

Kling O1, выпущенный в рамках недели запуска Kling AI «Omni», позиционирует себя как единую, унифицированную модель мультимодального видео, которая принимает текст, изображения и видео в одном запросе и может генерировать и редактировать видео в итеративных рабочих процессах на уровне режиссёра. Команда Клинга называет O1 «первой в мире унифицированной крупномасштабной моделью мультимодального видео». Внутренние тесты Клинга демонстрируют значительные преимущества перед Google Veo 3.1 и Runway Aleph.
Что такое Kling O1?
Kling O1 (часто продается как Видео О1 or Омни Один) — это недавно выпущенная модель видеофундамента от Kling AI, которая объединяет генерацию и редактирование текста, изображений и видео в единой структуре, управляемой подсказками. Вместо того, чтобы рассматривать преобразование текста в видео, преобразование изображений в видео и редактирование видео как отдельные конвейеры, Kling O1 принимает смешанные входные данные (текст + несколько изображений + опциональное справочное видео) в одной подсказке, анализирует их и создает связные короткие клипы или редактирует существующие кадры с детальным контролем. Компания позиционировала внедрение как часть «Omni Launch» и описывает O1 как «мультимодальный видеодвижок», построенный на парадигме мультимодального визуального языка (MVL) и пути рассуждения цепочки мыслей (CoT) для интерпретации сложных, многокомпонентных творческих инструкций.
В своей работе Клинг делает акцент на трёх практических рабочих процессах: (1) текст → генерация видео, (2) изображение/элемент → видео (композитинг и замена объекта/реквизита с использованием явных референсов) и (3) редактирование видео/продолжение съёмки (изменение стиля, добавление/удаление объектов, управление начальным и конечным кадрами). Модель поддерживает многоэлементные подсказки (включая синтаксис «@» для указания определённых референсов) и включает элементы управления в стиле режиссёра, такие как привязка начального и конечного кадров и продолжение съёмки для создания многокадровых последовательностей.
5 основных моментов Kling O1
1) Истинный унифицированный мультимодальный ввод (MVL)
Флагманская функция Kling O1 — обработка текста, неподвижных изображений (множественных эталонных изображений) и видео как первоклассных одновременных входных данных. Пользователи могут предоставить несколько эталонных изображений (или короткий эталонный клип). и Инструкция на естественном языке; модель анализирует все входные данные вместе, чтобы создать или отредактировать согласованный вывод. Это уменьшает трение между инструментами и позволяет реализовать такие рабочие процессы, как «использовать объект из @image1, поместите их в окружающую среду из @image2, сопоставьте движение с ref_video.mp4, и примените кинематографическую цветовую градацию X». Такое обрамление «мультимодального визуального языка» (MVL) является основой презентации Клинга.
Почему это важно: Настоящие творческие рабочие процессы часто требуют объединения референсов: персонажа из одного объекта, движения камеры из другого и текстовой инструкции. Объединение этих данных позволяет генерировать анимацию за один проход и сократить количество этапов ручной компоновки.
2) Редактирование + генерация в одной модели (многоэлементный режим)
В большинстве предыдущих систем генерация (текст → видео) была разделена с покадровым монтажом. O1 намеренно объединяет их: та же модель, которая создаёт клип с нуля, может также редактировать уже существующий материал — менять объекты, менять стиль одежды, удалять реквизит или расширять кадр — всё это с помощью инструкций на естественном языке. Такая конвергенция существенно упрощает рабочий процесс для производственных групп.
В основе модели O1 лежит глубокая интеграция множества видеозадач:
- Генерация текста в видео
- Генерация эталонных изображений/предметов
- Видеомонтаж и инрисовка
- Рестайл видео
- Генерация следующего/предыдущего снимка
- Генерация видео с ограничением по ключевым кадрам
Главное значение этой разработки заключается в следующем: сложные процессы, ранее требовавшие использования нескольких моделей или независимых инструментов, теперь могут быть реализованы в рамках одного движка. Это не только значительно снижает затраты на создание и вычислительные затраты, но и закладывает основу для разработки «единой модели понимания и генерации видео».
3) Слаженность создания видео
Последовательность идентичности: Модель O1 расширяет возможности моделирования кросс-модальной согласованности, сохраняя стабильность структуры, материала, освещения и стиля исходного объекта в процессе генерации:
- Поддерживает многоракурсные эталонные изображения для моделирования объектов;
- поддерживает согласованность сюжета при съемке в перекрестных кадрах (характеры персонажей, объектов и сцен остаются неизменными в разных кадрах);
- поддерживает многообъектные гибридные ссылки, позволяя создавать групповые портреты и интерактивное построение сцен.
