

В быстро развивающемся ландшафте искусственного интеллекта 2025 год стал свидетелем значительных достижений в больших языковых моделях (LLM). Среди лидеров — Qwen2.5 от Alibaba, модели V3 и R1 от DeepSeek и ChatGPT от OpenAI. Каждая из этих моделей привносит уникальные возможности и инновации. В этой статье рассматриваются последние разработки вокруг Qwen2.5, сравниваются ее функции и производительность с DeepSeek и ChatGPT, чтобы определить, какая модель в настоящее время лидирует в гонке ИИ.
Что такое Квен2.5?
Обзор
Qwen 2.5 — это новейшая плотная, только декодерная большая языковая модель Alibaba Cloud, доступная в нескольких размерах от 0.5 до 72 Б параметров. Она оптимизирована для выполнения инструкций, структурированных выходов (например, JSON, таблицы), кодирования и решения математических задач. С поддержкой более 29 языков и длиной контекста до 128 тыс. токенов Qwen2.5 предназначена для многоязычных и доменно-специфичных приложений.
Главные преимущества
- Мультиязычная поддержка: Поддерживает более 29 языков, рассчитан на пользователей по всему миру.
- Расширенная длина контекста: Обрабатывает до 128 тыс. токенов, что позволяет обрабатывать длинные документы и разговоры.
- Специализированные варианты: Включает такие модели, как Qwen2.5-Coder для задач программирования и Qwen2.5-Math для решения математических задач.
- Универсальный доступ: Доступно через такие платформы, как Hugging Face, GitHub и недавно запущенный веб-интерфейс на chat.qwenlm.ai.
Как использовать Qwen 2.5 локально?
Ниже приведено пошаговое руководство по 7 Б Чат контрольная точка; большие размеры отличаются только требованиями к графическому процессору.
1. Требования к оборудованию
| Модель | vRAM для 8-битной | vRAM для 4-бит (QLoRA) | Размер диска |
|---|---|---|---|
| Квен 2.5‑7Б | 14 ГБ | 10 ГБ | 13 ГБ |
| Квен 2.5‑14Б | 26 ГБ | 18 ГБ | 25 ГБ |
Одной карты RTX 4090 (24 ГБ) достаточно для вывода 7 Б при полной 16-битной точности; две такие карты или разгрузка ЦП плюс квантование могут справиться с 14 Б.
2. Установка
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. Быстрый сценарий вывода
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
The trust_remote_code=True флаг необходим, так как Qwen отправляет пользовательский Встраивание поворотной позиции обертка.
4. Тонкая настройка с помощью LoRA
Благодаря параметрически эффективным адаптерам LoRA вы можете провести специализированное обучение Qwen на ~50 тыс. пар доменов (например, медицинских) менее чем за четыре часа на одном графическом процессоре объемом 24 ГБ:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
Полученный файл адаптера (~120 МБ) можно объединить обратно или загрузить по требованию.
Необязательно: Запустите Qwen 2.5 как API
CometAPI выступает в качестве централизованного узла для API нескольких ведущих моделей ИИ, устраняя необходимость взаимодействия с несколькими поставщиками API по отдельности. CometAPI предлагает цену намного ниже официальной цены, чтобы помочь вам интегрировать Qwen API, и вы получите $1 на свой счет после регистрации и входа в систему! Добро пожаловать на регистрацию и знакомство с CometAPI. Для разработчиков, стремящихся интегрировать Qwen 2.5 в приложения:
Шаг 1: Установка необходимых библиотек:
bash
pip install requests
Шаг 2: получите ключ API
- Перейдите в CometAPI.
- Войдите в систему, используя свою учетную запись CometAPI.
- Выберите Главная.
- Нажмите «Получить ключ API» и следуйте инструкциям, чтобы сгенерировать ключ.
Шаг 3: Реализация вызовов API
Используйте учетные данные API для отправки запросов к Qwen 2.5. Заменить с вашим реальным ключом CometAPI из вашей учетной записи.
Например, в Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
Такая интеграция позволяет беспрепятственно внедрять возможности Qwen 2.5 в различные приложения, улучшая функциональность и удобство использования. Выберите “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” конечная точка для отправки запроса API и установки тела запроса. Метод запроса и тело запроса получены из нашего веб-сайта API doc. Наш веб-сайт также предоставляет тест Apifox для вашего удобства.
Пожалуйста, обратитесь к API Qwen 2.5 Макс для получения подробной информации об интеграции. CometAPI обновил последнюю версию API QwQ-32B.Дополнительную информацию о моделях в Comet API см. API документ.
Рекомендации и советы
| Сценарий | Рекомендация |
|---|---|
| Длинный документ Вопросы и ответы | Разбивайте текст на фрагменты размером ≤16 К токенов и используйте подсказки с расширенным поиском вместо простых контекстов размером 100 К, чтобы сократить задержку. |
| Структурированные результаты | Добавьте к системному сообщению префикс: You are an AI that strictly outputs JSON. Тренировка выравнивания Qwen 2.5 отлично подходит для ограниченной генерации. |
| Завершение кода | Поставьте temperature=0.0 и top_p=1.0 чтобы максимизировать детерминизм, затем выберите несколько лучей (num_return_sequences=4) для рейтинга. |
| Фильтрация безопасности | В качестве первого шага используйте пакет регулярных выражений с открытым исходным кодом «Qwen-Guardrails» от Alibaba или text-moderation-004 от OpenAI. |
Известные ограничения Qwen 2.5
- Чувствительность к быстрой инъекции. По данным внешних проверок, показатель успешности взлома Qwen 18‑VL составляет 2.5 % — это напоминание о том, что размер модели не гарантирует иммунитета от состязательных инструкций.
