API аудио GPT-4o: Единый /chat/completions расширение конечной точки, которое принимает аудиоданные (и текстовые) в формате Opus и возвращает синтезированную речь или транскрипты с настраиваемыми параметрами (модель =gpt-4o-audio-preview-<date>, speed, temperature) для пакетного и потокового голосового взаимодействия.
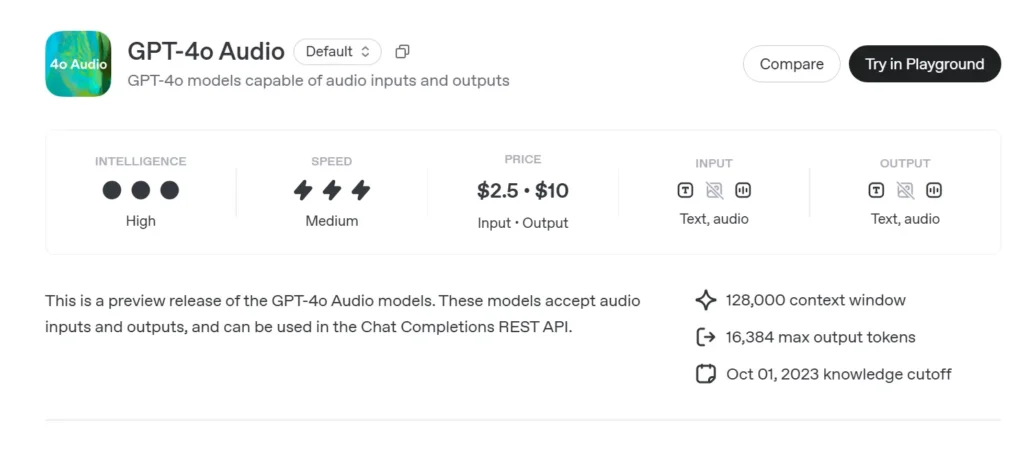
Основная информация о GPT-4o Audio
Предварительный просмотр аудио GPT-4o (gpt-4o-audio-preview-2025-06-03) — новейшая разработка OpenAI большая языковая модель, ориентированная на речь доступны через стандарт API завершения чата а не сверхнизкий канал Realtime. Созданный на той же основе «omni», что и GPT-4o, этот вариант специализируется на высококачественный речевой ввод и вывод для пошаговых разговоров, создания контента, инструментов доступности и рабочих процессов агентов, не требующих миллисекундного времени. Он наследует все сильные стороны текстового обоснования моделей класса GPT-4, добавляя сквозная речь-речь (S2S) трубопроводы, детерминированные вызов функции, И новый speed параметр для управления скоростью голоса.
Основной набор функций GPT-4o Audio
• Унифицированная обработка речи в речь – Аудио преобразуется напрямую в семантически насыщенные токены, обосновывается и повторно синтезируется без внешних служб STT/TTS, что дает постоянный тембр голоса, просодия и сохранение контекста.
• Улучшенное выполнение инструкций – тюнинг на июнь 2025 г. +19 п.п. сдал-1 по задачам с голосовыми командами по сравнению с базовым уровнем GPT-2024o от мая 4 года, что позволило снизить галлюцинации в таких областях, как поддержка клиентов и составление контента.
• Стабильный вызов инструмента – Модель выводит структурированный JSON который соответствует схеме вызова функций OpenAI, позволяя запускать внутренние API (поиск, бронирование, платежи) с помощью >95 % точность аргумента.
• speed Параметр (0.25–4×) – Разработчики могут модулировать воспроизведение речи для медленного темпа обучения, обычного повествования или быстрого «слухового просмотра» режимов, без ресинтез текста извне.
• Очередь с учетом прерываний – Хотя предварительная версия не так сильно зависит от задержки, как вариант в реальном времени, она поддерживает частичная потоковая передача: токены выдаются сразу после вычисления, что позволяет пользователям при необходимости прервать процесс заранее.
Техническая архитектура GPT-4o
• Односекционный трансформатор – Как и все производные GPT-4o, аудиопревью использует унифицированный кодер-декодер где текстовые и акустические маркеры проходят через идентичные блоки внимания, способствуя кросс-модальному заземлению.
• Иерархическая аудиотокенизация – Raw 16 кГц PCM → патчи log-mel → грубые акустические коды → семантические токены. Это многоступенчатое сжатие достигает 40–50-кратное сокращение пропускной способности сохраняя при этом нюансы и позволяя создавать многоминутные клипы в каждом контекстном окне.
