

Google и её исследовательское подразделение DeepMind тихо (а затем уже и совсем не тихо) продвинули ещё один крупный шаг в дорожной карте Gemini: Gemini 3.1 Pro. Этот релиз, развернутый на пользовательских площадках и в CometAPI, позиционируется как апгрейд производительности и рассуждений для семейства Gemini 3 — обещающий заметно более сильные длинные рассуждения, улучшенное мультимодальное понимание и лучшую масштабируемость для реальных приложений.
Новейшая модель Google — что такое Gemini 3.1 Pro?
Gemini 3.1 Pro — это первое инкрементальное обновление в семействе Gemini 3, позиционируемое как «наиболее способная» модель рассуждений, оптимизированная для многошаговых, мультимодальных и агентных задач. Выпущенная в публичное превью в середине февраля 2026 года (анонс превью 19–20 февраля 2026 года), модель явно нацелена на сценарии, требующие устойчивых цепочек рассуждений, использования инструментов и понимания длинного контекста — например: крупномасштабный синтез исследований, инженерные агенты, координирующие инструменты и системы, и мультимодальный анализ документов, совмещающих текст, изображения, аудио и видео.
На высоком уровне разработчики описывают Gemini 3.1 Pro как:
- Изначально мультимодальную — умеет принимать и рассуждать по тексту, изображениям, аудио и видео.
- Созданную для длинного контекста — поддерживает очень большие контекстные окна, подходящие для целых кодовых баз, досье из множества документов или длинных транскриптов.
- Оптимизированную для надежных рассуждений и агентных рабочих процессов, то есть настроенную планировать, вызывать инструменты и проверять выводы в многошаговых задачах.
Почему это важно сейчас: организации и разработчики переходят от «хороших разговорных ассистентов» к «агентам поддержки принятия ответственных решений и исследований» (юридическое составление документов, синтез НИОКР, мультимодальное понимание документов). Gemini 3.1 Pro явно создана для этого коридора — чтобы снизить галлюцинации, обеспечить отслеживаемость рассуждений и интеграцию с CometAPI как для прототипирования, так и для продакшена.
Каковы технические особенности и функции Gemini 3.1 Pro?
Изначальная мультимодальность и экстремальные окна контекста
Gemini 3.1 Pro продолжает ориентир линейки Gemini на мультимодальность. Согласно карточке модели и продуктовым заметкам, модель принимает и рассуждает по тексту, изображениям, аудио и видео в одном конвейере — возможность, упрощающая рабочие процессы, где типы данных смешаны (например, юридические показания с аудио + транскриптом + сканами). Важно, что модель поддерживает контекстное окно в 1,000,000 токенов и может выдавать длинные ответы (опубликованные заметки указывают на очень большие лимиты вывода, подходящие для задач длинного формата). Этот масштаб делает её пригодной для таких кейсов, как анализ целых репозиториев кода, многоглавных документов или длинных транскриптов без чанкинга.
«Динамическое мышление»: улучшенные рассуждения и пошаговое планирование
Google описывает 3.1 Pro как имеющую улучшенное «мышление» — то есть лучшую внутреннюю работу с цепочками рассуждений и динамический выбор стратегий в зависимости от сложности задачи. Модель настроена включать явное многошаговое планирование по необходимости и быть экономной по токенам при этом. На практике это означает меньше галлюцинаций для сложных, пошаговых задач и более высокую фактическую согласованность на бенчмарках многошагового рассуждения.
Агентные рабочие процессы и использование инструментов
Главный фокус 3.1 Pro — агентная производительность: координация инструментов, вызов веб-обоснования или поиска, написание и выполнение фрагментов кода, проверка результатов через дополнительные проходы. Google интегрировала 3.1 Pro в продукты с приоритетом агентов (например, среду разработки Antigravity), чтобы позволить моделям выполнять задачи, включающие редактор, терминал и браузер, — и записывать артефакты вроде скриншотов и записей браузера для верификации прогресса. Эти возможности призваны сократить разрыв между моделями, дающими советы, и моделями, которые действительно надежно выполняют многокомпонентные рабочие процессы с инструментами.
