

17 июня Шанхайский единорог ИИ MiniMax официально открыл исходный код МиниМакс‑М1, первая в мире широкомасштабная гибридная модель вывода внимания с открытым весом. Объединяя архитектуру Mixture-of-Experts (MoE) с новым механизмом Lightning Attention, MiniMax-M1 обеспечивает значительный прирост скорости вывода, сверхдлительной обработки контекста и производительности сложных задач.
Предыстория и эволюция
Строя на фундаменте МиниМакс-Текст-01, которая привлекла молниеносное внимание к фреймворку Mixture-of-Experts (MoE) для достижения 1 миллиона токенов контекстов во время обучения и до 4 миллионов токенов при выводе, MiniMax-M1 представляет собой следующее поколение серии MiniMax-01. Предшествующая модель, MiniMax-Text-01, содержала 456 миллиардов общих параметров с 45.9 миллиардами активированных на токен, демонстрируя производительность на уровне топовых LLM, при этом значительно расширяя возможности контекста.
Основные характеристики MiniMax‑M1
- Гибридный MoE + Молниеносное внимание: MiniMax-M1 объединяет разреженную конструкцию Mixture-of-Experts (всего 456 миллиардов параметров, но только 45.9 миллиарда активируются на токен) с Lightning Attention, вниманием линейной сложности, оптимизированным для очень длинных последовательностей.
- Сверхдлинный контекст: Поддерживает до 1 миллионов входные токены — примерно в восемь раз превышающие предел в 128 К для DeepSeek‑R1 — что позволяет глубоко понимать объемные документы.
- Превосходная эффективность: При генерации 100 тыс. токенов Lightning Attention MiniMax‑M1 требует всего ~25–30% вычислений, используемых DeepSeek‑R1.
Варианты модели
- МиниМакс‑М1‑40К: контекст токенов 1 млн, бюджет вывода токенов 40 тыс.
- МиниМакс‑М1‑80К: контекст токенов 1 млн, бюджет вывода токенов 80 тыс.
В сценариях использования инструмента TAU-bench вариант 40K превзошел все модели с открытым весом, включая Gemini 2.5 Pro, продемонстрировав свои возможности агента.
Стоимость обучения и настройка
MiniMax-M1 был обучен от начала до конца с использованием крупномасштабного обучения с подкреплением (RL) в разнообразном наборе задач — от сложных математических рассуждений до сред разработки программного обеспечения на основе песочницы. Новый алгоритм, СИСПО (Clipped Importance Sampling for Policy Optimization) еще больше повышает эффективность обучения, отсекая веса выборки важности вместо обновлений на уровне токенов. Этот подход в сочетании с молниеносным вниманием модели позволил завершить полное обучение RL на 512 графических процессорах H800 всего за три недели при общей стоимости аренды $534,700.
Доступность и цены
MiniMax-M1 выпускается под торговой маркой Апач 2.0 Лицензия с открытым исходным кодом и доступ к ней возможен немедленно через:
- Репозиторий GitHub, включая веса моделей, сценарии обучения и контрольные показатели оценки.
- SiliconCloud хостинг, предлагающий два варианта — 40 K‑токенов («M1‑40K») и 80 K‑токенов («M1‑80K») — с планами по включению полной воронки токенов в 1 M.
- В настоящее время цены установлены на уровне 4 йены за миллион токены для ввода и 16 йены за миллион токены для вывода, с оптовыми скидками для корпоративных клиентов.
Разработчики и организации могут интегрировать MiniMax-M1 через стандартные API, выполнять тонкую настройку на основе данных, специфичных для домена, или развертывать локально для конфиденциальных рабочих нагрузок.
