

Начало работы с Gemini 2.5 Flash-Lite через CometAPI — это захватывающая возможность использовать одну из самых экономически эффективных и малозадерживаемых моделей генеративного ИИ, доступных сегодня. Это руководство объединяет последние объявления от Google DeepMind, подробные спецификации из документации Vertex AI и практические шаги интеграции с использованием CometAPI, которые помогут вам быстро и эффективно приступить к работе.
Что такое Gemini 2.5 Flash-Lite и почему вам стоит его рассмотреть?
Обзор семейства Gemini 2.5
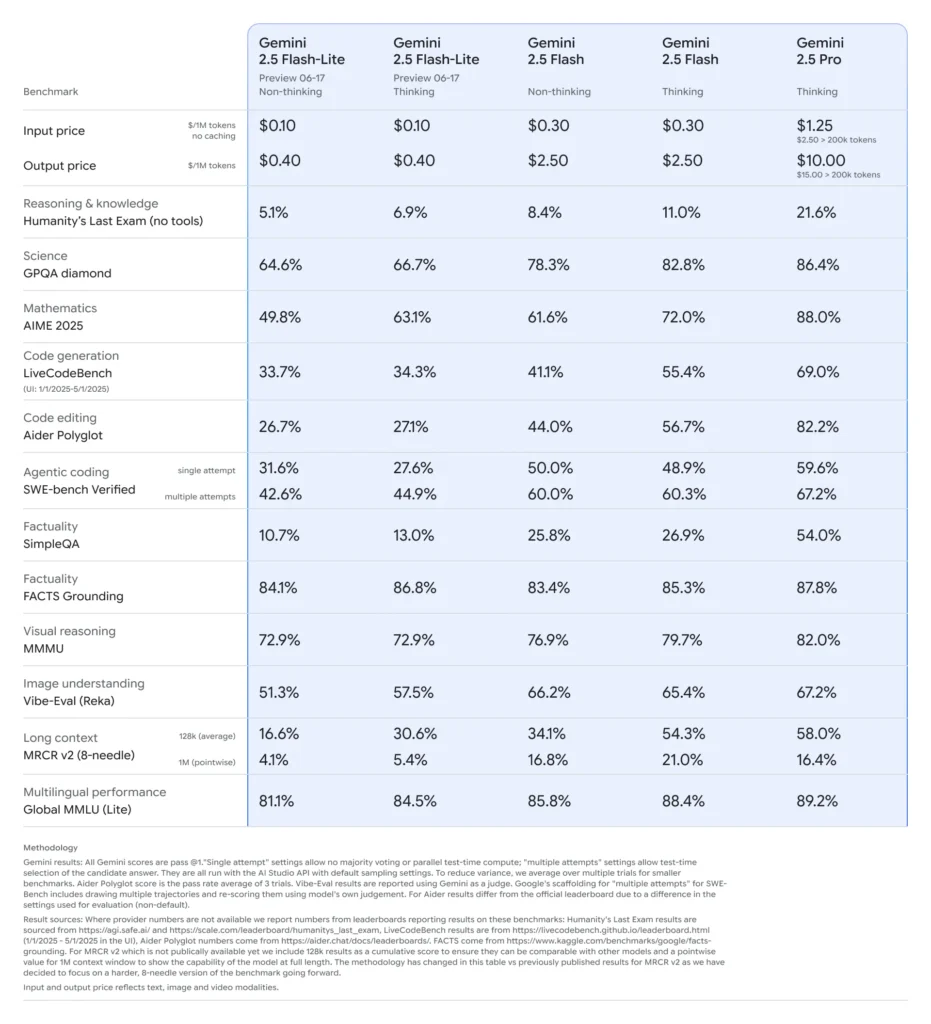
В середине июня 2025 года Google DeepMind официально выпустила серию Gemini 2.5, включая стабильные версии GA Gemini 2.5 Pro и Gemini 2.5 Flash, а также предварительную версию совершенно новой облегченной модели: Gemini 2.5 Flash-Lite. Разработанная для баланса скорости, стоимости и производительности, серия 2.5 представляет собой стремление Google удовлетворить широкий спектр вариантов использования — от тяжелых исследовательских рабочих нагрузок до крупномасштабных, чувствительных к затратам развертываний.
Основные характеристики Flash-Lite
Flash-Lite отличается тем, что предлагает мультимодальные возможности (текст, изображения, аудио, видео) с чрезвычайно низкой задержкой, с контекстным окном, поддерживающим до одного миллиона токенов и интеграцией инструментов, включая Google Search, выполнение кода и вызов функций. Что особенно важно, Flash-Lite вводит управление «бюджетом мыслей», позволяя разработчикам находить компромисс между глубиной рассуждений и временем отклика и стоимостью, регулируя внутренний параметр бюджета токенов.
Позиционирование в модельном ряду
По сравнению со своими собратьями Flash-Lite находится на границе эффективности затрат по Парето: при цене около $0.10 за миллион входных токенов и $0.40 за миллион выходных токенов во время предварительного просмотра он обходит как Flash ($0.30/$2.50), так и Pro ($1.25/$10), сохраняя при этом большую часть их мультимодальных возможностей и поддержки вызова функций. Это делает Flash-Lite идеальным для задач с большим объемом и низкой сложностью, таких как реферирование, классификация и легкие разговорные агенты.
