

OpenAI опубликовала предварительный обзор исследования gpt-oss-safeguard, семейство моделей вывода с открытым весом, разработанное для того, чтобы позволить разработчикам применять своих Политики безопасности на этапе вывода. Вместо того, чтобы предоставлять фиксированный классификатор или механизм модерации «черный ящик», новые модели точно настроены причина из политики, предоставленной разработчиком, выдают цепочку рассуждений (CoT), объясняющую ход рассуждений, и выдают структурированные результаты классификации. Представленная в качестве предварительного исследования, модель gpt-oss-safeguard представлена в виде пары моделей рассуждений:gpt-oss-safeguard-120b и gpt-oss-safeguard-20b—тонко настроенный из семейства gpt-oss и специально разработанный для выполнения задач по классификации безопасности и обеспечению соблюдения политики в процессе вывода.
Что такое gpt-oss-safeguard?
gpt-oss-safeguard — это пара моделей рассуждений с открытым весом, работающих только с текстом, которые были обучены на основе семейства gpt-oss интерпретировать политику, написанную на естественном языке, и маркировать текст в соответствии с этой политикойОтличительной чертой является то, что политика предоставлено во время вывода (политика как входные данные), не встроенные в статические веса классификаторов. Эти модели предназначены в первую очередь для задач классификации безопасности, например, для модерации с несколькими политиками, классификации контента в рамках нескольких нормативных режимов или проверки соответствия политикам.
Почему это важно
Традиционные системы модерации обычно полагаются на (а) фиксированные наборы правил, сопоставленные с классификаторами, обученными на маркированных примерах, или (б) эвристики/регулярные выражения для определения ключевых слов. gpt-oss-safeguard пытается изменить парадигму: вместо переобучения классификаторов при каждом изменении политики вы предоставляете текст политики (например, политику приемлемого использования вашей компании, условия использования платформы или рекомендации регулирующего органа), и модель анализирует, нарушает ли данный фрагмент контента эту политику. Это обеспечивает гибкость (изменение политики без переобучения) и интерпретируемость (модель выводит свою цепочку рассуждений).
В этом и заключается его основная философия: «Замена запоминания рассуждением, а догадок — объяснением».
Это представляет собой новый этап в обеспечении безопасности контента: переход от «пассивного изучения правил» к «активному пониманию правил».
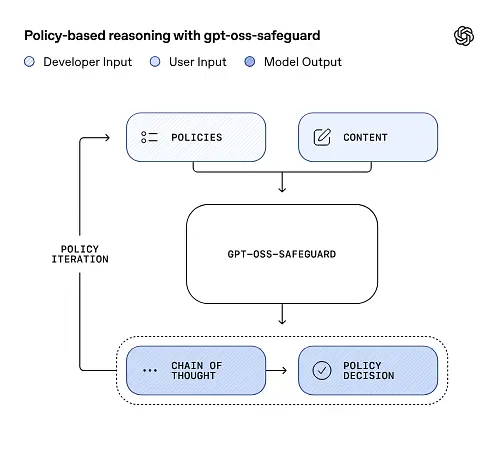
gpt-oss-safeguard может напрямую считывать политики безопасности, определенные разработчиками, и следовать этим политикам для принятия решений во время вывода.
Как работает gpt-oss-safeguard?
Рассуждение на основе политики как входных данных
Во время вывода вы предоставляете две вещи: текст политики и контент кандидата Для маркировки. Модель рассматривает политику как основную инструкцию, а затем выполняет пошаговый анализ, чтобы определить, разрешён ли контент, запрещён или требует дополнительной модерации. В результате модель:
- создает структурированный вывод, который включает заключение (метку, категорию, уверенность) и понятный человеку след рассуждения, объясняющий, почему был сделан этот вывод.
- принимает политику и контент, подлежащий классификации,
- внутренне обдумывает положения политики, используя шаги, подобные цепочке мыслей, и
Например:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
Он ответит:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
Цепочка мыслей (CoT) и структурированные результаты
gpt-oss-safeguard может создавать полную трассировку CoT в рамках каждого вывода. CoT предназначен для проверки: команды по обеспечению соответствия могут узнать, почему модель пришла к тому или иному выводу, а инженеры могут использовать трассировку для диагностики неоднозначности политики или видов сбоев модели. Модель также поддерживает структурированные результаты— например, JSON, содержащий вердикт, нарушенные разделы политики, оценку серьезности и предлагаемые действия по исправлению, что упрощает интеграцию в конвейеры модерации.
