Технические детали
- Адаптивное рассуждение:
Gemini 2.5 Flash-Liteподдерживает рассуждение по требованию, позволяя разработчикам выделять вычислительные ресурсы только при необходимости более глубокого анализа. - Интеграции с инструментами: Полная совместимость с родными инструментами Gemini 2.5, включая Grounding with Google Search, Code Execution, URL Context и Function Calling для бесшовных мультимодальных процессов.
- Model Context Protocol (MCP): Использует MCP от Google для получения данных из веба в реальном времени, обеспечивая актуальность и контекстную релевантность ответов.
- Варианты развертывания: Доступно через CometAPI, Gemini API, Vertex AI и Google AI Studio, с каналом предварительного просмотра для ранних последователей, чтобы экспериментировать и оставлять отзывы .
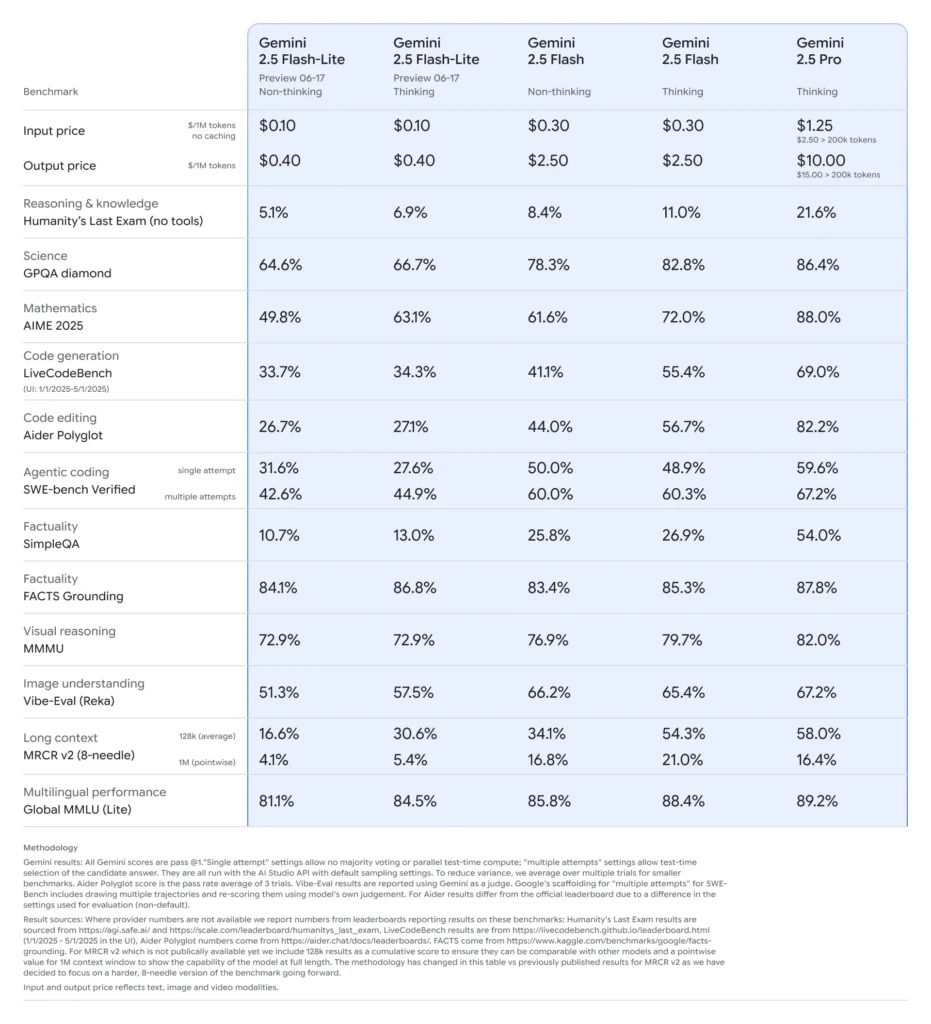
Показатели в бенчмарках Gemini 2.5 Flash-Lite
- Задержка: До 50% ниже медианное время отклика по сравнению с Gemini 2.5 Flash; типичная задержка — менее 100 мс на стандартных бенчмарках классификации и суммирования.
- Пропускная способность: Оптимизирован для высоконагруженных сценариев, устойчиво обрабатывая десятки тысяч запросов в минуту без деградации производительности.
- Соотношение цена/производительность: Демонстрирует снижение стоимости на 1 000 токенов на 25% по сравнению с версией Flash, что делает его Парето-оптимальным выбором для чувствительных к стоимости развертываний.
- Отраслевое внедрение: Ранние пользователи сообщают о бесшовной интеграции в продакшн-конвейеры, причем метрики производительности соответствуют или превосходят первоначальные прогнозы .
Идеальные сценарии использования
- Высокочастотные задачи низкой сложности: Автоматическая разметка, анализ тональности и массовый перевод
- Чувствительные к стоимости конвейеры: Извлечение данных из больших корпусов документов, периодическое пакетное суммирование
- Периферийные и мобильные сценарии: Когда критична задержка, а бюджеты ресурсов ограничены
Ограничения Gemini 2.5 Flash-Lite
- Статус Preview: Возможны изменения API до GA; интеграции должны учитывать потенциальные обновления версий.
- Без дообучения на лету: Нельзя загружать пользовательские веса; полагайтесь на инженеринг подсказок и системные сообщения.
- Сниженная креативность: Настроен для детерминированных задач с высокой пропускной способностью; меньше подходит для открытой генерации или «креативного» письма.
- Потолок ресурсов: Линейно масштабируется только до ~16 vCPUs; сверх этого рост пропускной способности снижается.
- Мультимодальные ограничения: Поддерживает ввод изображений/аудио, но с ограниченной точностью; не идеален для тяжелых задач компьютерного зрения или аудиотранскрибации.
- Компромисс контекстного окна : хотя принимается до 1 M tokens, на практике при таком масштабе может снижаться пропускная способность.