Этот механизм значительно повышает согласованность и «последовательность идентичности» генерации видео, что делает его пригодным для сценариев с чрезвычайно высокими требованиями к согласованности, таких как генерация рекламных кадров и кадров на уровне фильмов.
Улучшение памяти: Модель O1 также обладает «памятью», предотвращая нестабильность стиля вывода из-за длинных контекстов или смены инструкций. Она может даже:
- запоминать несколько символов одновременно;
- позволяют разным персонажам взаимодействовать в видео;
- сохраняйте последовательность в стиле, одежде и осанке.
4) Точная композиция с синтаксисом «@» и управлением начальным/конечным кадром
Клинг ввел сокращенную запись (систему упоминаний «@»), позволяющую ссылаться на конкретные изображения в подсказке (например, @image1, @image2) для надёжного назначения ролей ресурсам. В сочетании с явным указанием начального и конечного кадров это позволяет на уровне режиссёра контролировать переходы, перемещение и морфинг элементов в сгенерированном клипе — набор функций, ориентированный на производство, который отличает O1 от многих генераторов, ориентированных на потребителя.
5) Высококачественные, продолжительные выходные данные и многозадачность
Сообщается, что Kling O1 способен создавать кинематографические видео в разрешении 1080p (30 кадров в секунду), и — как и предыдущие версии Kling, компания рекламирует создание более длинных клипов (в недавних обзорах продукта упоминалась продолжительность до 2 минут). Он также поддерживает объединение нескольких творческих задач в одном запросе (генерация, добавление объекта, изменение освещения и редактирование композиции). Эти характеристики делают его конкурентоспособным по сравнению с более высокоуровневыми движками для работы с текстом и видео.
Почему это важно: Более длинные высококачественные клипы и возможность объединения редакций уменьшают необходимость в сшивке множества коротких клипов и упрощают весь процесс производства.
Какова архитектура Kling O1 и каковы ее основные механизмы?
O1 вокруг Мультимодальный визуальный язык (MVL) Ядро: модель, которая обучается совместным встраиваниям сигналов языка, изображений и движения (видеокадров и характеристик в стиле оптического потока), а затем применяет декодеры на основе диффузии или преобразователя для синтеза временно когерентных кадров. Модель описывается как выполняющая кондиционирование на основе множественных ссылок (текста; изображений «один ко многим»; коротких видеоклипов) для создания скрытого видеопредставления, которое затем декодируется в покадровые изображения с сохранением временной согласованности с помощью межкадрового внимания или специализированных временных модулей.
1. Мультимодальный преобразователь + Архитектура длинного контекста
Модель O1 использует многомодальную архитектуру Transformer, разработанную Keling, которая объединяет текстовые, графические и видеосигналы и поддерживает длительную временную контекстную память (мультимодальный длинный контекст).
Это позволяет модели понимать временную непрерывность и пространственную согласованность во время генерации видео.
2. MVL: Мультимодальный визуальный язык
MVL является основным нововведением этой архитектуры.
Он глубоко согласует языковые и визуальные сигналы внутри Трансформера посредством единого семантического промежуточного слоя, тем самым:
- Разрешение одному полю ввода смешивать многомодальные инструкции;
- Улучшение точности понимания моделью описаний естественного языка;
- Поддержка высокогибкой интерактивной генерации видео.
Внедрение MVL знаменует собой переход от создания видео на основе текста к созданию видео на основе семантико-визуальной составляющей.
3. Механизм вывода по цепочке мыслей
Модель O1 вводит путь вывода «цепочки мыслей» на этапе генерации видео.
Этот механизм позволяет модели выполнять логику событий и выводить время до генерации, тем самым поддерживая естественную связь между действиями и событиями в видео.
Конвейеры вывода и редактирования
- Генерация: поток: (текст + необязательные ссылки на изображения + необязательные ссылки на видео + настройки генерации) → модель создает скрытые видеокадры → декодирует в кадры → необязательная цветовая/временная постобработка.
- Редактирование на основе инструкций: Лента: (исходное видео + текстовая инструкция + опциональные ссылки на изображения) → модель внутренне сопоставляет запрошенное редактирование с набором преобразований в пиксельном пространстве, а затем синтезирует отредактированные кадры, сохраняя неизменённый контент. Поскольку всё находится в одной модели, для создания и редактирования используются одни и те же модули кондиционирования и временной обработки.
