

GLM-5 — новая модель с открытыми весами от Zhipu AI, ориентированная на агентов, созданная для долгосрочной разработки кода и многошаговых агентов. Доступна через несколько хостинговых API (включая CometAPI и провайдерские endpoints), а также как исследовательский релиз с кодом и весами; вы можете интегрировать её с помощью стандартных OpenAI-совместимых REST-вызовов, стриминга и SDK.
Что такое GLM-5 от Z.ai?
GLM-5 — флагманская базовая модель пятого поколения от Z.ai, спроектированная для агентной инженерии: долгосрочного планирования, многошагового использования инструментов и крупномасштабного проектирования кода/систем. Публично выпущена в феврале 2026 года. GLM-5 — модель Mixture-of-Experts (MoE) с общим числом параметров ~744 миллиардов и активным набором около 40B на проход; архитектура и выборы в обучении ориентированы на согласованность в длинном контексте, вызов инструментов и экономичную по стоимости инференс-работу для продакшна. Эти решения позволяют GLM-5 выполнять расширенные агентные пайплайны (например: просмотр → планирование → написание/тестирование кода → итерации), сохраняя контекст при очень больших входах.
Key technical highlights :
- Архитектура MoE с ~744B общих / ~40B активных параметров; масштабное предобучение (~28.5T токенов заявлено), чтобы сократить разрыв с закрытыми моделями фронтира.
- Поддержка длинного контекста и оптимизации (deep sparse attention, DSA), снижающие стоимость развёртывания по сравнению с наивным плотным масштабированием.
- Встроенные агентные возможности: вызов инструментов/функций, поддержка состояния сессий и интегрированные выходы (способна генерировать артефакты
.docx,.xlsx,.pdfв рамках агентных сценариев в интерфейсах вендоров). - Открытые веса (веса публикуются в хабах моделей) и варианты хостингового доступа (вендорские API, инференс-микросервисы).
Каковы основные преимущества GLM-5?
Агентное планирование и долговременная память
Архитектура и настройка GLM-5 приоритизируют согласованное многошаговое рассуждение и память по всему рабочему процессу — это полезно для:
- автономных агентов (конвейеры CI, оркестраторы задач),
- генерации или рефакторинга кода по многим файлам, и
- интеллектуальной обработки документов, где нужен большой объём истории.
Большие окна контекста
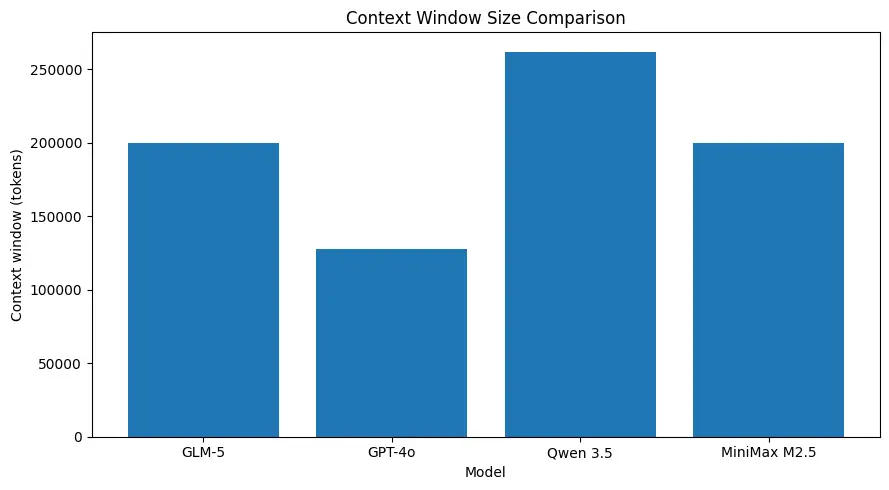
GLM-5 поддерживает очень большие размеры контекста (порядка ~200k токенов в опубликованных спецификациях), что позволяет держать больше части сессии в одном запросе и сокращает потребность в агрессивном чанкинге или внешней памяти для многих случаев использования. (См. сравнительную диаграмму ниже.)