Настраиваемые уровни «усилия рассуждения»
Для баланса между задержкой, стоимостью и тщательностью модели поддерживают настраиваемые усилия по рассуждению: низкий / средний / высокийБолее высокие затраты увеличивают глубину цепочки рассуждений и, как правило, приводят к более надёжным, но более медленным и затратным выводам. Это позволяет разработчикам распределять рабочие нагрузки — использовать низкие затраты для стандартного контента и высокие — для пограничных случаев или контента с высоким уровнем риска.
Какова структура модели и какие версии существуют?
Модель семьи и родословной
gpt-oss-safeguard есть после обучения варианты более ранних версий OpenAI gpt-us Открытые модели. Семейство защитных устройств в настоящее время включает два выпускаемых размера:
- gpt-oss-safeguard-120b — модель со 120 миллиардами параметров, предназначенная для высокоточных задач рассуждения, которая по-прежнему работает на одном графическом процессоре объемом 80 ГБ в оптимизированном режиме выполнения.
- gpt-oss-safeguard-20b — модель с 20 миллиардами параметров, оптимизированная для экономичного вывода и периферийных или локальных сред (в некоторых конфигурациях может работать на устройствах с 16 ГБ видеопамяти).
Замечания по архитектуре и характеристики времени выполнения (чего ожидать)
- Активные параметры на токен: Базовая архитектура gpt-oss использует методы, которые сокращают количество параметров, активируемых для каждого токена (сочетание дизайна с плотным и разреженным вниманием / смесью стилей экспертов в родительском gpt-oss).
- На практике класс 120B подходит для отдельных больших ускорителей, а класс 20B предназначен для работы на установках VRAM объемом 16 ГБ в оптимизированном режиме выполнения.
Модели безопасности были не обучены работе с дополнительными биологическими данными или данными кибербезопасностии что анализ наихудших сценариев неправильного использования, проведённый для версии gpt-oss, в целом применим к вариантам с защитой. Модели предназначены для классификации, а не для создания контента для конечных пользователей.
Каковы цели gpt-oss-safeguard?
Цели
- Гибкость политики: позвольте разработчикам определять любую политику на естественном языке и заставляйте модель применять ее без необходимости сбора пользовательских меток.
- Объяснимость: раскрывать обоснования, чтобы можно было проверять решения и повторять политику.
- Доступность: предоставить альтернативу с открытым весом, чтобы организации могли проводить локальную оценку безопасности и проверять внутренние компоненты модели.
Сравнение с классическими классификаторами
Плюсы против традиционных классификаторов
- Переподготовка для внесения изменений в политику не требуется: Если ваша политика модерации изменится, обновите документ политики вместо того, чтобы собирать метки и переобучать классификатор.
- Более богатое рассуждение: Результаты CoT могут раскрыть тонкие взаимодействия политики и предоставить повествовательное обоснование, полезное для рецензентов-людей.
- Возможность настройки: Одна и та же модель может одновременно применять множество различных политик в процессе вывода.
Минусы против традиционных классификаторов
- Предельные значения производительности для некоторых задач: В оценке OpenAI отмечается, что Высококачественные классификаторы, обученные на десятках тысяч размеченных примеров, могут превзойти gpt-oss-safeguard для специализированных задач классификации. Когда целью является точность первичной классификации и у вас есть размеченные данные, специализированный классификатор, обученный на этом распределении, может быть эффективнее.
- Задержка и стоимость: Расчеты с помощью CoT требуют больших вычислительных затрат и выполняются медленнее, чем при использовании облегченного классификатора; это может привести к тому, что конвейеры, основанные исключительно на мерах безопасности, при масштабировании окажутся слишком дорогими.
Короче говоря: gpt-oss-safeguard лучше всего использовать там, где гибкость политики и контролируемость являются приоритетными или когда маркированных данных мало, а также в качестве дополнительного компонента в гибридных конвейерах, не обязательно в качестве готовой замены оптимизированного по масштабу классификатора.
Как показал себя gpt-oss-safeguard в оценках OpenAI?
