

3 марта 2026 года Google представила Gemini 3.1 Flash-Lite, новейшего представителя семейства Gemini 3, специально разработанного как высокопроизводительный, низколатентный и экономичный движок для задач разработчиков и предприятий. Google позиционирует Flash-Lite как «самую быструю и экономичную» модель в линейке Gemini 3: облегчённый вариант, призванный обеспечивать потоковые взаимодействия, крупномасштабную фоновую обработку и высокочастотные продукционные задачи (например, перевод, извлечение, генерация UI и массовая классификация) по значительно более низкой цене, чем у её Pro-версий.
Ниже мы разбираем, что такое Flash-Lite.
Что такое Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite — участник семейства Google Gemini 3, который сознательно обменивает часть максимальной глубины рассуждений на скорость и экономичность. Он нативно мультимодален в рамках линии Gemini (может принимать текст, изображения и другие модальности на вход), но настроен и развернут специально для максимизации пропускной способности по токенам в секунду и существенного снижения тарификации за токен для нагрузок, требующих быстрого, повторяющегося вывода, а не максимальной «когнитивной» глубины. Модель описывается как производная от архитектуры 3.1 Pro, но оптимизированная под пропускную способность, задержки и стоимость.
Ключевые инженерные компромиссы
Маркировка «Lite» указывает на инженерный акцент модели:
- Пропускная способность важнее «тяжёлого» рассуждения: Flash-Lite намеренно сокращает вычисления на токен, чтобы обеспечить более быстрое время до первого токена (TTFT) и устойчивую скорость вывода. Это делает модель идеальной для конвейеров, где каждый запрос должен обслуживаться быстро и в масштабе (например, системы безопасности, ассистенты реального времени, генерация в высоких объёмах).
- Экономичность для больших объёмов: За счёт снижения вычислений на токен модель может предлагаться по более низким ценам за миллион токенов, что снижает предельную стоимость в крупномасштабных приложениях (например, миллионы–миллиарды токенов в месяц). Превью-цены Google демонстрируют значительную разницу по сравнению с уровнем Pro.