- Нелатинский шум OCR. При тонкой настройке для задач визуального языка сквозной конвейер модели иногда путает традиционные и упрощенные китайские глифы, что требует использования слоев коррекции, специфичных для конкретной области.
- Память графического процессора обрывается на отметке 128 К. FlashAttention‑2 смещает ОЗУ, но плотный прямой проход 72 Б по токенам 128 К по-прежнему требует >120 ГБ виртуальной оперативной памяти; практикующим следует использовать оконное обслуживание или KV-кэш.
Дорожная карта и экосистема сообщества
Команда Qwen намекнула на Квен 3.0, нацеленный на гибридную маршрутную магистраль (Dense + MoE) и унифицированную предварительную подготовку речи-зрения-текста. Между тем, экосистема уже размещает:
- Q-агент – агент цепочки мыслей в стиле ReAct, использующий Qwen 2.5‑14B в качестве политики.
- Китайская финансовая альпака – LoRA на Qwen2.5‑7B, обученный с 1 млн нормативных документов.
- Открытый плагин-интерпретатор – заменяет GPT‑4 на локальную контрольную точку Qwen в VS Code.
Посетите страницу Hugging Face «Коллекция Qwen2.5» для получения постоянно обновляемого списка контрольных точек, адаптеров и оценочных ремней.
Сравнительный анализ: Qwen2.5 против DeepSeek и ChatGPT
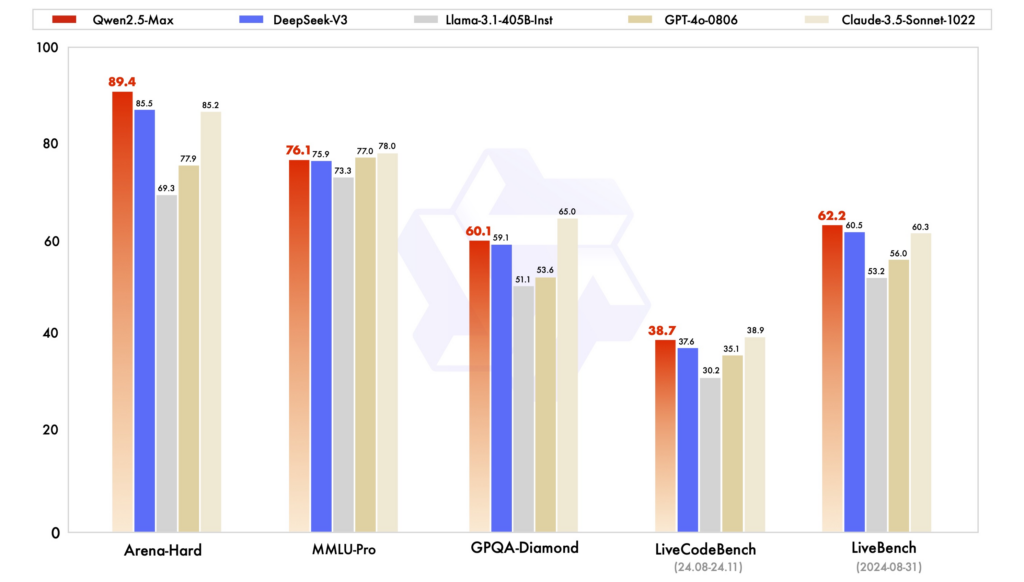
Тесты производительности: В различных оценках Qwen2.5 продемонстрировал высокую производительность в задачах, требующих рассуждений, кодирования и многоязыкового понимания. DeepSeek-V3 с архитектурой MoE отличается эффективностью и масштабируемостью, обеспечивая высокую производительность при сокращенных вычислительных ресурсах. ChatGPT остается надежной моделью, особенно в языковых задачах общего назначения.
Эффективность и стоимость: Модели DeepSeek отличаются экономичным обучением и выводом, используя архитектуры MoE для активации только необходимых параметров на токен. Qwen2.5, хотя и плотный, предлагает специализированные варианты для оптимизации производительности для определенных задач. Обучение ChatGPT включало значительные вычислительные ресурсы, что отразилось на его эксплуатационных расходах.
Доступность и наличие открытого исходного кода: Qwen2.5 и DeepSeek в разной степени приняли принципы открытого исходного кода, модели доступны на таких платформах, как GitHub и Hugging Face. Недавний запуск веб-интерфейса Qwen2.5 повышает его доступность. ChatGPT, хотя и не является открытым исходным кодом, широко доступен через платформу OpenAI и интеграции.
Заключение
Qwen 2.5 находится в золотой середине между услуги премиум-класса с закрытым весом и полностью открытые любительские модели. Сочетание разрешительного лицензирования, многоязычности, компетенции в длительном контексте и широкого диапазона шкал параметров делает его убедительной основой как для исследований, так и для производства.
По мере того, как ландшафт LLM с открытым исходным кодом стремительно развивается, проект Qwen демонстрирует, что Прозрачность и производительность могут сосуществоватьДля разработчиков, специалистов по обработке данных и политиков освоение Qwen 2.5 сегодня — это инвестиция в более плюралистичное, инновационное будущее ИИ.