

Qwen2.5-VL-32B API привлек внимание своей выдающаяся производительность в различных сложных задачах, сочетая в себе оба данные изображения и текста для обогащенного понимания мира. Разработано Алибаба, эта модель с 32 миллиардами параметров является усовершенствованием предыдущей Qwen2.5-VL серии, раздвигающие границы Рассуждения, основанные на ИИ и визуальное восприятие.

Обзор Qwen2.5-VL-32B
Qwen2.5-VL-32B — это передовая мультимодальная модель с открытым исходным кодом предназначен для обработки различных задач, связанных как с текстом, так и с изображениями. Благодаря 32 миллиарда параметров, он предлагает мощная архитектура для распознавание изображений, математические рассуждения, генерация диалогов, и многое другое. Его улучшенный возможности обучения, основанные на обучении с подкреплением, позволяют ему генерировать ответы, которые лучше соответствуют предпочтениям человека.
Основные характеристики и функции
Qwen2.5-VL-32B демонстрирует замечательные возможности во многих областях:
Понимание и описание изображения: Эта модель выделяется в анализ изображения, точно идентифицируя объекты и сцены. Он может генерировать подробные описания на естественном языке и даже предоставлять детальные идеи в атрибуты объектов и их взаимосвязи.
Математическое мышление и логика: Модель оснащена для решения сложных математических задач — от геометрия в алгебру—при использовании многошаговое рассуждение с четкой логикой и структурированными результатами.
Генерация текста и диалог: Благодаря своей расширенной языковой модели Qwen2.5-VL-32B генерирует связные и контекстно-релевантные ответы на основе входного текста или изображений. Он также поддерживает многооборотный диалог, что обеспечивает более естественное и непрерывное взаимодействие.
Визуальный ответ на вопрос: Модель может отвечать на вопросы, связанные с содержанием изображения, например распознавание объекта и описание сцены, предоставляя сложные возможности визуальной логики и вывода.
Технические основы Qwen2.5-VL-32B
Чтобы понять мощь Qwen2.5-VL-32B, важно изучить его технические принципы. Ниже приведены ключевые аспекты, которые способствуют его производительности:
- Мультимодальная предварительная подготовка: Модель была предварительно обучена с использованием крупномасштабные наборы данных состоящий из обоих текстовые и графические данные. Это позволяет ему изучать разнообразные визуальные и языковые особенности, способствуя беспрепятственному кросс-модальному пониманию.
- Архитектура трансформатора: Построен на прочной основе Трансформаторная архитектура, модель использует оба кодер и декодер структуры для обработки изображений и текстовых входов, генерируя высокоточные выходные данные. Его механизм самоконтроля позволяет сосредоточиться на критических компонентах входных данных, повышая их точность.
- Оптимизация обучения с подкреплением: Qwen2.5-VL-32B выигрывает от обучения с подкреплением, где он настраивается на основе обратной связи с человеком. Этот процесс гарантирует, что ответы модели более в соответствии с предпочтениями человека при оптимизации нескольких целей, таких как точность, логика и Беглость.
- Визуально-языковое выравнивание: Через контрастивное обучение и стратегии выравнивания, модель гарантирует, что оба визуальные особенности и текстовая информация правильно интегрированы в языковое пространство, что делает его очень эффективным для мультимодальные задачи.
Основные Производительность
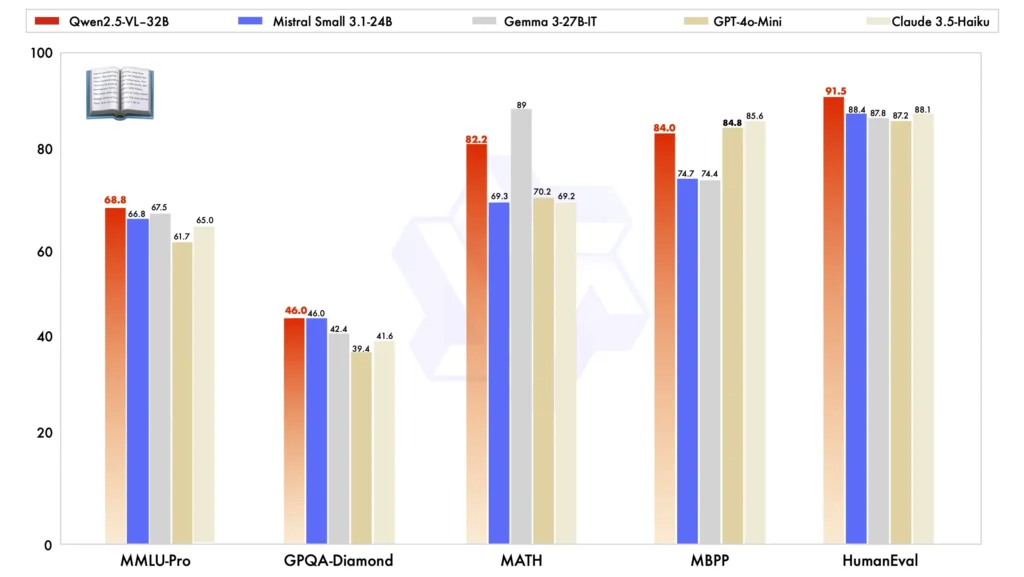
По сравнению с другими крупногабаритными моделями Qwen2.5-VL-32B выделяется по нескольким ключевым показателям, демонстрируя свои Превосходные характеристики в обоих мультимодальные и задания с простым текстом:
Сравнение моделей: Против других моделей, таких как Мистраль-Малый-3.1-24Б и Джемма-3-27Б-ИТ, Qwen2.5-VL-32B демонстрирует значительно улучшенные возможности. Примечательно, что он даже превосходит более крупный Qwen2-VL-72B в различных задачах.
