem rápida e storyboard
Caso de uso: Diretores de cinema e designers de jogos precisam visualizar cenas instantaneamente.
Por que Z-Image? Com geração abaixo de 3 segundos, criadores podem iterar centenas de conceitos em uma única sessão, refinando iluminação e composição em tempo real sem esperar minutos por um render.
2. E-commerce e publicidade
Caso de uso: Geração de fundos de produto ou cenas de estilo de vida para mercadorias.
Melhor prática: Use Z-Image-Edit.
Carregue uma foto de produto bruta e use um prompt de instrução como “Coloque este frasco de perfume sobre uma mesa de madeira em um jardim iluminado pelo sol.” O modelo preserva a integridade do produto enquanto alucina um fundo fotorrealista.
3. Criação de conteúdo bilíngue
Caso de uso: Campanhas de marketing globais que exigem ativos para mercados ocidentais e asiáticos.
Melhor prática: Utilize a capacidade de renderização de texto.
- Prompt: “Uma placa de néon com ‘OPEN’ e ‘营业中’ brilhando em um beco escuro.”
- O Z-Image renderizará corretamente os caracteres em inglês e chinês, um feito no qual a maioria dos outros modelos falha.
4. Ambientes de poucos recursos
Caso de uso: Execução de geração de IA em dispositivos de borda ou laptops de escritório padrão.
Dica de otimização: Use a versão quantizada em INT8 do Z-Image. Isso reduz o uso de VRAM para menos de 6GB com perda de qualidade desprezível, tornando-o viável para aplicativos locais em laptops sem GPU gamer.
Em resumo: quem deve usar o Z-Image?
O Z-Image foi projetado para organizações e desenvolvedores que desejam fotorrealismo de alta qualidade com latência e custo práticos, e que preferem licenciamento aberto e hospedagem on-premises ou personalizada. É particularmente atraente para equipes que precisam de iteração rápida (ferramentas criativas, mockups de produto, serviços em tempo real) e para pesquisadores/membros da comunidade interessados em ajustar um modelo de imagem compacto, porém poderoso.
A CometAPI oferece modelos Grok Image igualmente menos restritos, bem como modelos como Nano Banana Pro, GPT- image 1.5, Sora 2 (O Sora 2 pode gerar conteúdo NSFW? Como podemos testá-lo?) etc — desde que você tenha as dicas e truques NSFW certos para contornar as restrições e começar a criar livremente. Antes de acessar, certifique-se de ter feito login na CometAPI e obtido a chave de API. A CometAPI oferece um preço muito inferior ao preço oficial para ajudar na integração.
Pronto para começar?→ Teste gratuito para criação !