
Qwen3-Max-Preview is Alibaba’s latest flagship preview model in the Qwen3 family — a trillion+-parameter, Mixture-of-Experts (MoE) style model with an ultra-long 262k token context window, released in preview for enterprise/cloud use. It targets *deep reasoning, long-document understanding, coding, and agentic workflows.
Basic information & headline features
- Name / Label:
qwen3-max-preview(Instruct). - Scale: Over 1 trillion parameters (trillion-parameter flagship). This is the key marketing/statistical milestone for the release.
- Context window: 262,144 tokens (supports very long inputs and multi-file transcripts).
- Mode(s): Instruction-tuned “Instruct” variant with support for thinking (deliberate chain-of-thought) and non-thinking fast modes in the Qwen3 family.
- Availability: Preview access via Qwen Chat, Alibaba Cloud Model Studio (OpenAI-compatible or DashScope endpoints) and routing providers like CometAPI.
Technical details (architecture & modes)
- Architecture: Qwen3-Max follows the Qwen3 design lineage that uses a mix of dense + Mixture-of-Experts (MoE) components in larger variants, plus engineering choices to optimize inference efficiency for very large parameter counts.
- Thinking mode vs non-thinking mode: Qwen3 series introduced a thinking mode (for multi-step chain-of-thought style outputs) and non-thinking mode for faster, concise replies; the platform exposes parameters to toggle these behaviors.
- Context caching / performance features: Model Studio lists context cache support for large requests to reduce repeated input costs and improve throughput on repeated contexts.
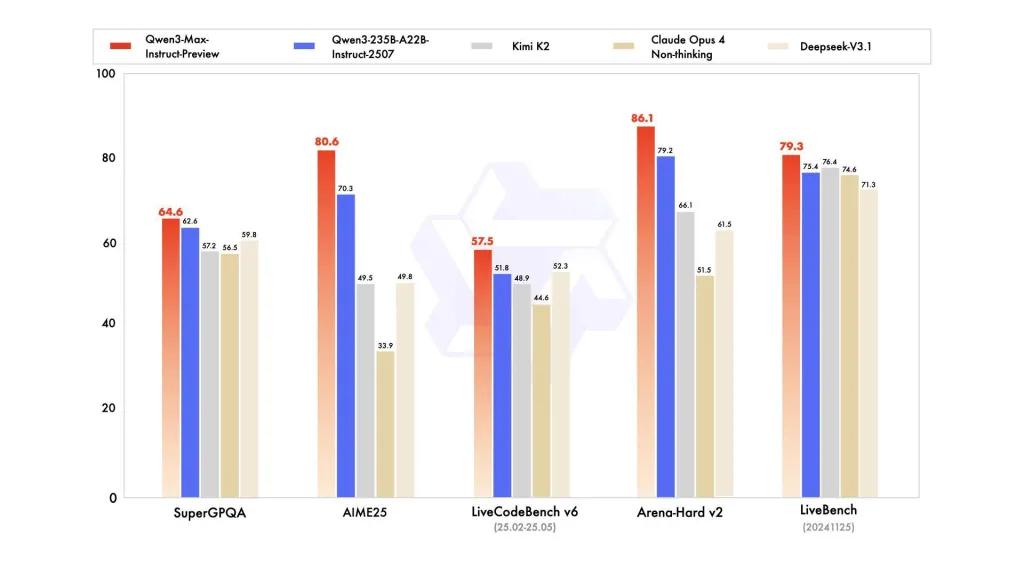
Benchmark performance
reports reference SuperGPQA, LiveCodeBench variants, AIME25 and other contest/benchmark suites where Qwen3-Max appears competitive or leading.
Limitations & risks (practical and safety notes)
- Opacity for full training recipe / weights: As a preview, the full training/data/weight release and reproducibility materials may be limited compared to earlier open-weight Qwen3 releases. Some Qwen3 family models were released open-weight, but Qwen3-Max is being delivered as a controlled preview for cloud access. This reduces reproducibility for independent researchers.
- Hallucinations & factuality: Vendor reports claim reductions in hallucinations, but real-world usage will still find factual errors and overconfident assertions — standard LLM caveats apply. Independent evaluation is necessary before high-stakes deployment.
- Cost at scale: With a huge context window and high capability, token costs can be substantial for very long prompts or production throughput. Use caching, chunking and budget controls.
- Regulatory and data-sovereignty considerations: Enterprise users should check Alibaba Cloud regions, data residency and compliance implications before processing sensitive information. (Model Studio documentation includes region-specific endpoints and notes.)
Use cases
- Document understanding / summarization at scale: legal briefs, technical specifications and multi-file knowledge bases (benefit: 262K token window).
- Long-context code reasoning & repository-scale code assist: multi-file code understanding, large PR reviews, repository-level refactoring suggestions.
- Complex reasoning and chain-of-thought tasks: math competitions, multi-step planning, agentic workflows where “thinking” traces help traceability.
- Multilingual, enterprise Q&A and structured data extraction: large multilingual corpora support and structured output capabilities (JSON / tables).
How to call Qqwen3-max-preview API from CometAPI
qwen3-max-preview API Pricing in CometAPI,20% off the official price:
| Input Tokens | $0.24 |
| Output Tokens | $2.42 |
Required Steps
- Log in to cometapi.com. If you are not our user yet, please register first
- Get the access credential API key of the interface. Click “Add Token” at the API token in the personal center, get the token key: sk-xxxxx and submit.
- Get the url of this site: https://api.cometapi.com/
Use Method
- Select the “qwen3-max-preview” endpoint to send the API request and set the request body. The request method and request body are obtained from our website API doc. Our website also provides Apifox test for your convenience.
- Replace <YOUR_API_KEY> with your actual CometAPI key from your account.
- Insert your question or request into the content field—this is what the model will respond to.
- . Process the API response to get the generated answer.
API Call
CometAPI provides a fully compatible REST API—for seamless migration. Key details to API doc:
- Core Parameters:
prompt,max_tokens_to_sample,temperature,stop_sequences - Endpoint:
https://api.cometapi.com/v1/chat/completions - Model Parameter: qwen3-max-preview
- Authentication:
Bearer YOUR_CometAPI_API_KEY - Content-Type:
application/json.
Replace
CometAPI_API_KEYwith your key; note the base URL.
Python (requests) — OpenAI-compatible
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Tip: use max_input_tokens, max_output_tokens, and Model Studio’s context cache features when sending very large contexts to control cost and throughput.
See Also Qwen3-Coder