Gemini 2.5 Flash разработан для сверхбыстрых ответов без компромиссов по качеству вывода. Он поддерживает мультимодальные входные данные — текст, изображения, аудио и видео — что делает его подходящим для самых разных приложений. Модель доступна через платформы Google AI Studio и Vertex AI, предоставляя разработчикам инструменты для бесшовной интеграции в различные системы.
Базовая информация (возможности)
Gemini 2.5 Flash представляет несколько выдающихся возможностей, которые выделяют его в семействе Gemini 2.5:
- Гибридное рассуждение: Разработчики могут задать параметр thinking_budget, точно контролируя, сколько токенов модель выделит на внутреннее рассуждение перед выдачей ответа.
- Фронт Парето: Находясь в оптимальной точке цена–производительность, Flash предлагает лучшее соотношение цена–интеллект среди моделей 2.5.
- Мультимодальная поддержка: Нативно обрабатывает текст, изображения, видео и аудио, обеспечивая более богатые разговорные и аналитические возможности.
- Контекст на 1 миллион токенов: Беспрецедентная длина контекста позволяет выполнять глубокий анализ и понимать длинные документы в одном запросе.
Версии модели
Gemini 2.5 Flash прошёл через следующие ключевые версии:
- gemini-2.5-flash-lite-preview-09-2025: Повышена удобство использования инструментов: улучшена производительность на сложных многошаговых задачах, рост показателя SWE-Bench Verified на 5% (с 48.9% до 54%). Повышена эффективность: при включении reasoning достигается более высокое качество вывода с меньшим числом токенов, снижая задержку и затраты.
- Preview 04-17: Ранний доступ с возможностью «thinking», доступен через gemini-2.5-flash-preview-04-17.
- Stable General Availability (GA): По состоянию на 17 июня 2025 года стабильная конечная точка gemini-2.5-flash заменяет превью, гарантируя промышленную надёжность без изменений API по сравнению с превью от 20 мая.
- Deprecation of Preview: Превью-эндпоинты были запланированы к отключению 15 июля 2025 года; пользователи должны перейти на GA-эндпоинт до этой даты.
По состоянию на июль 2025 года Gemini 2.5 Flash теперь публично доступен и стабилен (без изменений по сравнению с gemini-2.5-flash-preview-05-20). Если вы используете gemini-2.5-flash-preview-04-17, действующее превью-ценообразование будет сохраняться до запланированного вывода эндпоинта модели из эксплуатации 15 июля 2025 года, когда он будет отключён. Вы можете перейти на общедоступную модель "gemini-2.5-flash".
Быстрее, дешевле, умнее:
- Цели дизайна: низкая задержка + высокая пропускная способность + низкая стоимость;
- Общее ускорение в рассуждении, мультимодальной обработке и задачах с длинным текстом;
- Использование токенов снижено на 20–30%, что существенно уменьшает расходы на рассуждение.
Технические характеристики
Окно входного контекста: до 1 миллиона токенов, позволяя удерживать обширный контекст.
Выходные токены: способна генерировать до 8,192 токенов на ответ.
Поддерживаемые модальности: текст, изображения, аудио и видео.
Платформы интеграции: доступна через Google AI Studio и Vertex AI.
Цены: конкурентная модель тарификации по токенам, обеспечивающая экономичное развертывание.
Технические детали
В основе Gemini 2.5 Flash — крупная языковая модель на базе трансформеров, обученная на смеси веба, кода, изображений и видео. Ключевые технические характеристики включают:
Мультимодальное обучение: Обученная согласованию нескольких модальностей, Flash может бесшовно смешивать текст с изображениями, видео или аудио, что полезно для задач вроде суммаризации видео или подписи аудио.
Динамический процесс мышления: Реализует внутренний цикл рассуждения, в котором модель планирует и декомпозирует сложные запросы перед финальным выводом.
Настраиваемые бюджеты thinking: Параметр thinking_budget можно устанавливать от 0 (без рассуждения) до 24,576 токенов, балансируя между задержкой и качеством ответа.
Интеграция инструментов: Поддерживает Grounding with Google Search, Code Execution, URL Context и Function Calling, что позволяет выполнять реальные действия прямо из естественных запросов.
