

xAI тихо выпустили Грок 4.1 (17–18 ноября 2025 г.) — целенаправленное обновление Grok 4, которое уделяет первостепенное внимание эмоциональный интеллект, творческое самовыражение и уменьшение галлюцинаций При этом сохраняя предельно чёткую логику предыдущих версий Grok. Игра доступна в двух режимах (Размышление/Неразмышление), была без лишнего шума запущена в начале ноября, показывает лучшие результаты в таблице лидеров на LMArena и доступна на grok.com, в приложениях Grok и через API.
Что такое Грок 4.1?
Grok 4.1 — это постепенный, ориентированный на производство преемник Grok 4: член семейства, построенный на той же масштабной платформе обучения с подкреплением, но доработанный и переобученный с серьёзными оптимизациями после обучения, направленными на стиль, индивидуальность, соответствие требованиям и надёжность в реальных условиях. Он позиционируется как прагматичный, «практичный» шаг вперёд: умнее в слепых тестах на человеческие предпочтения, более эмоциональный, лучше справляется с творческим письмом и заметно менее подвержен «галлюцинациям» типа «уверенность, но ошибка», которые преследовали предыдущих успешных LLM.
Grok 4.1 достигает качественных изменений в следующих четырех измерениях:
- Креативность: демонстрирует более сильный языковой стиль и воображение в письменной речи, повествовании и социальных контекстах;
- Эмоциональный интеллект: распознает тон и эмоциональные изменения, реагируя с помощью более человеческой эмоциональной логики и генерируя успокаивающие и понимающие ответы;
- Последовательность личности: сохраняет постоянный тон и индивидуальность в длительных разговорах, больше не демонстрируя непоследовательного поведения, характерного для более ранних моделей;
- Совместная работа: поддерживает последовательность и осознание цели в многовариантных диалогах или совместной работе над задачами.
xAI суммирует свои характеристики в одном предложении: «Он более восприимчивый, более чуткий и больше похож на цельного человека».
Как работает Grok 4.1 изнутри?
Grok 4.1 лучше всего понимать как ту же предварительно обученную основу, которая используется во всем семействе Grok 4, плюс многоуровневый конвейер постобучения, который фокусируется на моделирование вознаграждений, согласование стилей и агентские оценщики.
Каковы этапы обучения и адаптации?
Grok 4.1 работает по многоступенчатой схеме, типичной для современных передовых LLM, адаптированной с двумя важными изменениями для версии 4.1:
- Предварительная тренировка + середина тренировки: Предварительное обучение на большом корпусе веб-данных + целенаправленное промежуточное обучение для улучшения знаний предметной области и многомодальных возможностей.
- Контролируемая тонкая настройка (SFT): Демонстрации желаемого поведения людьми (ответы, стратегии отказа).
- Моделирование вознаграждения (новое приложение): Модели вознаграждения xAI обучались не только на основе меток человеческих предпочтений, но также использовались пограничные модели агентного мышления в качестве оценщиков вознаграждений, фактически позволяя высококвалифицированным оценщикам, работающим на основе моделей, оценивать результаты кандидатов в масштабе. Это позволило оптимизировать непроверяемые атрибуты, такие как стиль, сплоченность личности, эмпатия и готовность помочь без необходимости в невероятно большом бюджете на маркировку людьми.
- Оптимизация политики (RLHF/RL из модельных вознаграждений): Стандартная оптимизация политики с использованием изученных сигналов вознаграждения для создания развернутой политики (модели, с которой взаимодействуют потребители).
Что нового в подходе моделирования вознаграждения?
В традиционном RLHF вы собираете метки человеческих предпочтений (A/B), обучаете модель вознаграждения для прогнозирования этих меток, а затем оптимизируете базовую модель с помощью RL (или выборки отбраковки) на основе полученного вознаграждения. Однако xAI выделяет два практических нововведения:
- Модели вознаграждения агентов: Вместо чисто человеческих оценок xAI использовал эффективные «агентные» модели рассуждений для оценки более тонких характеристик (тона, эмоционального оттенка, креативности). Оценщики могут быстро проводить тысячи парных сравнений, позволяя инженерам быстрее выполнять итерации. Это механизм для значительного улучшения стиля и эмоционального интеллекта.