Специализированные подрежимы (Deep Research, Deep Think)
Google сочетается 3.1 Pro с «Deep Research» и упоминает готовящийся вариант «Deep Think». Эти подрежимы нацелены соответственно на задачи с высоким полнотой охвата в исследовании и на максимальную глубину рассуждений (за дополнительную вычислительную стоимость и задержку). Они призваны обслуживать аналитиков, исследователей и разработчиков, которым нужны более выверенные, высококачественные ответы, а не самые быстрые и дешевые.
Как Gemini 3.1 Pro показывает себя на бенчмарках?
Gemini 3.1 Pro достигает существенных приростов по сравнению с предыдущими результатами Gemini 3 Pro, часто выходя в лидеры на широком наборе метрик многошагового рассуждения и мультимодальности — но уступая некоторым конкурентам в отдельных специализированных задачах (в частности, в некоторых продвинутых заданиях по кодингу или наборах экспертных вопросов). Иными словами: широкие улучшения при узком отставании от конкурентов в нишевых бенчмарках.
Ключевые заявления по бенчмаркам и главные цифры
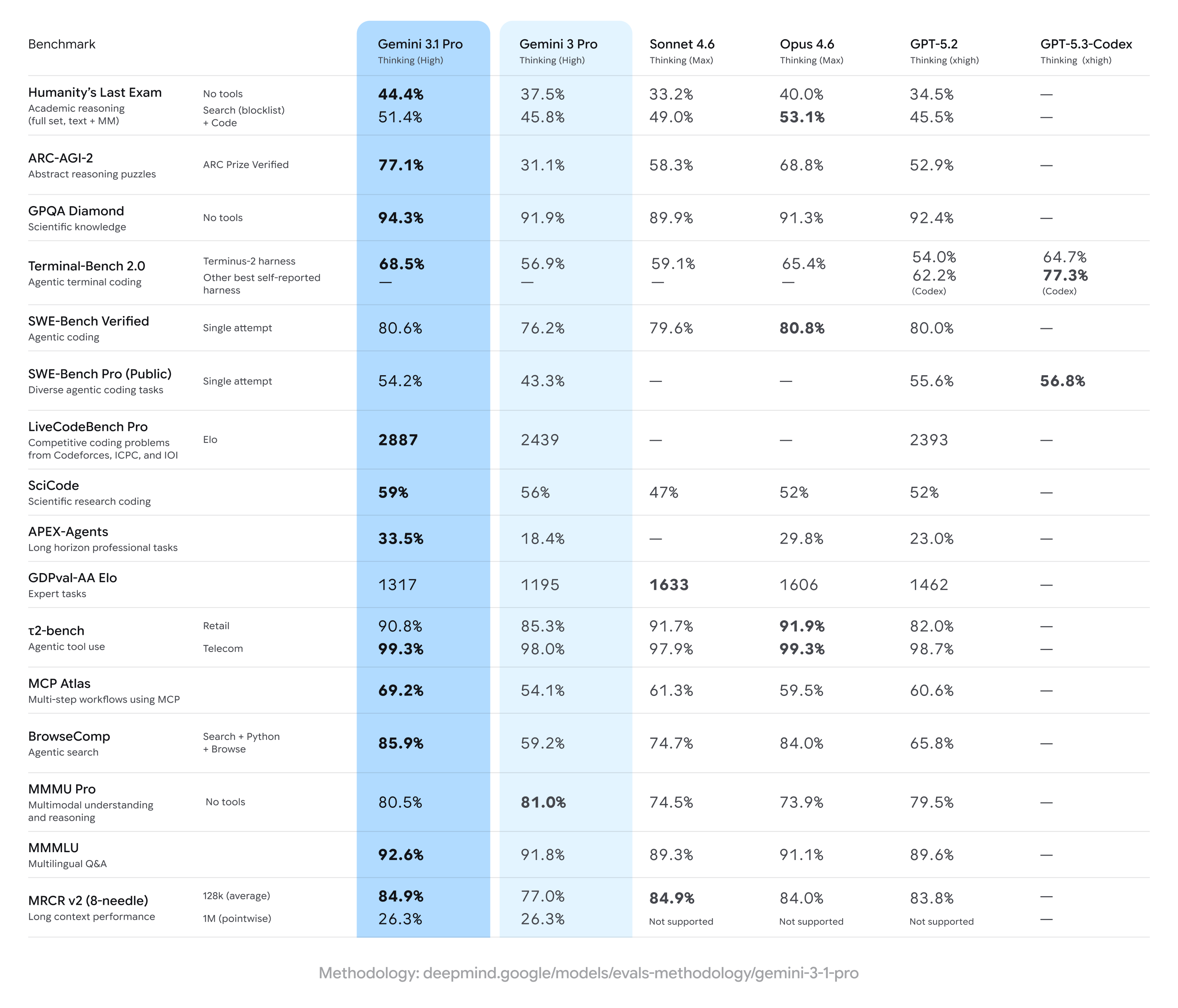
- ARC-AGI-2 (абстрактное рассуждение / многошаговые научные головоломки): Отчеты по Gemini 3.1 Pro показывают существенное улучшение по сравнению с предыдущими версиями Gemini 3 Pro; один набор сообществных тестов указал на более чем двукратное улучшение на ARC-AGI-2 по сравнению с базовой линией предыдущей Gemini 3 Pro в кратких сфокусированных тестах. Конкретные сообщенные оценки (тесты сообщества) ставят Gemini 3.1 Pro на уровне примерно 77,1% на некоторых агрегатах ARC-стиля (публичная отчетность).