• Квантованные веса NF4 – Вывод подается в 4-битный обычный с плавающей точкой точность, сокращение памяти графического процессора вдвое по сравнению с fp16 и поддержание 70+ потоковых RTF (в реальном времени) на узлах A100-80 ГБ.
• Потоковое внимание и кэширование KV – Встроенные вращающиеся скользящие окна сохраняют контекст на протяжении ~30 с речи, сохраняя при этом О(Л) использование памяти, идеально подходит для редакторов подкастов или вспомогательных средств чтения.
Версионирование и именование — Предварительный просмотр трека с датированными сборками
| идентификатор | Канал | Цель | Дата выпуска | Стабильность |
|---|---|---|---|---|
| gpt-4o-audio-preview-2025-06-03 | API завершения чата | Пошаговые аудиовзаимодействия, агентские задачи | Июнь 03 2025 | предварительный просмотр (обратная связь приветствуется) |
Ключевые элементы названия:
- gpt-4o – Омнимультимодальное семейство.
- аудио – Оптимизирован для речевого использования.
- предварительный просмотр – API-контракт может развиваться; пока не GA.
- 2025-06-03 – Моментальный снимок обучения и развертывания для воспроизводимости.
Как вызвать API GPT-4o Audio из CometAPI
GPT-4o Audio API Цены на API в CometAPI:
- Входные токены: $2 / млн токенов
- Выходные токены: $8 / M токенов
Необходимые шаги
- Войти в cometapi.com. Если вы еще не являетесь нашим пользователем, пожалуйста, сначала зарегистрируйтесь.
- Получите ключ API-интерфейса для доступа к учетным данным. Нажмите «Добавить токен» в API-токене в персональном центре, получите ключ токена: sk-xxxxx и отправьте.
- Получите URL этого сайта: https://api.cometapi.com/
Методы использования
- Выберите "
gpt-4o-audio-preview-2025-06-03” конечная точка для отправки запроса и установки тела запроса. Метод запроса и тело запроса получены из API doc нашего веб-сайта. Наш веб-сайт также предоставляет тест Apifox для вашего удобства. - Заменять с вашим реальным ключом CometAPI из вашей учетной записи.
- Введите свой вопрос или запрос в поле «Контент» — на него ответит модель.
- . Обработайте ответ API, чтобы получить сгенерированный ответ.
Информацию о доступе к моделям в Comet API см. API документ.
Информацию о ценах моделей в Comet API см. https://api.cometapi.com/pricing.
Рабочий процесс API — Завершение чата с аудиочастями и функциональными хуками
- Формат ввода –
audio/*MIME илиbase64WAV-фрагменты, встроенные вmessages[].content. - Параметры вывода –
•mode: "text"→ чистый текст для субтитров.
•mode: "audio"→ возвращает потоковый Полезная нагрузка Opus или µ-law с временными метками. - Вызов функции - Добавить
functions:схема; модель испускаетrole: "function"с аргументами JSON; разработчик выполняет вызов инструмента и при необходимости передает результат обратно. - Rate Control - Задавать
voice.speed=1.25для ускорения воспроизведения; безопасные диапазоны 0.25–4.0. - Ограничения по токенам/аудио – 128 тыс. контекста (~4 мин речи) на момент запуска; 4096 аудиотокенов / 8192 текстовых токена смотря что произойдет первым.
Пример кода и интеграция API
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- Основные моменты::
- модель:
"gpt-4o-audio-preview-2025-06-03" - аудио вставить пользователь сообщение для отправки двоичного потока
- скорость: Элементы управления скорость голоса между медленным (0.5) и быстрым (2.0)
- температура: Остатки креативность против согласованность
Технические индикаторы — Задержка, Качество, Точность
| Метрика | Предварительный просмотр аудио | GPT-4o (только текст) | Delta |
|---|---|---|---|
| Задержка первого токена (1-выстрел) | 1.2 с средний | 0.35 с | +0.85 с |
| MOS (Естественность речи, 5 баллов) | 4.43 | - | - |
| Соблюдение инструкций (голос) | 92% | 73% | +19 п. |
| Точность аргумента вызова функции | 95.8% | 87% | +8.8 п. |
| Коэффициент ошибок в словах (неявный STT) | 5.2% | н / | - |
| Память графического процессора / Поток (A100-80 ГБ) | 7.1 ГБ | 14 ГБ (fp16) | −49% |
Тесты проводились с помощью потоковой передачи Chat Completions, размер пакета = 1.
См. также API реального времени GPT-4o