Почему разработчикам стоит рассмотреть Gemini 2.5 Flash-Lite?
Тесты производительности и реальные испытания
В прямых сравнениях Flash-Lite продемонстрировал:
- В 2 раза выше пропускная способность чем Gemini 2.5 Flash в задачах классификации.
- 3-кратная экономия средств для конвейеров резюмирования в масштабе предприятия.
- Конкурентная точность по показателям логики, математики и кода, соответствующим или превосходящим предыдущие предварительные версии Flash-Lite.
Идеальные варианты использования
- Чат-боты большого объема: Обеспечьте миллионам пользователей единообразное общение с минимальной задержкой.
- Автоматическая генерация контента: Масштабное реферирование документов, перевод и создание микрокопий.
- Конвейеры поиска и рекомендаций: Используйте быстрый вывод для персонализации в реальном времени.
- Пакетная обработка данных: Аннотируйте большие наборы данных с минимальными затратами на вычисления.
Как получить и управлять доступом к API для Gemini 2.5 Flash-Lite через CometAPI?
Почему стоит использовать CometAPI в качестве шлюза?
CometAPI объединяет более 500 моделей ИИ, включая серию Gemini от Google, в единой конечной точке REST, упрощая аутентификацию, ограничение скорости и выставление счетов между поставщиками. Вместо того чтобы жонглировать несколькими базовыми URL-адресами и ключами API, вы направляете все запросы на https://api.cometapi.com/v1, укажите целевую модель в полезной нагрузке и управляйте использованием с помощью единой панели управления.
Предварительные условия и регистрация
- Войти в cometapi.com. Если вы еще не являетесь нашим пользователем, пожалуйста, сначала зарегистрируйтесь.
- Получите ключ API-интерфейса для доступа к учетным данным. Нажмите «Добавить токен» в API-токене в персональном центре, получите ключ токена: sk-xxxxx и отправьте.
- Получите URL этого сайта: https://api.cometapi.com/
Управление токенами и квотами
Панель управления CometAPI предоставляет унифицированные квоты токенов, которые могут быть общими для Google, OpenAI, Anthropic и других моделей. Используйте встроенные инструменты мониторинга для установки оповещений об использовании и ограничений скорости, чтобы вы никогда не превышали бюджетные ассигнования и не несли непредвиденных расходов.
Как настроить среду разработки для интеграции CometAPI?
Установка необходимых зависимостей
Для интеграции Python установите следующие пакеты:
pip install openai requests pillow
- openai: Совместимый SDK для взаимодействия с CometAPI.
- Запросы: Для HTTP-операций, таких как загрузка изображений.
- подушка: Для обработки изображений при отправке многомодальных входных данных.
Инициализация клиента CometAPI
Используйте переменные среды, чтобы хранить ключ API вне исходного кода:
import os
from openai import OpenAI
client = OpenAI(
base_url="gemini-2.5-flash-lite-preview-06-17",
api_key=os.getenv("COMETAPI_KEY"),
)
Этот экземпляр клиента теперь может быть нацелен на любую поддерживаемую модель, указав ее идентификатор (например, gemini-2.5-flash-lite-preview-06-17) в ваших запросах.
Настройка бюджета мыслей и других параметров
При отправке запроса вы можете включить необязательные параметры:
- температура/top_p: Контроль случайности при генерации.
- candidateCount: Количество альтернативных выходов.
- max_tokens: Ограничение выходного токена.
- мысли_бюджет: Пользовательский параметр для Flash-Lite, позволяющий найти компромисс между глубиной, скоростью и стоимостью.
Как выглядит базовый запрос к Gemini 2.5 Flash-Lite через CometAPI?
Пример только текста
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=[
{"role": "system", "content": "You are a concise summarizer."},
{"role": "user", "content": "Summarize the latest trends in AI model pricing."}
],
max_tokens=150,
thought_budget=1000,
)
print(response.choices.message.content)
Этот вызов возвращает краткое резюме менее чем за 200 мс, что идеально подходит для чат-ботов или аналитических конвейеров в реальном времени.
Пример многомодального ввода
from PIL import Image
import requests
# Load an image from a URL
img = Image.open(requests.get(
"https://storage.googleapis.com/cloud-samples-data/generative-ai/image/diagram.png",
stream=True
).raw)
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
max_tokens=200,
)
print(response.choices.message.content)
Flash-Lite обрабатывает изображения размером до 7 МБ и возвращает контекстные описания, что делает его пригодным для понимания документов, анализа пользовательского интерфейса и автоматизированного составления отчетов.
Как можно использовать расширенные функции, такие как потоковая передача и вызов функций?
Потоковые ответы для приложений реального времени
Для интерфейсов чат-ботов или живых субтитров используйте API потоковой передачи:
for chunk in client.models.stream_generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
):
print(chunk.choices.delta.content, end="")
Это позволяет предоставлять частичные выходные данные по мере их поступления, сокращая воспринимаемую задержку в интерактивных пользовательских интерфейсах.