- GPQA Diamond и бенчмарки уровня аспирантуры по наукам: Данные указывают, что Gemini 3.1 Pro достигла рекордных высот на GPQA Diamond (бенчмарк вопросов и ответов уровня аспирантуры), превзойдя более ранние модели Gemini и установив новый максимум для семейства в независимых запусках. Эти достижения отражают улучшенную настройку цепочки рассуждений и пошагового планирования.
- «Humanity’s Last Exam» с включенными инструментами (многоинструментальные, обоснованные рассуждения): В прямых сравнениях с Claude Opus 4.6 от Anthropic, Claude достиг 53,1% на этом сложном бенчмарке с включенными инструментами, в то время как Gemini 3.1 Pro показала 51,4% в той же серии тестов — показывая, что Gemini близка, но не на вершине именно в этом экзамене с многими инструментами.
- Бенчмарки по кодингу и терминалу (Terminal-Bench 2.0, SWE-Bench Pro): Специализированные бенчмарки по кодированию показали большую дивергенцию. На Terminal-Bench 2.0 с определенными хранилищами запуска варианты GPT-5.3-Codex набрали около 77,3% против примерно 68,5% у Gemini 3.1 Pro в тех же сравнениях. В публично сообщенных результатах SWE-Bench Pro Gemini 3.1 Pro набрала около 54,2% против 56,8% у GPT-5.3-Codex — ближе, но у семейства Codex от OpenAI сохраняется преимущество в специализированных задачах программирования в этих запусках.
- GDPval-AA Elo (рейтинг экспертных задач): В агрегированном рейтинге в стиле Elo по экспертным задачам варианты Claude Sonnet/Opus набрали выше (например, ~1606–1633 очков), в то время как один публичный отчет поместил Gemini 3.1 Pro на уровне ~1317 очков в том же наборе данных — указывая на пространство для улучшения в некоторых узких экспертных доменах.
Результаты реальных испытаний и практические тесты
Практические обзоры аналитиков показывают, что Gemini 3.1 Pro особенно сильна в:
- Суммировании длинного контекста и синтезе множества документов, где окно в 1M токенов избегает артефактов, связанных с чанкингом.
- Задачах мультимодального понимания, где привязка изображений к тексту улучшает извлечение фактов.
- Агентной автоматизации (например, координация простых цепочек инструментов) — испытания в Antigravity демонстрируют, что многоагентная оркестрация задач осуществима с артефактами, записывающими каждый шаг.
Где Gemini 3.1 Pro все ещё отстает (что говорят цифры)
Ни одна модель не лучшая во всем. Независимые комментарии и тесты сообщества выделяют конкретные пробелы:
- Бенчмарки по программной инженерии и сопровождению кода (SWE-Bench Pro и подобные) — Gemini 3.1 Pro уступает конкуренту (Claude Opus 4.6 от Anthropic) в задачах, которые испытывают практические способности в программной инженерии: крупные рефакторинги, триаж багов в «шумных» кодовых базах и некоторые типы автоматического исправления программ. Иными словами, для повседневного сопровождения инженерии специализированные модели все еще сохраняют преимущество в ряде тестовых стендов.