Выполнение мультимодальных задач: В комплексе мультимодальные задачи как МММУ, MMMU-Pro и МатВистаМодель Qwen2.5-VL-32B отличается точностью результатов, что отличает ее от других моделей аналогичного размера.
MM-MT-Bench Тест производительности: По сравнению со своей предшественницей, Qwen2-VL-72B-Instruct, новая версия демонстрирует значительные улучшения, особенно в Логическое объяснение и мультимодальное рассуждение клапанов.
Производительность простого текста: В задачах на основе простого текста Qwen2.5-VL-32B проявил себя как лучший исполнитель в своем классе, предлагая улучшенная генерация текста, рассуждениеи общая точность.
Ресурсы проекта
Для разработчиков и энтузиастов ИИ, желающих глубже изучить Qwen2.5-VL-32B, доступно несколько ключевых ресурсов:
- Официальный веб-сайт: Проект Qwen2.5-VL-32B
- Модель HuggingFace: HuggingFace Qwen2.5-VL-32B-Инструкция
Реальные приложения
Универсальность Qwen2.5-VL-32B делает его пригодным для широкого спектра практическое применение в различных отраслях:
Интеллектуальное обслуживание клиентов: Модель может использоваться для автоматической обработки запросов клиентов, используя ее способность понимать и генерировать ответы на основе текста и изображений.
Помощь в обучении: Решая математические задачиперевод содержание изображенияи объясняя концепции, он может значительно улучшить процесс обучения студентов.
Аннотация изображения: В системах управления контентом Qwen2.5-VL-32B может автоматизировать генерацию подписи к изображениям и описывающие , что делает его бесценным инструментом для медиа и креативной индустрии.
Автономное вождение: Анализируя дорожные знаки и условия дорожного движения с помощью возможностей визуальной обработки, модель может предоставлять информацию в режиме реального времени для улучшения безопасность вождения.
Content Creation: В СМИ и рекламе модель может генерировать текст основанный на визуальных стимулах, помогающий создателям контента создавать захватывающие сюжеты для видеороликов и рекламы.
Будущие перспективы и вызовы
Хотя Qwen2.5-VL-32B представляет собой шаг вперед в области мультимодального ИИ, впереди еще много проблем и возможностей. Тонкая настройка модель для более конкретных задач, интегрируя ее с приложениями реального времени и улучшая ее Масштабируемость Обработка более сложных мультимодальных наборов данных — это области, требующие постоянных исследований и разработок.
Более того, по мере появления все большего количества моделей ИИ с аналогичными возможностями, этические проблемы окружающий контент, созданный искусственным интеллектом, смещение и конфиденциальность данных продолжают привлекать внимание. Обеспечение того, чтобы Qwen2.5-VL-32B и подобные модели обучались и использовались ответственно, будет иметь решающее значение для их долгосрочного успеха.
Похожие темы:Сравнение 8 самых популярных моделей ИИ 2025 года
Заключение
Qwen2.5-VL-32B — мощный инструмент в арсенале моделей ИИ, предназначенный для решения мультимодальные задачи с впечатляющей точностью и изысканностью. Интегрируя передовые усиление обучения, трансформаторная архитектура и визуально-языковое выравнивание, это не только превосходит предыдущие модели но также открывает захватывающие возможности для различных отраслей промышленности образование в автономное вождение. Будучи технологией с открытым исходным кодом, она предлагает разработчикам и пользователям ИИ огромный потенциал для экспериментов, оптимизации и внедрения в реальные приложения.
Как вызвать API Qwen2.5-VL-32B из CometAPI
1.Войти в cometapi.com. Если вы еще не являетесь нашим пользователем, пожалуйста, сначала зарегистрируйтесь.
2.Получите ключ API для доступа к учетным данным интерфейса. Нажмите «Добавить токен» в API-токене в личном центре, получите ключ токена: sk-xxxxx и отправьте.
-
Получите URL этого сайта: https://api.cometapi.com/
-
Выберите конечную точку Qwen2.5-VL-32B для отправки запроса API и установите тело запроса. Метод запроса и тело запроса получаются из наш веб-сайт API документ. Для вашего удобства наш сайт также предлагает тест Apifox.
-
Обработайте ответ API, чтобы получить сгенерированный ответ. После отправки запроса API вы получите объект JSON, содержащий сгенерированное завершение.