Производительность на уровне задач
| Категория задачи | Выделите | Относительная производительность |
|---|---|---|
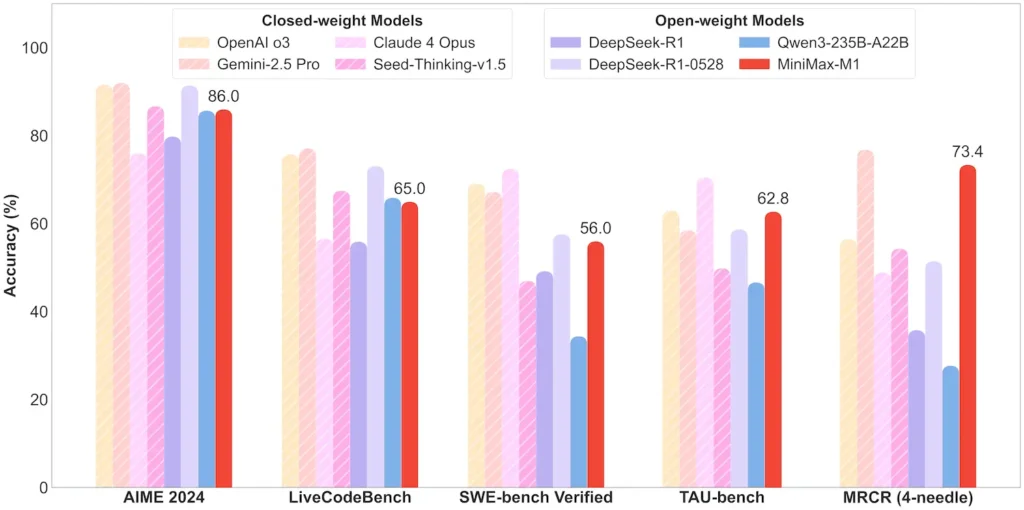
| Математика и логика | АИМЭ 2024: 86.0% | > Qwen 3, DeepSeek‑R1; почти закрытый исходный код |
| Понимание длинного контекста | Правитель (токены 4 K–1 M): Стабильный топ-уровень | Превосходит GPT‑4 при длине токена более 128 К |
| Программная инженерия | SWE‑bench (реальные ошибки GitHub): 56% | Лучшая среди открытых моделей; 2-я среди ведущих закрытых моделей |
| Использование агента и инструмента | TAU‑bench (симуляция API) | 62–63.5% против Близнецов 2.5, Клода 4 |
| Диалог и помощник | Многозадачность: 44.7% | Совпадает с Клодом 4, DeepSeek‑R1 |
| Факты QA | SimpleQA: 18.5% | Область для будущего улучшения |
Примечание: проценты и контрольные показатели взяты из официальных отчетов MiniMax и независимых новостных отчетов.
Технические инновации
- Гибридный стек внимания: Молниеносное внимание слои (линейная стоимость) чередуются с периодическим Softmax Attention (квадратичным, но более выразительным) для балансировки эффективности и мощности моделирования.
- Разреженная маршрутизация MoE: 32 экспертных модуля; каждый токен активирует только ~10% от общего числа параметров, что снижает стоимость вывода при сохранении емкости.
- CISPO Обучение с подкреплением: новый алгоритм «Оптимизации политики обрезанного IS-веса», который сохраняет редкие, но важные токены в обучающем сигнале, ускоряя стабильность и скорость RL.
Открытая версия MiniMax‑M1 открывает всем возможность сверхдлинного контекста и высокоэффективного вывода, сокращая разрыв между исследованиями и развертыванием крупномасштабного ИИ.
Первые шаги
CometAPI предоставляет унифицированный интерфейс REST, который объединяет сотни моделей ИИ, включая семейство ChatGPT, в единой конечной точке со встроенным управлением ключами API, квотами использования и панелями выставления счетов. Вместо жонглирования несколькими URL-адресами поставщиков и учетными данными.
Для начала изучите возможности моделей в Детская Площадка и проконсультируйтесь с API-руководство для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API.
Последняя интеграция MiniMax‑M1 API скоро появится на CometAPI, так что следите за обновлениями! Пока мы завершаем загрузку модели MiniMax‑M1, изучите наши другие модели на Страница моделей или попробуйте их в Площадка с искусственным интеллектом. Последняя модель MiniMax в CometAPI — это API Minimax ABAB7-Preview и API MiniMax Video-01 ,см.:
