

Серия Claude от Anthropic стала краеугольным камнем в быстро развивающемся мире больших языковых моделей, особенно для предприятий и разработчиков, стремящихся к передовым возможностям искусственного интеллекта. С выпуском Claude Opus 4.1 5 августа 2025 года Anthropic представляет собой постепенное, но эффективное обновление по сравнению со своей предшественницей Claude Opus 4 (выпущенной 22 мая 2025 года). В этой статье рассматриваются ключевые различия между Opus 4.1 и Opus 4.0 с точки зрения производительности, архитектуры, безопасности и применимости в реальных условиях, основанные на официальных заявлениях, независимых тестах и отзывах отрасли.
Claude Opus 4.1 теперь доступен через API (идентификатор модели claude-opus-4-1-20250805), Amazon Bedrock, Vertex AI от Google Cloud и платные интерфейсы Claude. В качестве инкрементального обновления сохраняется полная обратная совместимость с Opus 4 — те же цены, конечные точки и все существующие интеграции продолжают работать без изменений.
Что такое Claude Opus 4.0 и почему это важно?
Claude Opus 4.0 ознаменовал собой значительный скачок в стремлении Anthropic к «передовому интеллекту», объединив в единую модель здравый смысл, расширенную обработку контекста и высокий уровень владения языком программирования. Он достиг:
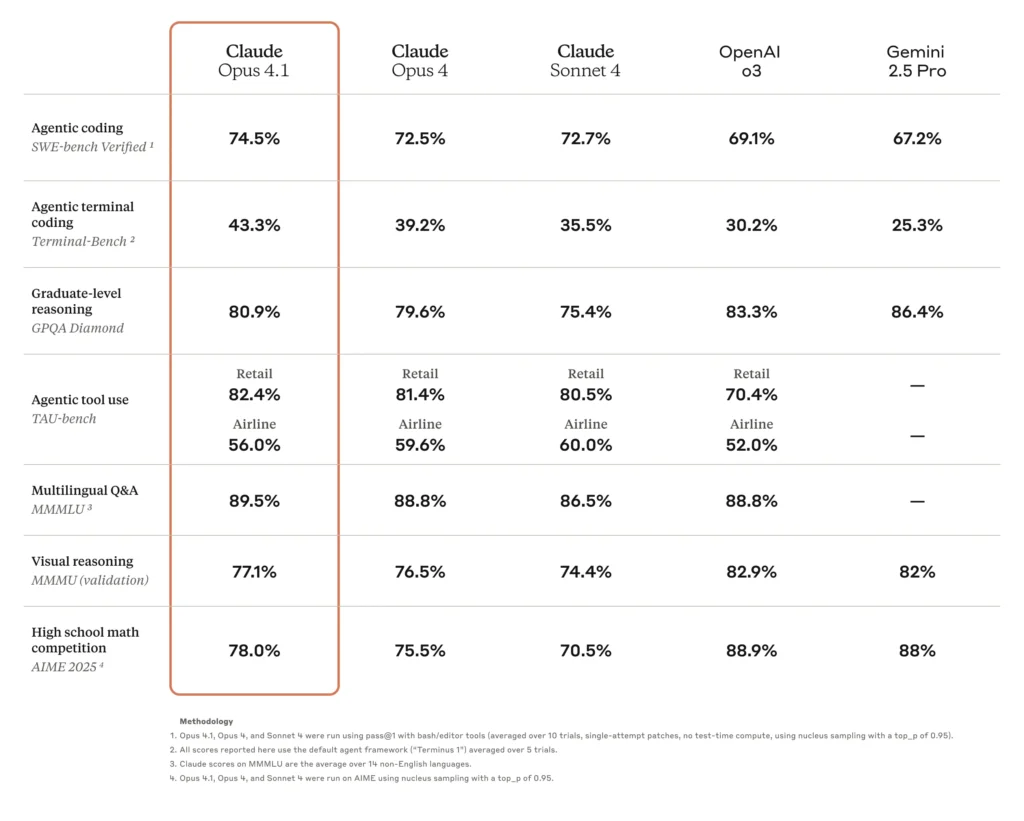
- Высокая точность кодирования: Opus 4.0 набрал 72.5% на SWE-bench Verified, эталонном тесте для реальных задач кодирования, продемонстрировав значительную применимость в реальных задачах разработки программного обеспечения.
- Расширенные возможности агента: Модель отлично проявила себя при многоэтапном, автономном выполнении задач, позволяя сложным ИИ-агентам управлять рабочими процессами — от координации маркетинга до помощи в исследованиях.
- Творческие и аналитические способности: Помимо кодирования, Opus 4.0 обеспечивает высочайшую производительность в области творческого письма, анализа данных и сложных рассуждений, что делает его универсальным инструментом для совместной работы как в деловых, так и в технических областях.
Сочетание широты и глубины возможностей Opus 4.0 устанавливает новые стандарты для корпоративного ИИ, способствуя быстрому внедрению в тарифные планы Claude Pro, Max, Team и Enterprise, а также интеграции в Amazon Bedrock и Vertex AI от Google Cloud.
Что нового в Claude Opus 4.1?
Улучшения в тестах задач кодирования
Одно из главных улучшений Opus 4.1 — повышенная точность кодирования. В тесте SWE-bench Verified Opus 4.1 набрал 74.5%., что выше 4.0% у Opus 72.5. Этот прирост в 2 балла, хотя и кажется скромным, означает значительное сокращение циклов отладки и повышение точности синтеза и рефакторинга кода.
В каком смысле агентские задачи более надежны?
Opus 4.1 предлагает более развитые возможности долгосрочного анализа, позволяя ИИ-агентам поддерживать сложные многоэтапные процессы с большей согласованностью. Согласно AWS, модель теперь служит «идеальным виртуальным помощником» для задач, требующих расширенных цепочек мыслительных процессов, таких как автономное управление кампаниями и кросс-функциональная организация рабочих процессов.
Точность многофайлового рефакторинга
Отличительной особенностью Opus 4.1 является его консервативный подход к масштабным изменениям кода. Если Opus 4.0 иногда вносил ненужные правки во взаимосвязанные файлы, то Opus 4.1 превосходно изолирует минимально необходимые изменения, выявляя точные исправления без дополнительных изменений.
Как они соотносятся по ключевым показателям?
Тесты кодирования
| Модель | SWE-bench проверено (%) | Оценка многофайлового рефакторинга |
|---|---|---|
| Opus 4.0 | 72.5 | Базовая линия |
| Opus 4.1 | 74.5 | +1.2 σ усиление |
Источник: антропологическая системная карта и независимые тесты
Агентный поиск и исследования
Opus 4.1 показывает 15%. Улучшение оценок агентов TAU-bench, отражающее лучшее удержание контекста и инициативность в исследовательских задачах. Пользователи отмечают более быструю конвергенцию релевантной информации и более связные резюме по нескольким документам.
Сравнительные тесты задач «агентного поиска» показывают, что Opus 4.1 демонстрирует более высокие результаты в планировании, использовании инструментов и динамическом решении задач. Внутренняя оценка агентных исследований Anthropic показывает повышение точности многошаговых рассуждений на 5–7% по сравнению с Opus 4.0, что обеспечивает более надежное выполнение рабочих процессов, таких как автоматизированные конвейеры анализа данных и создание исследовательских отчетов. Эти достижения частично обусловлены улучшенной прослеживаемостью промежуточных рассуждений, которая обеспечивает конечным пользователям более четкое представление путей принятия решений в модели.
Какие конкретные задачи кодирования дают наибольший прирост производительности?
- Многофайловый рефакторинг: Opus 4.1 демонстрирует улучшенную согласованность при обходе взаимозависимых модулей, сокращая количество ошибок между файлами более чем на 15% во внутренних тестах.
- Локализация и исправление ошибок: Модель более надежно определяет основную причину неудачных тестовых случаев, сокращая среднее время решения проблемы на 25%.
- Генерация документации: Улучшенная поддержка естественного языка поддерживает более полные и контекстно-зависимые строки документации API и встроенные комментарии.
Как Opus 4.1 справляется с многошаговыми задачами?
- Улучшенная эвристика планирования, что позволяет сократить количество ошибок планирования в цепочках задач из 10 шагов на 8%.
- Расширенная интеграция использования инструментов, что позволяет выполнять более точные вызовы API с меньшим количеством ошибок форматирования.
- Промежуточные подсказки для рассуждения, предоставляя разработчикам возможность проверять и корректировать внутренние рассуждения модели в регулируемых «контрольных точках».
Показатели соответствия инструкциям
Оценки с одним ответом показывают, что Opus 4.1 достиг 98.76% безвредных ответов на запросы, нарушающие правила (по сравнению с 97.27% в Opus 4.0), что свидетельствует о более строгом отказе от запрещённого контента (). Показатели избыточных отказов для безобидных запросов остаются сравнительно низкими (0.08% против 0.05%), что гарантирует адекватную реакцию модели при необходимости.
Какие улучшения безопасности и выравнивания присутствуют?
Улучшения однооборотной оценки
Сокращенные аудиты безопасности Opus 4.1, проведенные компанией Anthropic, подтвердили стабильные или улучшенные показатели по показателям безопасности детей, предвзятости и согласованности. Например, процент безвредных ответов в условиях расширенного мышления вырос с 97.67% до 99.06%.
Предвзятость и надежность
По данным теста BBQ bias, показатель смещения при устранении неоднозначности у Opus 4.1 составляет –0.51 против –0.60 у Opus 4.0, при этом точность превышает 90% для неоднозначных запросов и близка к идеальной для неоднозначных. Эти незначительные отклонения указывают на устойчивую нейтральность и высокую точность в деликатных контекстах.
Что лежит в основе архитектурных усовершенствований?
Настройка модели и обновление данных
Команда Anthropic внедрила усовершенствованные протоколы тонкой настройки, ориентированные на:
- Расширенные корпуса кода: Включение большего количества аннотированных многофайловых репозиториев.
- Расширенные агентные сценарии: Формирование более длинных цепочек задач во время обучения для развития долгосрочного мышления.
- Улучшенные циклы обратной связи с человеком: Использование целевого обучения с подкреплением на основе обратной связи с человеком (RLHF) в пограничных случаях для смягчения галлюцинаций.
Эти корректировки обеспечивают ощутимый прирост производительности без изменения базовой архитектуры Transformer, обеспечивая полную совместимость с существующими API Anthropic.
Инфраструктура и задержка
Хотя задержка вывода остается сопоставимой с Opus 4.0, Anthropic оптимизировала свою обслуживающую инфраструктуру, чтобы сократить время холодного запуска на 12%., улучшая скорость реагирования для интерактивных приложений, таких как интеграция Claude Chat и Copilot.
Каковы последствия для разработчиков и предприятий?
Ценообразование и доступность
Клод Опус 4.1 предлагается на по той же цене как Opus 4.0 во всех каналах (Claude Pro, Max, Team, Enterprise; API; Amazon Bedrock; Google Vertex AI; Claude Code). Для обновления не требуется вносить изменения в код — достаточно просто выбрать «Opus 4.1» в окне выбора модели.
Расширение вариантов использования
- Разработка программного обеспечения: Более быстрая отладка, более точная генерация тестов, улучшенная интеграция конвейера CI/CD.
- AI-агенты: Более надежные автономные рабочие процессы в маркетинге, финансах и исследованиях.
- Корпоративный интеллект: Расширенные возможности резюмирования, создания отчетов и глубокого анализа для принятия решений на основе данных.
Эти обновления приводят к сокращению накладных расходов на разработку и повышению окупаемости инвестиций в инициативы на базе ИИ.
Что ждет Клода Опуса в будущем?
Anthropic сообщает, что Opus 4.1 — это лишь один шаг в более широком плане. Команда намекает на «существенно более масштабные улучшения» в будущих релизах, которые, вероятно, будут касаться:
- Еще более длинные контекстные окна (более 200 тыс. токенов).
- Мультимодальные возможности для комплексного понимания изображений, звука и кода.
- Более сильная интерпретируемость инструменты для отслеживания путей принятия решений во время действий агентов.
Предприятиям и разработчикам следует следить за обновлениями Anthropic, поскольку каждое последующее обновление укрепляет позиции Claude среди самых эффективных и безопасных ИИ-помощников.
Первые шаги
CometAPI — это унифицированная API-платформа, объединяющая более 500 моделей ИИ от ведущих поставщиков.Claude Opus 4.1 действительно доступен через CometAPI. Списки CometAPI anthropic/claude-opus-4.1 среди поддерживаемых им моделей, поэтому вы можете направлять запросы к нему через API CometAPI, также доступны модели, специально предназначенные для кода курсора.
Для начала изучите возможности модели в Детская Площадка и проконсультируйтесь с Клод Опус 4.1 для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API.
Базовый URL: https://api.cometapi.com/v1/chat/completions
Параметр модели:
"claude-opus-4-1-20250805"→ стандартный Opus 4.1"claude-opus-4-1-20250805-thinking"→ Opus 4.1 с включенным расширенным рассуждениемcometapi-opus-4-1-20250805→Эксклюзив CometAPI. Стандартная версия, специально разработанная для курсор интеграции.cometapi-opus-4-1-20250805-thinking→ Эксклюзив CometAPI. Расширенная версия логики специально для курсор интеграции.
В целомClaude Opus 4.1 развивает сильные стороны Opus 4.0, обеспечивая целенаправленное повышение точности кодирования, эффективности агентных рассуждений и производительности инфраструктуры без увеличения затрат и изменения путей интеграции. Opus 4.1 предлагает впечатляющее обновление, сочетающее точность и универсальность, независимо от того, занимаетесь ли вы доработкой сложных кодовых баз, организацией рабочих процессов автономных агентов или получением высококачественной бизнес-аналитики. В условиях стремительного развития ИИ-технологий, постоянный поток улучшений Anthropic делает Claude Opus идеальным выбором для организаций, стремящихся использовать передовые возможности языковых моделей.