- Выравнивание после обучения для непроверяемых сигналов: Для качеств, которые невозможно измерить с помощью детерминированной метрики (например, «теплота» или «целостная личность»), они ввели специализированные цели вознаграждения и масштабирование учебных программ, чтобы модель училась стиль результатов без ущерба для базовой фактической точности.
Как технически работает «мышление» и «немышление»?
- Grok 4.1 Мышление (кодовое имя
quasarflux) — предоставляет явные этапы рассуждения (токены мышления) перед выдачей окончательного ответа; оптимизировано для сложных задач и более высокого рейтинга Эло в LMArena. Дополнительные токены увеличивают время вывода, но помогают в многоэтапных задачах рассуждения, отладке и объяснимости. - Grok 4.1 Не-Думающий (кодовое имя
tensor) Обходит явные промежуточные токены, обеспечивая единый, немедленный окончательный ответ. Это сокращает задержку и стоимость токенов, сохраняя при этом преимущества тех же уточнённых весовых коэффициентов политики. Режим «без размышлений» был оптимизирован для обеспечения крайне низкой задержки при сохранении высокой производительности.
Оптимизация выравнивания настроений и стиля
Помимо простых сигналов «правдивости», Grok 4.1 включает в себя целенаправленную оптимизацию согласования по тональности, тону и межличностному стилю. Это означает, что тренировочный конвейер включает компоненты вознаграждения или проигрыша, которые явно наказывают за несоответствие тональности (например, за излишнюю резкость, когда эмпатия уместна), и вознаграждают ответы, соответствующие желаемому стилю или профилю тональности. В Grok 4.1 ИИ впервые представил цель оптимизации «Соответствие личности».
Целью программы является помощь модели в поддержании устойчивого и устойчивого чувства идентичности. По сравнению с Grok 4, версия 4.1 добавляет следующие цели обучения:
- Положительные вознаграждения за эмоциональное выражение (вознаграждение за эмоциональное выравнивание);
- Метрика согласованности личности.
Как оценивался Grok 4.1 и как он себя показал?
Что показали слепые тесты на человеческие предпочтения?
Во время скрытого развертывания Grok 4.1 получил предпочтение в 64.78% случаев по сравнению с предыдущей производственной моделью в реальном трафике — сильный сигнал человеческого предпочтения, указывающий на лучшие результаты разговора в реальных условиях.
Возглавляет ли Grok 4.1 таблицы лидеров?
xAI сообщает, что Grok 4.1 мышление режим находится в #1 на Text Arena от LMArena, с заявленным рейтингом Эло 1483, а его нелогичный (быстрый) режим занимает 2-е место с индексом Эло 1465 — высокие позиции в публичном рейтинге как по точности, так и по представлению (контроль стиля играет роль).