OpenAI опубликовала базовые результаты в 10-страничном техническом отчёте, обобщающем внутренние и внешние оценки. Ключевые выводы (выбранные, значимые метрики):
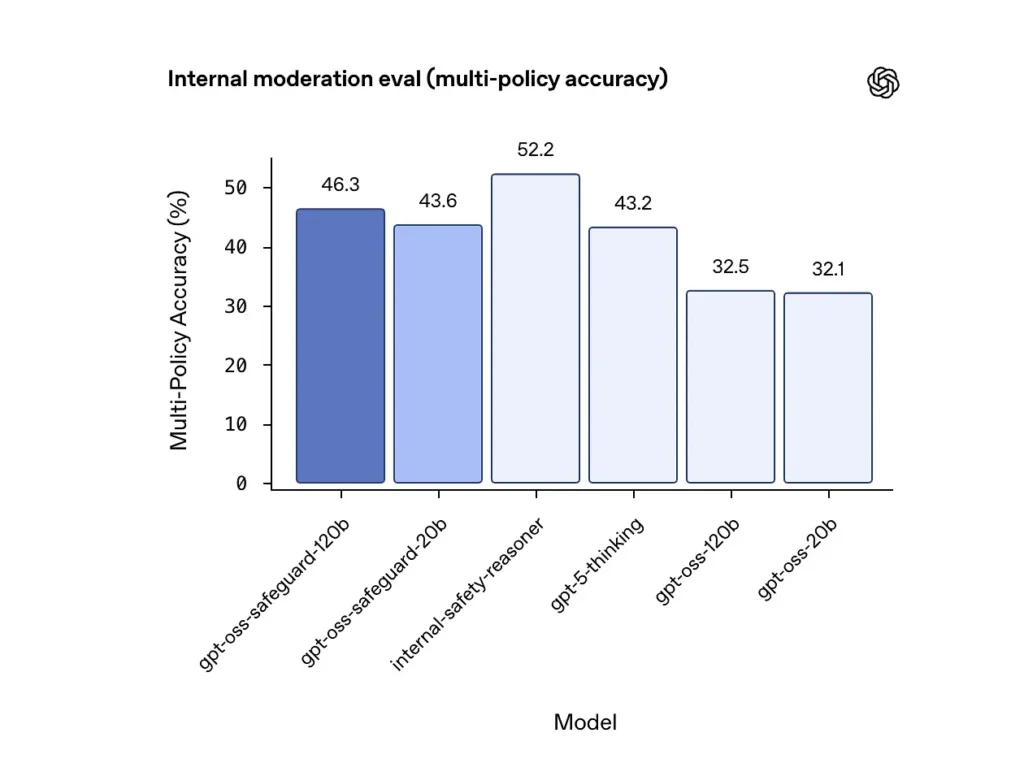
Точность мультиполитики (внутренняя оценка)
OpenAI оценила точность мультиполитики, предоставив модели с разными политики одновременно и считать прогноз правильным только в том случае, если он соответствует золотым меткам по всему ВСЕ политики. Результаты:
- gpt-oss-safeguard-120b: 46.3%. точность при использовании нескольких политик
- gpt-oss-safeguard-20b: 43.6%.
- Для сравнения: gpt-5-мышление: 43.2%; gpt-oss-120b: 32.5%; gpt-oss-20b: 32.1%.
Внутренний ансамбль «безопасности и обоснования» OpenAI набрал 52.2% в том же тесте. Эти показатели показывают, что модели безопасности значительно превосходят базовые модели gpt-oss в задаче с несколькими политиками и даже превзошли более крупный базовый уровень gpt-5-thinking по внутренней метрике с несколькими политиками.
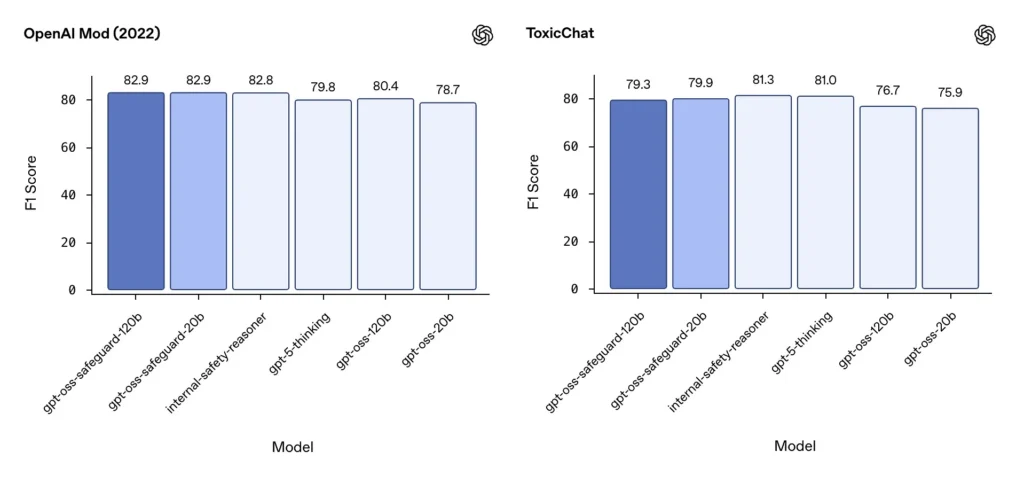
Модерация F1 (внешние бенчмарки)
В наборе данных модерации OpenAI 2022 года и публичном бенчмарке ToxicChat модели gpt-oss-safeguard показали высокие результаты F1:
- OpenAI Mod (2022) F1: gpt-oss-safeguard-120b = 82.9%., gpt-oss-safeguard-20b = 82.9%.