Kling Viedo o1 vs Veo 3.1 vs Runway Aleph
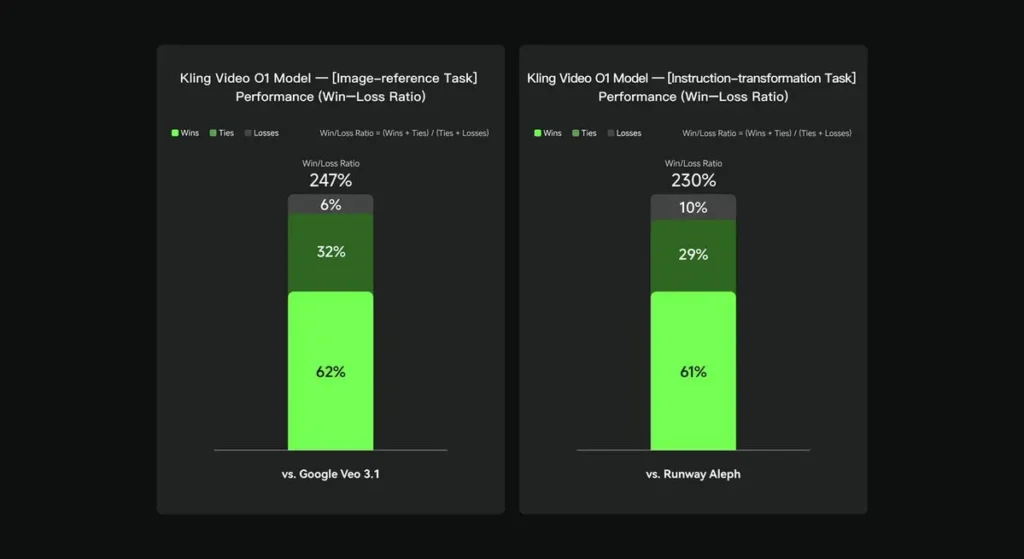
По результатам внутренних оценок Keling Video O1 значительно превзошла существующие международные аналоги по нескольким ключевым параметрам. Результаты производительности (на основе набора оценок, созданного Keling AI):
- Задача «Ссылка на изображение»: O1 превосходит Google Veo 3.1 в целом, с показателем побед 247%;
- Задача «Трансформация инструкций»: O1 превосходит Runway Aleph с показателем побед 230%.
Обзор конкурентов (сравнение на уровне функций)
| Возможности/Модель | Клинг О1 | Гугл Вео 3.1 | Взлетно-посадочная полоса (Алеф / Ген-4.5) |
|---|---|---|---|
| Унифицированное мультимодальное приглашение (текст+изображения+видео) | Да (основной аргумент в пользу продажи). многомодальные потоки с одним запросом. | Частично — текст → видео + ссылки присутствуют; меньший акцент на едином унифицированном MVL. | Runway фокусируется на генерации + редактировании, но часто в отдельных режимах; последняя версия Gen-4.5 сокращает разрыв. |
| Разговорное/текстовое редактирование пикселей | Да — «редактировать как беседу» (без масок). | Частичное — редактирование доступно, но рабочие процессы с использованием масок и ключевых кадров по-прежнему распространены. | Runway имеет мощные инструменты редактирования; Runway заявляет о сильных инструкциях по преобразованию (зависит от версии). |
| Управление начальным/конечным кадром и ссылка на камеру | Да — подробно описаны начальный/конечный кадр и движения опорной камеры. | Ограниченный / развивающийся | Взлетно-посадочная полоса: улучшение управления; не совсем тот же UX. |
| Генерация длинных клипов (высокая точность) | до ~2 минут (1080p, 30 кадров в секунду) в материалах о продукте и сообщениях сообщества; | Veo 3.1: высокая согласованность, но в более ранних версиях значения по умолчанию были короче; зависит от модели/настройки. | Runway Gen-4.5: высокие требования к качеству; продолжительность/точность воспроизведения варьируются. |
Вывод:
Публичная претензия Kling O1 на известность заключается в том, унификация рабочего процесса: предоставление единой модели полномочий на распознавание текста, изображений и видео, а также на выполнение как генерации, так и редактирования на основе расширенных инструкций в рамках одной семантической системы. Для разработчиков и команд, часто переключающихся между этапами «создание», «редактирование» и «расширение», такая консолидация может значительно ускорить итерации и снизить сложность инструментов. Улучшенная временная согласованность, контроль начального и конечного кадров и прагматичная интеграция с платформами делают её доступной для разработчиков.
API Kling Video o1 скоро будет доступен на CometAPI.
Разработчики могут получить доступ Клинг 2.5 Турб и API Veo3.1 через CometAPI, последние модели указаны на дату публикации статьи. Для начала изучите возможности модели в Детская Площадка и проконсультируйтесь с API-руководство для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API. CometAPI предложить цену намного ниже официальной, чтобы помочь вам интегрироваться.
Готовы к работе?→ Зарегистрируйтесь в CometAPI сегодня !
Если вы хотите узнать больше советов, руководств и новостей об искусственном интеллекте, подпишитесь на нас VK, X и Discord!