- Качество, настроенное под прикладные задачи: По ранним сводным оценкам, Flash-Lite сохраняет сильные результаты в стандартной классификации, мультиязычности и многих мультимодальных задачах, но она не позиционируется как превосходящая Pro на самых сложных бенчмарках многошагового рассуждения или генерации кода, где критична глубина.
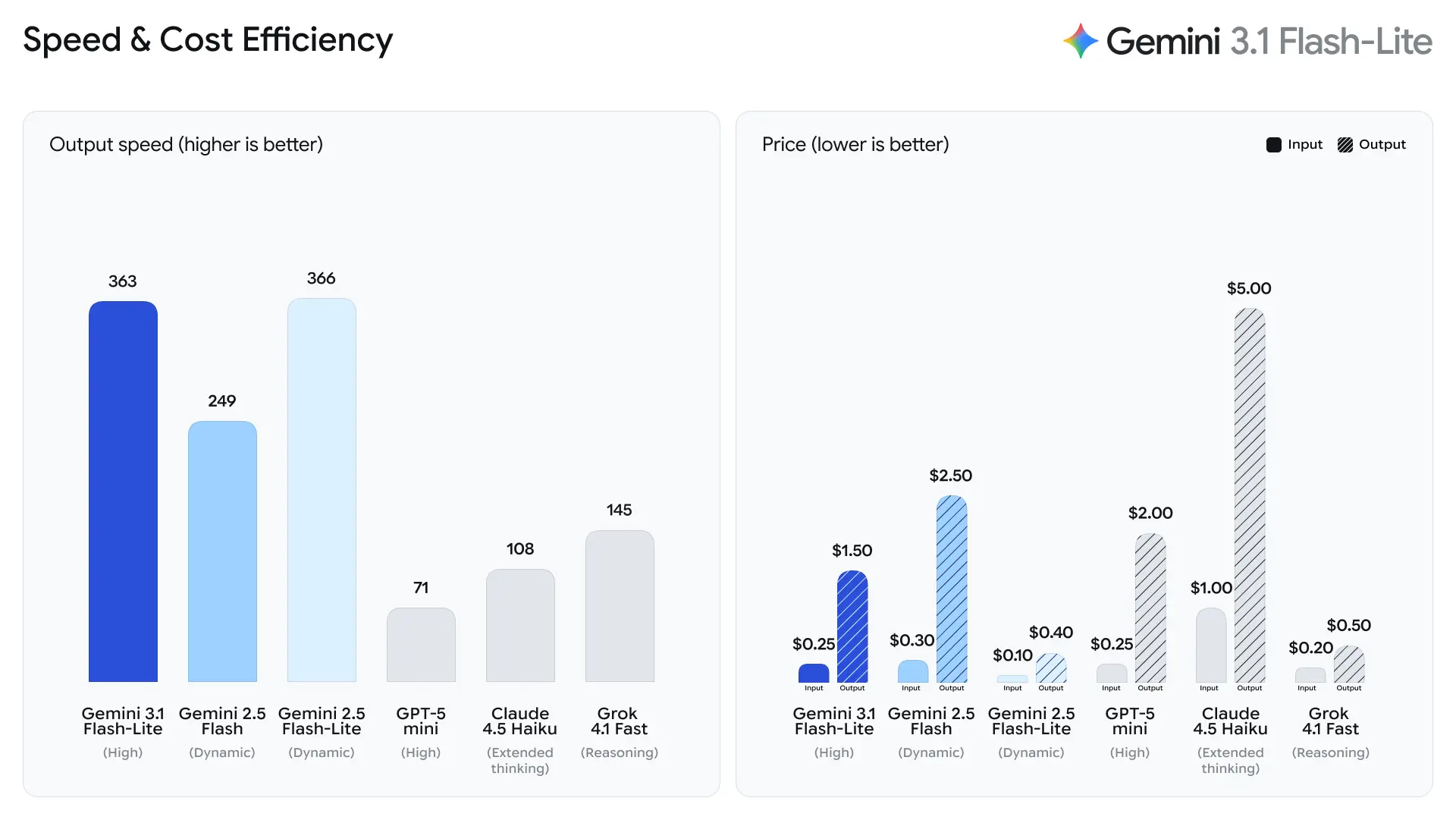
Эти рабочие нагрузки требуют надёжного результата и высокой пропускной способности, но не всегда нуждаются в сложных многошаговых рассуждениях флагманских моделей.
Ключевые возможности Gemini 3.1 Flash-Lite
1. Низкая задержка и быстрое время до первого токена
Google подчёркивает время до первого токена ответа как ключевую метрику для Flash-Lite. Компания сообщает о ~2.5× более быстром времени до первого токена по сравнению с Gemini 2.5 Flash и до 45% более быстром темпе генерации вывода — улучшениях, которые напрямую влияют на воспринимаемую отзывчивость для конечных пользователей и на затраты бэкенд-систем по пропускной способности. Эти приросты делают Flash-Lite хорошо подходящим для интерактивных функций (например, чат-боты, встроенные в приложения) и конвейеров с высоким QPS, где важны микросекунды.
Это улучшение существенно повышает эффективность приложений реального времени, таких как:
- разговорный ИИ
- поисковые ассистенты на базе ИИ
- интерактивные чат-боты
- сервисы синхронного перевода
Снижение задержки улучшает пользовательский опыт, сокращая время ожидания и делая взаимодействия более плавными.
2. Экономичное ценообразование по токенам
Затраты на вывод ИИ часто рассчитываются по токенам, что делает цены критически важными для крупномасштабных развёртываний.
Gemini 3.1 Flash-Lite вводит высококонкурентную структуру ценообразования:
| Тип токена | Цена |
|---|---|
| Входные токены | $0.25 за 1M токенов |
| Выходные токены | $1.50 за 1M токенов |
Это означает снижение по сравнению с предыдущими моделями Flash, делая модель привлекательной для организаций с большими нагрузками.