- ToxicChat F1: gpt-oss-safeguard-120b = 79.3%., gpt-oss-safeguard-20b = 79.9%.
По этим показателям gpt-oss-safeguard на некоторых тестах близок или немного отстает от специализированных внутренних систем OpenAI, а в целом опережает не доработанные аналоги gpt-oss.
Наблюдаемые ограничения
OpenAI отмечает два практических ограничения:
- Классификаторы, обученные на больших, маркированных для конкретных задач наборах данных, все еще могут превосходить защитные модели когда единственной целью является точность классификации.
- Затраты на вычисления и задержку: Рассуждения CoT увеличивают время вывода и потребление вычислительных ресурсов, что затрудняет масштабирование до уровня трафика платформы, если только они не используются в сочетании с классификаторами сортировки и асинхронными конвейерами.
Многоязычный паритет
gpt-oss-safeguard демонстрирует производительность, сопоставимую с базовыми моделями gpt-oss на многих языках в тестах в стиле MMMLU, что указывает на то, что тонко настроенные варианты защиты сохраняют широкие возможности рассуждения.
Как команды могут получить доступ к gpt-oss-safeguard и развернуть его?
OpenAI предоставляет весовые коэффициенты для Apache 2.0 и ссылки на модели для загрузки (Hugging Face). Поскольку gpt-oss-safeguard — это модель с открытыми весовыми коэффициентами, локальное и автономное развертывание (рекомендуется для обеспечения конфиденциальности и настройки).
- Скачать вес модели (от OpenAI / Hugging Face) и размещайте их на своих серверах или облачных виртуальных машинах. Apache 2.0 допускает модификацию и коммерческое использование.
- Время выполнения: Используйте стандартные среды выполнения для вывода, поддерживающие большие модели преобразователей (ONNX Runtime, Triton или оптимизированные среды выполнения от вендоров). Среды выполнения, разработанные сообществом, такие как Ollama и LM Studio, уже добавляют поддержку семейств gpt-oss.
- Аппаратные средства: 120 Б обычно требуют графических процессоров с большим объёмом памяти (например, A100 / H100 80 ГБ или шардинг на нескольких ГП), в то время как 20 Б может быть более экономичным и имеет опции, оптимизированные для конфигураций с 16 ГБ видеопамяти. Планируйте ёмкость с учётом пиковой пропускной способности и затрат на оценку с использованием нескольких политик.
Управляемые и сторонние среды выполнения
Если использование собственного оборудования нецелесообразно, CometAPI быстро добавляет поддержку моделей gpt-oss. Эти платформы могут обеспечить более легкое масштабирование, но вновь вводят компромиссы в отношении раскрытия данных третьим лицам. Оцените конфиденциальность, соглашения об уровне обслуживания (SLA) и контроль доступа, прежде чем выбирать управляемые среды выполнения.
Эффективные стратегии модерации с gpt-oss-safeguard
1) Используйте гибридный конвейер (триажер → причина → вынесение решения)
- Слой сортировки: Небольшие и быстрые классификаторы (или правила) отфильтровывают тривиальные случаи. Это снижает нагрузку на дорогостоящую модель безопасности.
- Защитный слой: запустите gpt-oss-safeguard для неоднозначных, высокорисковых или многополитических проверок, где нюансы политики имеют значение.
- Человеческое суждение: Эскалируйте особые случаи и апелляции, сохраняя CoT в качестве доказательства прозрачности. Эта гибридная конструкция обеспечивает баланс между пропускной способностью и точностью.
2) Политическая инженерия (не оперативная инженерия)
- Относитесь к политикам как к программным артефактам: создавайте их версии, тестируйте их на наборах данных и поддерживайте их явную и иерархическую структуру.