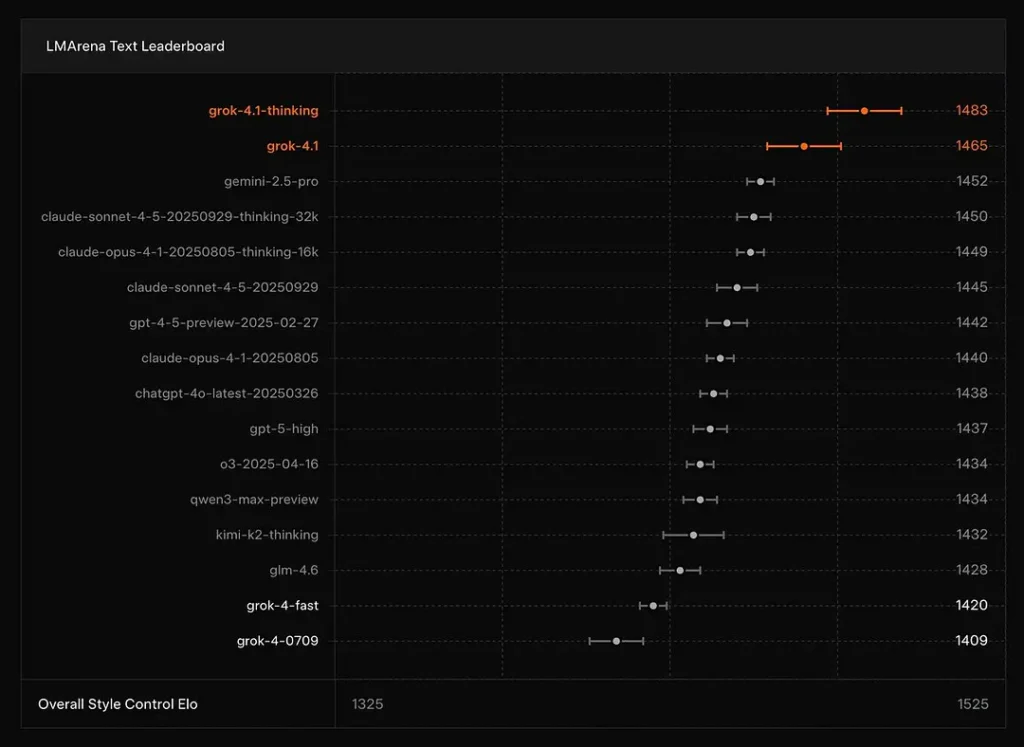
Заключение: Grok 4.1 превосходит основные модели серий GPT-4.5 и Claude по пониманию текста, генерации и общему качеству, уступая только версии GPT-5 Advanced Preview.
Эмоциональный интеллект
xAI провела EQ-Bench3, специализированный тест на эмоциональный интеллект, охватывающий 45 сложных ролевых сценариев, и сообщила, что Grok 4.1 демонстрирует значительный рост в эмпатии, темпе и межличностном взаимопонимании. Grok 4.1 набрала самые высокие баллы за понимание контекстов грусти, эмпатии и комфорта.

Творческое письмо — на самом деле оно более изобретательно?
Grok 4.1 был оценен на Творческое письмо v3 (32 подсказки в 3 итерациях с рубриками и оценкой Эло). xAI отмечает, что стиль письма, последовательность голоса и креативность повествования в версии 4.1 значительно выросли, что позволило ей занять одно из первых мест в недавних рейтингах творческих заданий (примеры подсказок включены в релиз). Независимые исследования подтвердили эти результаты: рецензенты отметили заметно более «отличительный голос» и лучшую связность текста в развернутом виде. По качеству письма Grok 4.1 уступает только моделям серии GPT-5 и превосходит все линейки продуктов Claude, Gemini и Kimi.

Уменьшение галлюцинаций / честность
xAI заявляет о значительном снижении частоты галлюцинаций: они сообщили (в анонсе и социальных сообщениях), что Grok 4.1 — это ~В 3 раза реже галлюцинируют По сравнению с более ранними моделями Grok, основанными на анализе производственного трафика и оценках в стиле FActScore (например, наборы вопросов по биографии, чем меньше значение, тем лучше). Особенно в «режиме без рассуждений», где доступны внешние инструменты поиска, согласованность фактов более стабильна.

Почему Grok 4.1 «давит» другие модели — это гипербола?
«Crushes» — это маркетинговый ход, но за этим утверждением стоят и объективные факты:
- Leaderboards: Grok 4.1 занимает лидирующие позиции в публичных рейтингах LMArena по генерации текста (1483 балла Эло в режиме «Мышление») и демонстрирует высокие показатели в креативных и EQ-тестах на момент выхода xAI. Это сопоставимые показатели, используемые в сообществе.
- Преимущество реального трафика выигрывает: xAI сообщает о преимуществах, связанных с предпочтениями человека, в слепых сравнениях (примерно 65% по сравнению с предыдущей производственной моделью) после скрытого развёртывания на реальном трафике. Это отражает реальные улучшения у пользователей, а не только бумажные бенчмарки.