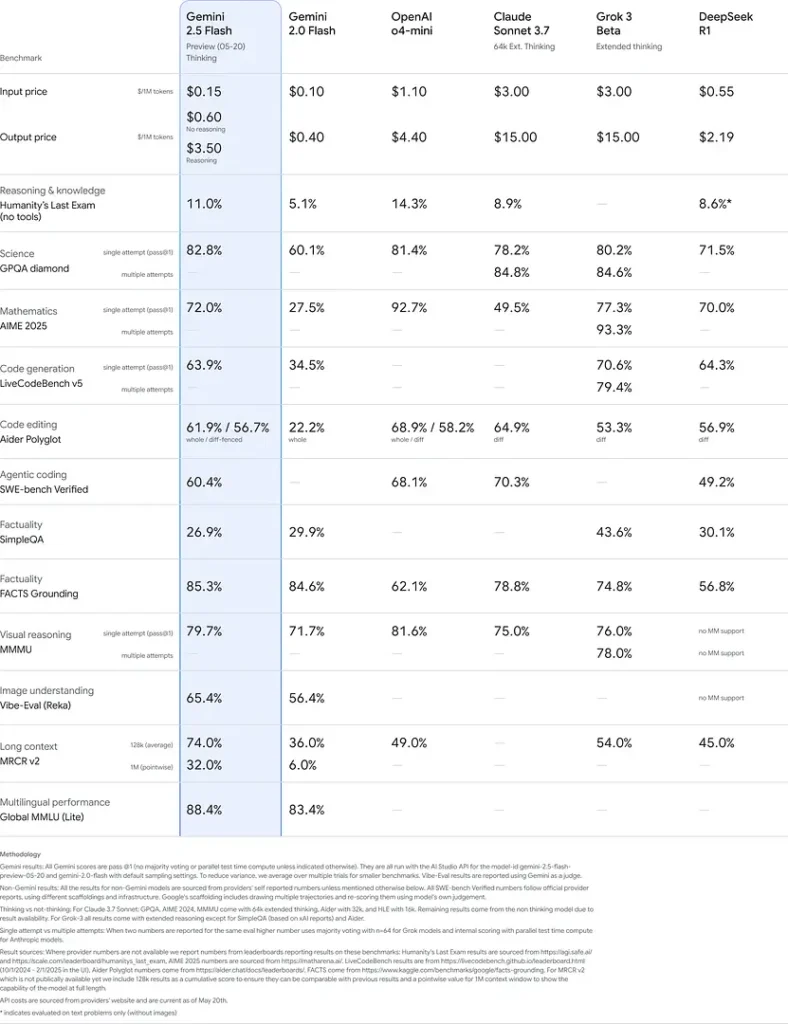
Результаты бенчмарков
В строгих оценках Gemini 2.5 Flash демонстрирует лидирующую в индустрии производительность:
- LMArena Hard Prompts: Уступил только 2.5 Pro на сложном бенчмарке Hard Prompts, показывая сильные многошаговые способности к рассуждению.
- Результат MMLU 0.809: Превышает средний уровень моделей с точностью 0.809 на MMLU, что отражает широкий кругозор и силу рассуждений.
- Задержка и пропускная способность: Достигает скорости декодирования 271.4 tokens/sec при 0.29 s Time-to-First-Token, что делает его идеальным для чувствительных к задержке нагрузок.
- Лидер по цене и производительности: При стоимости $0.26/1 M tokens Flash превосходит многих конкурентов, сохраняя или превосходя их по ключевым бенчмаркам.
Эти результаты указывают на конкурентные преимущества Gemini 2.5 Flash в рассуждении, научном понимании, решении математических задач, программировании, визуальной интерпретации и многоязычных возможностях:
Ограничения
Несмотря на мощь, у Gemini 2.5 Flash есть некоторые ограничения:
- Риски безопасности: Модель может демонстрировать «назидательный» тон и выдавать правдоподобные, но неверные или предвзятые ответы (галлюцинации), особенно на пограничных запросах. Строгий человеческий контроль остаётся необходимым.
- Лимиты скорости: Использование API ограничено лимитами (10 RPM, 250,000 TPM, 250 RPD на базовых уровнях), что может повлиять на пакетную обработку или высокие объёмы.
- Нижняя планка интеллекта: Хотя для модели класса Flash возможности исключительно высоки, она менее точна, чем 2.5 Pro, в наиболее требовательных агентных задачах, таких как продвинутое программирование или мультиагентная координация.
- Компромиссы по стоимости: Несмотря на лучшее соотношение цена–производительность, интенсивное использование режима thinking увеличивает общее потребление токенов, повышая стоимость для запросов с глубоким рассуждением.