Сильная производительность в системных задачах программирования
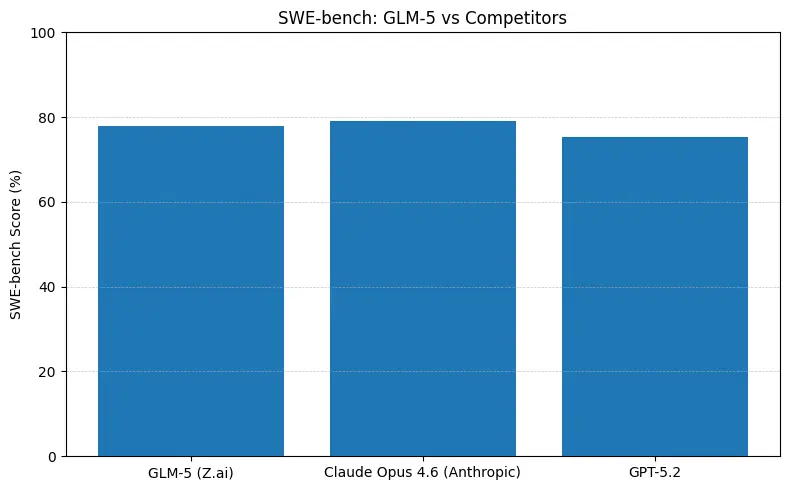
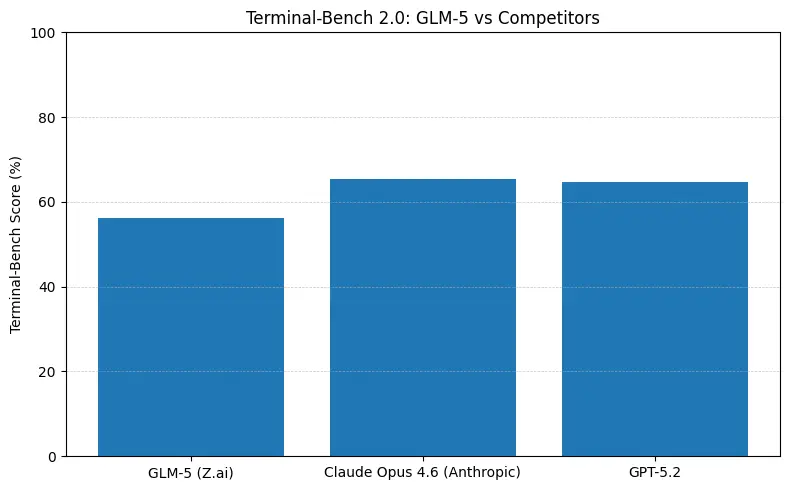
GLM-5 сообщает о топовой среди открытых моделей производительности на бенчмарках программной инженерии (SWE-bench и прикладные наборы кода + агенты). На SWE-bench-Verified указано ~77.8%; на агентных тестах в стиле терминала (Terminal-Bench 2.0) оценки находятся в середине 50% — свидетельство практических навыков кодирования, приближающихся к закрытым моделям фронтира. Эти метрики означают, что GLM-5 подходит для задач генерации кода, автоматического рефакторинга, многодоскового рассуждения и сценариев помощника для CI/CD.
Компромиссы между стоимостью и эффективностью
За счёт MoE и инноваций «разреженного» внимания GLM-5 стремится снизить стоимость инференса на единицу возможностей по сравнению с грубым плотным масштабированием. CometAPI предлагает конкурентные цены, делающие GLM-5 привлекательной для высокопоточных агентных нагрузок.
Как использовать API GLM-5 через CometAPI?
Коротко: относитесь к CometAPI как к OpenAI-совместимому шлюзу — задайте базовый URL и API-ключ, выберите модель glm-5, затем вызовите endpoint chat/completions. CometAPI предоставляет REST-интерфейс в стиле OpenAI (endpoints вроде /v1/chat/completions) плюс SDK и примеры, делающие миграцию тривиальной.