Для сравнения:
| Модель | Цена за вход | Цена за выход |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
Такая ценовая стратегия позволяет разработчикам масштабировать ИИ без драматического роста операционных затрат.
Если вы ищете ещё более выгодную цену, то Gemini Flash-Lite предлагает скидку 20% на CometAPI.
3. «Уровни мышления» (управляемая глубина вывода)
Gemini 3.1 Flash-Lite включает возможность «уровней мышления» — настраиваемый разработчиком регулятор, который инструктирует модель предпочитать более быстрые, поверхностные вычисления для тривиальных задач и более глубокие рассуждения для сложных. Это важно на практике, поскольку позволяет динамически балансировать стоимость/задержку для каждого запроса без переключения моделей.
Разработчики могут настраивать глубину рассуждений модели под сложность задачи. Уровни мышления: поддерживаются четыре уровня — Minimal, Low, Medium и High.
Этот динамический подход позволяет приложениям оптимизировать использование ресурсов, сохраняя качество там, где это важно. Практическая стратегия примерно следующая:
- Minimal/Low: подходит для высококонкурентных, но логически простых задач, таких как перевод, классификация и анализ тональности; максимальный приоритет скорости и минимальной стоимости.
- Medium: подходит для большинства продукционных задач, обеспечивая баланс качества и эффективности.
- High: подходит для задач, требующих глубоких рассуждений, таких как генерация пользовательских интерфейсов, создание симуляций и выполнение сложных инструкций.
4. Мультимодальные возможности с небольшим «футпринтом»
Хотя Flash-Lite оптимизирован под скорость и стоимость, он сохраняет мультимодальные основы линии Gemini 3: способен принимать изображения на вход для классификации или лёгкого мультимодального рассуждения, когда это требуется кейсом — но разработчикам стоит ожидать, что экономичный дизайн предпочитает короткие, ограниченные мультимодальные операции, а не очень большие, «тяжёлые» по изображениям рабочие процессы. Как и другие модели Gemini, Gemini 3.1 Flash-Lite поддерживает мультимодальные входы, позволяя разработчикам обрабатывать различные типы данных.
Поддерживаемые входы включают:
- Текст
- Изображения
- Видео
- Аудио
- PDF-файлы
Способность модели анализировать несколько типов информации открывает новые сценарии, такие как:
- автоматизированная обработка документов
- извлечение визуальных данных
- мультимедийная суммаризация
Ранние модели Gemini также демонстрировали сильные мультимодальные способности рассуждения по визуальным и знаниевым бенчмаркам.
Результаты производительности — реальные цифры и что они означают
Анонс Google и продуктовая документация приводят несколько бенчмарк-метрик, призванных помочь покупателям понять, где Flash-Lite находится в экосистеме.
Метрики скорости для разработчиков
- 2.5× быстрее время до первого токена ответа по сравнению с Gemini 2.5 Flash (по внутренним данным Google).
- На 45% быстрее генерация вывода по сравнению с Gemini 2.5 Flash.
Это инженерные метрики производительности, а не оценка качества людьми; они отражают улучшения в микросхеме выполнения, батчинге и оптимизациях инференс-стека, снижающих задержки для коротких ответов. Более быстрое появление первого токена снижает воспринимаемую задержку в интерактивных приложениях и увеличивает общую пропускную способность на сервер, что может снизить суммарные вычислительные затраты при том же QPS.
Токенов в секунду (t/s) и пропускная способность
Согласно данным тестов Artificial Analysis, 3.1 Flash-Lite достиг скорости вывода 388.8 токенов в секунду (медиана для моделей в той же ценовой категории составляет лишь 96.7 токена/секунду). Эта скорость — одна из лучших среди моделей своего класса.
Однако Artificial Analysis также указала на проблему: задержка первого токена (TTFT) у 3.1 Flash-Lite составляет 5.18 секунды, что относительно много для инференс-моделей в той же ценовой категории (медиана — 1.82 секунды). Кроме того, модель сгенерировала 53 миллиона токенов в процессе оценки, что заметно выше среднего уровня в 20 миллионов. Это означает, что если ваш сценарий очень чувствителен к задержке первого токена или имеет строгие требования к лаконичности вывода, возможно, потребуется оптимизировать уровень мышления и промпты.