- Практические новые возможности: Сочетание моделей-оценщиков, RL на непроверяемых сигналах и более строгих входных фильтров является прагматичным инженерным шагом, который напрямую улучшает пользовательский опыт в разговорных, эмпатических и творческих задачах, в которых конкуренты исторически неэффективны.
Итак, хотя «преуспевает» — это красочный способ сказать «лидерство в нескольких публичных и внутренних оценках», основные публичные метрики, опубликованные xAI, подтверждают этот вывод
Как получить доступ к Grok 4.1
Доступ потребителя/приложения
xAI периодически делал Grok 4.1 доступным в режиме «Авто» бесплатно или в качестве рекламного окна, но премиум-уровни (SuperGrok, SuperGrok Heavy) и доступ к API с более высокими квотами существуют и остаются платными предложениями.
Grok 4.1 доступен всем пользователям on grok.com, **Х (ранее Твиттер)**и приложения Grok для iOS и Android, которые сразу же запускаются в автоматическом режиме, а также могут быть выбраны явно как «Grok 4.1» в средстве выбора модели.
Доступ к API и планы разработчиков
Конечные точки Grok 4.1 доступны через API xAI. На момент публикации этой статьи официальный API GPT 4.1 ещё не был выпущен.
CometAPI обещает отслеживать динамику последних моделей, включая API Grok 4.1, который выйдет одновременно с официальным релизом. Ждите его с нетерпением и продолжайте следить за CometAPI. Пока вы ждете, обратите внимание на другие модели Grok, такие как Grok-code-fast-1 и Грок 4, изучите их возможности на Playground и обратитесь к руководству по API за подробными инструкциями по вызову . Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API.
Практические советы по использованию Grok 4.1 в производстве
Как снизить риск галлюцинаций
- Включить живой поиск или проверенная цепочка инструментов для запросов по поиску информации.
- Предоставьте шаги проверки: попросите модель вернуть источники и доказательства для фактических утверждений; используйте
responseметаданные для проверки ссылок (если доступны). - Выполнять детерминированные проверки (LLM по проверке фактов, валидаторы структурированных данных) в качестве этапа постобработки для высокорискованных результатов.
Как контролировать тон и стиль
- Используйте явные системные подсказки для исправления голоса («Вы формальны и сочувствуете»).
- Используйте контролируемые подсказки и небольшие локальные шаблоны для единообразия голосовых команд во всех приложениях.
- По возможности используйте функцию управления стилем xAI и управляемые наградами рулевые ручки.
Окончательный вердикт: является ли Grok 4.1 кардинальным изменением?
Грок 4.1 это совершенно новая архитектура; скорее, это сложная и продуманная после обучения / выравнивания релиз, посвященный тому, что на самом деле волнует людей в чате: личность, эмоциональный интеллект, креативность и меньше фактических ошибок. Ощутимый прирост в рейтингах, масштабные настройки для реального трафика и улучшенные инструменты безопасности. Для приложений, требующих высококачественного общения, творческого сотрудничества или голосовой помощи, Grok 4.1 — это значительный шаг вперед и, по нескольким результатам тестирования сообщества, лучший результат на момент выпуска.
CometAPI — это коммерческая платформа агрегации API, предоставляющая разработчикам унифицированный REST-доступ в стиле OpenAI к сотням моделей ИИ от разных поставщиков — текстовым LLM, генераторам изображений/видео, встраиваемым модулям и другим — через единый, согласованный интерфейс. Вместо подключения отдельных SDK или специализированных конечных точек для OpenAI, Anthropic, Google, Meta или более мелких специализированных поставщиков моделей, CometAPI позволяет вызывать различные модели, изменяя строки модели и несколько параметров.
Готовы попробовать?→ Зарегистрируйтесь в CometAPI сегодня !
Если вы хотите узнать больше советов, руководств и новостей об искусственном интеллекте, подпишитесь на нас VK, X и Discord!