Вызов функции для структурированного вывода данных
Определите схемы JSON для обеспечения структурированных ответов:
functions = [{
"name": "extract_entities",
"description": "Extract named entities from text.",
"parameters": {
"type": "object",
"properties": {
"entities": {"type": "array", "items": {"type": "string"}},
},
"required":
}
}]
response = client.models.generate_content(
model="gemini-2.5-flash-lite-preview-06-17",
contents=,
functions=functions,
function_call={"name": "extract_entities"},
)
print(response.choices.message.function_call.arguments)
Такой подход гарантирует получение выходных данных, совместимых с JSON, что упрощает нисходящие конвейеры данных и интеграцию.
Как оптимизировать производительность, стоимость и надежность при использовании Gemini 2.5 Flash-Lite?
Мысль о настройке бюджета
Параметр бюджета мыслей Flash-Lite позволяет вам настраивать объем «когнитивных усилий», которые затрачивает модель. Низкий бюджет (например, 0) отдает приоритет скорости и стоимости, тогда как более высокие значения обеспечивают более глубокое рассуждение за счет задержки и токенов.
Управление лимитами токенов и пропускной способностью
- Входные токены: До 1,048,576 XNUMX XNUMX токенов на запрос.
- Выходные токены: Лимит по умолчанию — 65,536 XNUMX токенов.
- Мультимодальные входы: До 500 МБ для изображений, аудио и видео.
Реализуйте пакетную обработку на стороне клиента для больших объемов рабочих нагрузок и используйте автоматическое масштабирование CometAPI для обработки пикового трафика без ручного вмешательства.
Стратегии экономической эффективности
- Объедините задачи низкой сложности в Flash-Lite, а Pro или стандартную Flash зарезервируйте для сложных задач.
- Используйте ограничения по ставкам и оповещения о бюджете на панели инструментов CometAPI, чтобы предотвратить неконтролируемые расходы.
- Отслеживайте использование по идентификатору модели, чтобы сравнивать стоимость запроса и соответствующим образом корректировать логику маршрутизации.
Каковы передовые методы и следующие шаги после первоначальной интеграции?
Мониторинг, ведение журнала и безопасность
- Запись: Сбор метаданных запросов/ответов (временные метки, задержки, использование токенов) для аудита производительности.
- Оповещения: Настройте пороговые значения уведомлений для ошибок или превышения затрат в CometAPI.
- Безопасность.: Регулярно меняйте ключи API и храните их в безопасных хранилищах или переменных среды.
Распространенные модели использования
- ЧатБоты: Используйте Flash-Lite для быстрых запросов пользователей и возвращайтесь к Pro для сложных ответов.
- Обработка документов: Пакетный анализ PDF-файлов или изображений за одну ночь при более низких бюджетных настройках.
- Аналитика в режиме реального времени: Передавайте финансовые или операционные данные для мгновенного получения информации через потоковый API.
Дальнейшие исследования
- Экспериментируйте с гибридными подсказками: комбинируйте текст и изображения для более насыщенного контекста.
- Прототип RAG (Retrieval-Augmented Generation) путем интеграции инструментов векторного поиска с Gemini 2.5 Flash-Lite.
- Сравните с предложениями конкурентов (например, GPT-4.1, Claude Sonnet 4) для проверки компромиссов между стоимостью и производительностью.
Масштабирование производства
- Используйте корпоративный уровень CometAPI для выделенных пулов квот и гарантий SLA.
- Реализуйте сине-зеленые стратегии развертывания для тестирования новых подсказок или бюджетов, не мешая работе реальных пользователей.
- Регулярно проверяйте показатели использования модели, чтобы выявить возможности для дальнейшей экономии средств или повышения качества.
Первые шаги
CometAPI предоставляет унифицированный интерфейс REST, который объединяет сотни моделей ИИ — в рамках единой конечной точки, со встроенным управлением ключами API, квотами использования и панелями выставления счетов. Вместо жонглирования несколькими URL-адресами поставщиков и учетными данными.
Разработчики могут получить доступ API Gemini 2.5 Flash-Lite (предварительная версия)(Модель: gemini-2.5-flash-lite-preview-06-17) Через CometAPI, последние модели указаны на дату публикации статьи. Для начала изучите возможности модели в Детская Площадка и проконсультируйтесь с API-руководство для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предложить цену намного ниже официальной, чтобы помочь вам интегрироваться.
Всего за несколько шагов вы можете интегрировать Gemini 2.5 Flash-Lite через CometAPI в свои приложения, открывая мощное сочетание скорости, доступности и многомодального интеллекта. Следуя приведенным выше рекомендациям, охватывающим настройку, основные запросы, расширенные функции и оптимизацию, вы будете в хорошей позиции для предоставления пользователям опыта ИИ следующего поколения. Будущее экономически эффективного, высокопроизводительного ИИ уже здесь: начните работу с Gemini 2.5 Flash-Lite сегодня.