Оценки на бенчмарках рассуждения и фактуальности
Google включила кросс-модельные сравнения, показывающие, что Gemini 3.1 Flash-Lite демонстрирует сильные результаты по сравнению с аналогами и предыдущими вариантами Gemini на агрегированных задачах рассуждения/фактуальности:
- Рейтинг Elo на Arena.ai: Gemini 3.1 Flash-Lite, по сообщениям, достиг Elo 1432 в таблице лидеров Arena — композитного head-to-head рейтинга, показывающего конкурентоспособность в прямых сравнениях.
- GPQA Diamond: 86.9% (показатель надёжности ответов на вопросы).
- MMMU Pro: 76.8% (мультимодальная/многозадачная метрика, используемая некоторыми лабораториями).
- LiveCodeBench (способности к кодингу): 72.0%
- CharXiv Reasoning (графическое рассуждение): 73.2%
- Video-MMMU (понимание видео): 84.8%
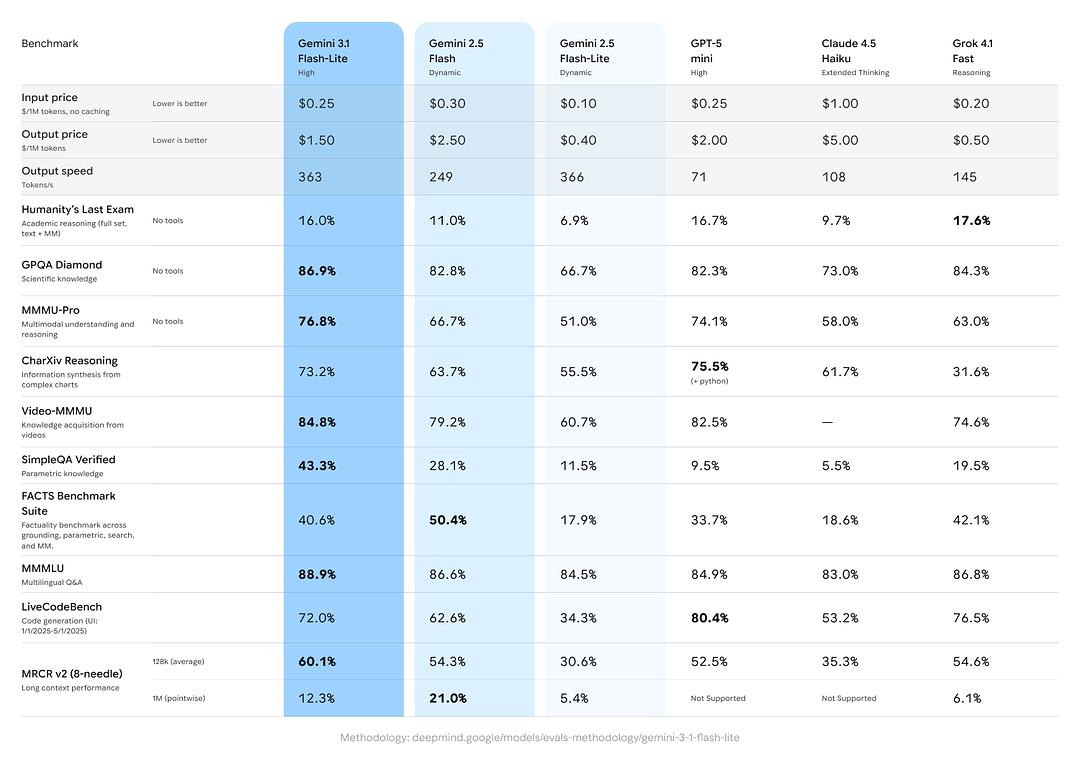
Gemini 3. boom 1 Flash-Lite превосходит более раннюю Gemini 2.5 Flash по ряду этих метрик, одновременно обеспечивая гораздо лучшую скорость/стоимость.