Ниже — практический, ориентированный на продакшн «поварёнок»: аутентификация, базовый вызов чата, стриминг, вызов функций/инструментов и обработка стоимости/ответов.
Основные шаги доступа к GLM-5 через CometAPI:
- Зарегистрируйтесь в CometAPI, получите API-ключ.
- Найдите точный идентификатор модели GLM-5 в каталоге CometAPI (
"glm-5"в зависимости от листинга). - Отправьте аутентифицированный POST-запрос к endpoint CometAPI для chat/completions (в стиле OpenAI).
Базовые детали (паттерны CometAPI): платформа поддерживает пути в стиле OpenAI, такие как https://api.cometapi.com/v1/chat/completions, аутентификацию Bearer, параметр model, сообщения system/user, стриминг, а также примеры в curl/python в документации.
Пример: быстрый чат-комплишн на Python (requests) с GLM-5
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
Пример: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
Потоковые ответы (практический паттерн)
CometAPI поддерживает стриминг в стиле OpenAI (SSE / chunked). Самый простой способ в Python — запросить "stream": true и итерироваться по данным ответа по мере их поступления. Это важно, когда вам нужен низко-летентный частичный вывод (строить realtime дев-ассистентов, стриминговые UI).
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
Ссылка: документация по стримингу в стиле OpenAI и совместимости CometAPI.
Вызов функций/инструментов (как вызвать внешний инструмент)
GLM-5 поддерживает паттерны вызова функций или инструментов, совместимые с конвенциями OpenAI / агрегаторов (шлюз передаёт структурированные вызовы функций в ответе модели). Пример: попросите GLM-5 вызвать локальный инструмент «run_tests»; модель вернёт структурированную инструкцию, которую вы можете распарсить и выполнить.
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
Когда модель возвращает payload function_call, выполните инструмент на серверной стороне, затем передайте результат инструмента обратно как сообщение с ролью "tool" и продолжайте диалог. Этот паттерн обеспечивает безопасный вызов инструментов и состояние для агентных потоков. См. документацию и примеры CometAPI для конкретных помощников SDK.
Практические параметры и настройка
function_call: используйте для включения структурированного вызова инструментов и более безопасных сценариев исполнения.
temperature: 0–0.3 для детерминированного системного вывода (код, инфраструктура), выше — для генерации идей.
max_tokens: задайте ожидаемую длину выхода; при хостинге GLM-5 поддерживает очень длинные ответы (лимиты зависят от вендора).
top_p / nucleus sampling: полезно для ограничения маловероятных хвостов.
stream: true для интерактивных интерфейсов.
Сравнение GLM-5 с Claude Opus от Anthropic и другими передовыми моделями
Коротко: GLM-5 сокращает разрыв с закрытыми моделями фронтира в агентных и кодовых бенчмарках, предлагая при этом развёртывание с открытыми весами и часто лучшую стоимость за токен при хостинге у агрегаторов. Нюанс: на некоторых абсолютных кодовых бенчмарках (SWE-bench, варианты Terminal-Bench) Claude Opus (4.5/4.6) всё ещё лидирует на несколько пунктов в публикуемых рейтингах — но GLM-5 весьма конкурентоспособна и превосходит многие другие открытые модели.
Что означают эти цифры на практике
- SWE-bench (~корректность кода / инженерия): Claude Opus показывает небольшой отрыв (≈79% против GLM-5 ≈77.8%) на опубликованных лидербордах; для многих реальных задач этот разрыв приведёт к меньшему числу ручных правок, но не обязательно повлияет на выбор архитектуры для прототипирования или масштабных агентных потоков.
- Terminal-Bench (агентные задачи в командной строке): Opus 4.6 лидирует (≈65.4% против GLM-5 ≈56.2%) — если вам нужна надёжная автоматизация терминала и максимальная устойчивость к out-of-distribution операциям в shell, Opus часто лучше на границе.
- Агентность и долгий горизонт: GLM-5 очень сильна на бизнес-симуляциях с длинным горизонтом (Vending-Bench 2 — баланс $4,432 указан) и демонстрирует высокую согласованность планирования для многошаговых рабочих процессов. Если ваш продукт — долго работающий агент (финансы, операции), GLM-5 — сильный выбор.