- Опишите правила с примерами и контрпримерами. По возможности, включайте инструкции, устраняющие неоднозначность (например, «Если намерение пользователя явно исследовательское и историческое, обозначьте как X; если намерение оперативное и в режиме реального времени, обозначьте как Y»).
3) Динамически настройте усилия по рассуждению
- Используйте низкие усилия для массовой обработки и большие усилия для помеченного контента, обращений или высокоэффективных вертикалей (юридических, медицинских, финансовых).
- Настройте пороговые значения с учетом отзывов людей, чтобы найти оптимальное соотношение цены и качества.
4) Проверьте CoT и обратите внимание на галлюцинаторные рассуждения.
CoT ценен, но может создавать иллюзии: след — это логическое обоснование, сгенерированное моделью, а не истина. Регулярно проверяйте результаты CoT; проверяйте детекторы на наличие галлюцинаций в цитатах или несоответствующих рассуждений. OpenAI документирует галлюцинации в цепочках мыслей как наблюдаемую проблему и предлагает стратегии её устранения.
5) Создание наборов данных на основе работы системы
Регистрируйте решения, принятые в рамках модели, и коррективы, вносимые человеком, для создания маркированных наборов данных, которые могут улучшить классификаторы сортировки или предоставить информацию для переписывания политик. Со временем небольшой, высококачественный маркированный набор данных и эффективный классификатор часто снижают зависимость от полного вывода CoT для рутинного контента.
6) Контролируйте вычисления и затраты; используйте асинхронные потоки
Для приложений с низкой задержкой, ориентированных на потребителя, рассмотрите возможность асинхронных проверок безопасности с краткосрочным консервативным пользовательским интерфейсом (например, временно скрыть контент, ожидающий проверки), вместо выполнения ресурсоемких синхронных проверок безопасности. OpenAI отмечает, что Safety Reasoner использует асинхронные потоки для управления задержкой в производственных сервисах.
7) Учитывайте конфиденциальность и место развертывания
Поскольку весовые коэффициенты открыты, вы можете выполнять вывод полностью локально, чтобы соответствовать строгим требованиям к управлению данными или сократить использование сторонних API, что ценно для регулируемых отраслей.
Вывод:
gpt-oss-safeguard — это практичный, прозрачный и гибкий инструмент для обоснование безопасности на основе политики. Он светит, когда вам нужно. проверяемые решения, связанные с четкой политикой, когда ваши политики часто меняются или когда вы хотите проводить проверки безопасности локально. волшебное решение, которое автоматически заменит специализированные классификаторы большого объёма данных — собственные исследования OpenAI показывают, что специализированные классификаторы, обученные на больших размеченных корпусах, могут превосходить эти модели по чистой точности для узких задач. Вместо этого рассматривайте gpt-oss-safeguard как стратегический компонент: механизм объяснимых рассуждений, лежащий в основе многоуровневой архитектуры безопасности (быстрая сортировка → объяснимые рассуждения → человеческий контроль).
Первые шаги
CometAPI — это унифицированная платформа API, которая объединяет более 500 моделей ИИ от ведущих поставщиков, таких как серия GPT OpenAI, Gemini от Google, Claude от Anthropic, Midjourney, Suno и других, в единый, удобный для разработчиков интерфейс. Предлагая последовательную аутентификацию, форматирование запросов и обработку ответов, CometAPI значительно упрощает интеграцию возможностей ИИ в ваши приложения. Независимо от того, создаете ли вы чат-ботов, генераторы изображений, композиторов музыки или конвейеры аналитики на основе данных, CometAPI позволяет вам выполнять итерации быстрее, контролировать расходы и оставаться независимыми от поставщика — и все это при использовании последних достижений в экосистеме ИИ.
Последняя интеграция gpt-oss-safeguard скоро появится в CometAPI, так что следите за новостями! Пока мы завершаем загрузку модели gpt-oss-safeguard, разработчики могут получить доступ API GPT-OSS-20B и API GPT-OSS-120B через CometAPI, последняя версия модели Всегда обновляется на официальном сайте. Для начала изучите возможности модели в Детская Площадка и проконсультируйтесь с API-руководство для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предложить цену намного ниже официальной, чтобы помочь вам интегрироваться.
Готовы к работе?→ Зарегистрируйтесь в CometAPI сегодня !
Если вы хотите узнать больше советов, руководств и новостей об искусственном интеллекте, подпишитесь на нас VK, X и Discord!