Сценарии использования, подходящие для Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite создавался вокруг ясного набора прикладных нагрузок, где решающими являются высокая пропускная способность и низкая стоимость за токен:
Высокочастотные разговорные агенты и потоковые интерфейсы
Чат-боты в реальном времени, потоки транскрипции + перевода и совместные интерфейсы, которые отображают частичные ответы по мере генерации модели, выигрывают от потокового вывода токенов и малого времени до первого токена у Flash-Lite.
Массовая обработка данных (RAG, конвейеры преобразований)
Массовая загрузка документов: извлечение сущностей, присвоение метаданных, классификация и перевод для миллионов документов — Gemini 3.1 Flash-Lite снижает стоимость инференса, обеспечивая приемлемую точность для шаблонных или правил-ориентированных ответов.
Пограничные или фоновые вычисления
Нагрузки, которые непрерывно обрабатывают входящую телеметрию или неструктурированные данные (например, конвейеры классификации для модерации контента, автоматическая генерация отчётов), хорошо подходят, поскольку Gemini 3.1 Flash-Lite минимизирует стоимость за единицу.
Инструменты для разработчиков и пакетное автодополнение кода
Для функций вроде многофайлового «скелетирования», крупномасштабного линтинга кода и генерации шаблонов в больших объёмах преимущества скорости Gemini 3.1 Flash-Lite снижают задержку и стоимость для инструментов разработчика, где максимальная глубина рассуждений не является обязательной.
Сравнение Gemini 3.1 Flash-Lite с другими моделями Gemini и конкурентами
Внутри семейства Gemini
- Gemini 3.1 Pro: максимальные способности на сложных рассуждениях и многошаговом планировании; заметно дороже и медленнее по токену, но лучше для глубоких, нюансных задач.
- Gemini 3.1 Flash (не Lite): нацелен на срединный баланс между пропускной способностью и возможностями — Flash-Lite оптимизирован ещё дальше по вычислительному стеку ради пропускной способности.
Против конкурирующих «быстрых» моделей
Gemini 3.1 Flash-Lite превосходит или сопоставим с несколькими быстрыми/мини-моделями по многим метрикам пропускной способности и качества — однако независимые аналитики предупреждают, что прямые сравнения чувствительны к методологии оценки и выбору датасетов. Ожидайте, что Gemini 3.1 Flash-Lite будет крайне конкурентоспособным по пропускной способности и стоимости, оставаясь ближе к средней группе по самым высоким метрикам рассуждений.
Вывод — место Flash-Lite в стеке ИИ
Gemini 3.1 Flash-Lite — тщательно спроектированное предложение: эффективный, ориентированный на пропускную способность представитель семейства Gemini 3, позволяющий командам обменивать часть вычислений на пример на драматические улучшения в задержке и стоимости. Для бизнеса и разработчиков, строящих высокообъёмные конвейеры — переводы, пакетная обработка, потоковые интерфейсы и задачи умеренной сложности с агентами — Flash-Lite является разумным базовым движком. Для организаций, которым нужна максимально возможная точность рассуждений, модели Pro остаются правильным выбором.
Если ваша рабочая нагрузка состоит преимущественно из множества коротких, повторяемых инференсов или вам нужен быстрый потоковый вывод в крупном масштабе, имеет смысл пилотировать Flash-Lite. Если же ваш кейс завязан на глубокие многошаговые рассуждения, планируйте гибридный подход: маршрутизируйте потоковые запросы на Flash-Lite и эскалируйте сложные, высокоценные запросы на модели Pro.
Разработчики уже могут получить доступ к Gemini 3.1 Flash Lite через CometAPI. Для начала изучите возможности модели в Playground и обратитесь к руководству по API за подробными инструкциями. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предлагает цену значительно ниже официальной, чтобы помочь вам с интеграцией.
Готовы начать?→ Зарегистрируйтесь для Gemini 3.1 Flash-Lite уже сегодня!
Если хотите получать больше советов, гайдов и новостей об ИИ, следите за нами в VK, X и Discord!