- Микрозадачи, чувствительные к задержке — поскольку Gemini 3.1 Pro настроена на глубину, задачи, требующие ультра-низкой задержки и высокой пропускной способности (например, микроинференс для легковесных разговорных интерфейсов), могут лучше обслуживаться «Flash» или другими оптимизированными вариантами в семействе Gemini.
Какова цена Gemini 3.1 Pro?
Доступ к Gemini 3.1 Pro возможен двумя способами — потребительская подписка или API для разработчиков — и цены различаются.
- Потребительский (приложение Gemini / Google AI Pro): Доступ к Gemini 3.1 Pro включен в подписку Google AI Pro, которая в США стоит $19.99 / месяц (Google также предлагает более низкий уровень «AI Plus» и более высокий «AI Ultra»). Google.
- Разработчик / API (по токенам): Если вы вызываете модели Gemini через API разработчика Gemini/AI, цена тарифицируется по токенам. Для превью Gemini 3.x Pro опубликованные цены для разработчиков примерно: $2.00 за 1M входных токенов и $12.00 за 1M выходных токенов для стандартного диапазона (≤200k запросов) — с более высокими уровнями (например, $4/$18 за 1M) для очень больших контекстов. (См. таблицу цен Gemini API для всех деталей и пакетного ценообразования.)
- Если вы используете Gemini 3.1 Pro через CometAPI:
| Цена Comet (USD / M токенов) | Официальная цена (USD / M токенов) |
|---|---|
| Ввод:$1.6/M; Вывод:$9.6/M | Ввод:$2/M; Вывод:$12/M |
Цена потребительской подписки (приложение Gemini)
Для пользовательских планов внутри приложения Gemini Google структурирует уровни, которые ограничивают доступ к вариантам моделей и дополнительным функциям: Google AI Pro и Google AI Ultra. Цены варьируются по рынкам и валютам; опубликованные примеры показывают Google AI Pro за $19.99/месяц (с промо-периодами) и ступенчатое ценообразование по валютам на странице продукта (включая пробные предложения и краткосрочные сниженные ставки). AI Ultra включает более высокий доступ (например, приоритет к новым инновациям, большие кредиты на генерацию видео) за более высокую ежемесячную плату. Эти потребительские планы конкурентоспособны с другими премиальными потребительскими подписками на ИИ и призваны дать отдельным продвинутым пользователям или небольшим командам доступ к возможностям 3.1 Pro без интеграции через API.
Практические советы по промптам и использованию (что бы я делал)
Используйте это, чтобы получать надежные, воспроизводимые результаты:
-
Явный планировщик шагов
Шаблон промпта:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.
Это задействует более сильное пошаговое выполнение 3.1 Pro и дает контрольные точки. -
Структурированный вывод со схемами
Попросите JSON со схемой иstrict: true. Поскольку 3.1 Pro надежнее выдает длинные, соответствующие схеме ответы, вы получите более крупные единичные ответы, которые можно парсить далее по конвейеру. -
«Сэндвич» проверки инструментов
При вызове внешних инструментов (API, раннеры кода) попросите модель выдать: план → точный вызов инструмента (удобно копировать/вставлять) → шаги валидации. Затем проверьте шаги валидации вне модели, прежде чем продолжать. -
Осторожность с доверием к одному шагу
Даже если модель пишет идеально выглядящий код или команды, выполняйте независимую проверку (тесты, линтеры, запуск в «песочнице») — особенно для агентных/автономных действий.
Практика с Gemini 3.1 Pro
Кейc 1: Ассистент исследований с длинным контекстом (NotebookLM / Deep Research)
Цель: Оценить способность модели синтезировать 10–50 длинных документов (например, отчеты, белые книги) в многостраничное управленческое резюме со ссылками и пунктами действий.
Настройка: Подайте корпус общим объемом 200k–800k токенов; поставьте задачу получить 2–4-страничное резюме с явными цитатами и рекомендациями «следующих шагов». Используйте повторяемый шаблон промпта и измеряйте время, использование токенов (стоимость) и фактическую точность.