Как проектировать промпты и системы, чтобы получать надёжные результаты от GLM-5?
Системные сообщения и явные ограничения
Задавайте GLM-5 строгую роль и ограничения, особенно для задач кода или вызова инструментов. Пример:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
Просите о тестах и кратком обосновании для каждого нетривиального изменения.
Декомпозируйте сложные задачи
Вместо «написать весь продукт» запросите:
- проектный набросок,
- сигнатуры интерфейсов,
- реализацию и тесты,
- финальный интеграционный скрипт.
Такая пошаговая декомпозиция снижает галлюцинации и даёт детерминированные контрольные точки для валидации.
Используйте низкую температуру для детерминированного кода
При запросах кода устанавливайте temperature = 0–0.2 и max_tokens с безопасным верхним пределом. Для креативного письма или мозгового штурма поднимайте температуру.
Лучшие практики интеграции GLM-5 (через CometAPI или прямых хостов)
Инжиниринг промптов и системные промпты
- Используйте явные system-инструкции, определяющие роли агентов, политику доступа к инструментам и требования безопасности. Пример: «Вы — системный архитектор: предлагайте изменения только когда юнит-тесты проходят локально; перечисляйте точные CLI-команды для запуска».
- Для задач программирования предоставляйте контекст репозитория (списки файлов, ключевые фрагменты кода) и прикладывайте вывод юнит-тестов, если доступен. Длинный контекст GLM-5 помогает — но всегда держите важнейший контекст (роль, задача) перед поддерживающими артефактами.
Управление сессиями и состоянием
- Используйте ID сессий для длительных разговоров агента и держите компактную «память» прошлых шагов (сводки), чтобы избежать раздувания контекста. CometAPI и подобные шлюзы предоставляют помощников для состояния — но на уровне приложения компактизация памяти критична для долго работающих агентов.
Инструментарий и вызов функций (безопасность и надёжность)
- Предоставляйте узкий, аудируемый набор инструментов. Не допускайте произвольного выполнения shell без участия человека. Используйте структурированные определения функций и валидируйте их аргументы на серверной стороне.
- Всегда логируйте вызовы инструментов и ответы модели для трассируемости и последующего разбора.
Контроль стоимости и батчинг
- Для высоких объёмов перенаправляйте фоновую обработку на более дешёвые варианты моделей, когда качество можно немного снизить (в CometAPI можно переключать модели по имени). Батчируйте похожие запросы и уменьшайте
max_tokens, где возможно. Мониторьте соотношение входных и выходных токенов — выход часто дороже.
Инжиниринг задержки и пропускной способности
- Используйте стриминг для интерактивных сессий. Для фоновых агентных задач предпочитайте асинхронные рантаймы, очереди работников и лимитеры. Если вы размещаете сами (открытые веса), настройте топологию ускорителей под архитектуру MoE — варианты на FPGA / Ascend / специализированном кремнии могут дать выигрыш в стоимости.
Заключение
GLM-5 — практический шаг в сторону агентной инженерии с открытыми весами: большие окна контекста, возможности планирования и сильная кодовая производительность делают её привлекательной для инструментов разработчика, оркестрации агентов и системной автоматизации. Используйте CometAPI для быстрой интеграции или облачные «сады моделей» для управляемого хостинга; всегда валидируйте на своих нагрузках и тщательно контролируйте стоимость и галлюцинации.
Разработчики уже могут получить доступ к GLM-5 через CometAPI. Для начала изучите возможности модели в Playground и обратитесь к API guide за подробными инструкциями. Перед доступом убедитесь, что вы вошли в CometAPI и получили API-ключ. CometAPI предлагает цены значительно ниже официальных, чтобы помочь вам с интеграцией.
Готовы начать?→ Зарегистрируйтесь для M2.5 сегодня !
Если хотите больше советов, руководств и новостей об ИИ — подписывайтесь на нас в VK, X и Discord!