Результаты: Более быстрое насквозь суммирование с меньшим количеством артефактов чанкинга по сравнению со старыми моделями, более высокая точность цитирования в резюме и улучшенная согласованность на масштабе — ценой значительного расхода токенов (заложите бюджет). Бенчмарки и практические тесты показывают, что Gemini 3.1 Pro превосходит в синтезе множества документов благодаря окну в 1M токенов.
Кейc 2: Агентный кодовый ассистент (Antigravity + GitHub Copilot)
Цель: Измерить сокращение времени выполнения многошаговых разработческих задач (например, реализация функции в нескольких файлах, запуск тестов, исправление упавших тестов).
Настройка: Используйте Antigravity или GitHub Copilot в превью с выбранной Gemini 3.1 Pro. Определите воспроизводимые задачи (создание issue → реализация → запуск тестов), логируйте шаги и артефакты агента и сравните с базовой линией «только человек».
Результаты: Улучшенная оркестрация многошаговых задач (запись артефактов, автоматическое предложение кандидатов патчей), лучшее многофайловое рассуждение по сравнению с предыдущей Gemini 3 Pro и измеримая экономия времени на рутинной работе над фичами. Специализированные задачи низкоуровневой отладки систем всё ещё могут больше подходить специализированным моделям, ориентированным на код (сообщество показывает разрыв относительно некоторых вариантов GPT-Codex на ряде терминальных бенчмарков).
Кейc 3: Мультимодальная проверка юридических/медицинских документов
Цель: Использовать модель для загрузки смешанного корпуса (сканированные PDF, изображения, аудио-транскрипты), извлечения ключевых фактов и составления матрицы рисков и приоритезированных действий.
Настройка: Предоставьте набор данных со сканированными изображениями и OCR-текстом, а также поддерживающим аудио. Измеряйте точность извлечения именованных сущностей, уровень ложноположительных, и способность модели ссылаться на исходные артефакты.
результаты: Более сильные интегрированные рассуждения по модальностям и более отслеживаемый вывод (возможность указать изображение / страницу / временную метку аудио, подтверждающие утверждение). Длинное контекстное окно снижает потребность в ручном чанкинге и кросс-ссылках. Однако в регулируемых доменах выводы должны верифицироваться экспертами предметной области, а также следует использовать конвейер обоснования/проверки.
Первые впечатления (что ощущается по-другому)
- Более глубокие пошаговые рассуждения. Задачи, которые раньше требовали нескольких итераций — например, синтез множества документов, многошаговая математика/логика — теперь чаще завершаются за меньшее число проходов и с более понятным стилем вывода цепочки рассуждений (без раскрытия внутреннего инструктивного текста). Это главный акцент, на котором делал упор Google.
- Более длинные, качественные структурированные выводы. JSON и длинные автоматизации стали более согласованными и часто заметно длиннее (некоторые пользователи сообщали о размерах вывода гораздо больше, чем у 3.0). Это делает модель отличной для задач-«генераторов», где нужен один большой пакет. Будьте готовы обрабатывать более крупный вывод и стриминг.
- Более эффективная работа с токенами/контекстом. Улучшенная эффективность по токенам и более «приземленное, фактически согласованное» поведение в сценариях с использованием инструментов. Это выражается в меньшем числе галлюцинаций при коротких фактических поисках.
Итоговый анализ: стоит ли внедрять Gemini 3.1 Pro сейчас?
Gemini 3.1 Pro представляет собой значимый шаг вперед в семействе Gemini с доказуемыми улучшениями в рассуждениях, кодинге и агентных бенчмарках — подкрепленный опубликованной карточкой модели Google и независимыми трекерами, фиксирующими большие скачки на отдельных лидербордах. Для команд, которым нужны продвинутые рассуждения, координация инструментов агентами или длинноконтекстные мультимодальные возможности, 3.1 Pro — убедительный кандидат.
Разработчики уже могут получить доступ к Gemini 3.1 Pro через CometAPI. Для начала изучите возможности модели в Playground и обратитесь к руководству по API за подробными инструкциями. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предлагает цену значительно ниже официальной, чтобы упростить интеграцию.
Готовы начать? → Зарегистрируйтесь для Gemini 3.1 Pro уже сегодня!
Если хотите больше советов, гайдов и новостей об ИИ, подписывайтесь на нас в VK, X и Discord!