
Qwen3-Max-Preview — это новейшая флагманская модель Alibaba в линейке Qwen3, представляющая собой модель типа «микс экспертов» (MoE) с более чем триллионом параметров и сверхдлинным окном контекста токенов в 262 КБ, выпущенная в предварительной версии для корпоративного/облачного использования. Она ориентирована на *глубокое рассуждение, понимание длинных документов, кодирование и агентные рабочие процессы.
Основная информация и заголовки
- Имя/Метка:
qwen3-max-preview(Инструктировать). - Масштаб: Более 1 триллиона параметров (флагманский продукт с триллионом параметров). Это ключевой маркетинговый/статистический этап релиза.
- Контекстное окно: Знаки 262,144 (поддерживает очень длинные входные данные и многофайловые расшифровки).
- Режим (ы): Вариант «Instruct», настроенный на инструкции, с поддержкой мышление (преднамеренная цепочка мыслей) и не-думающий быстрые режимы в семействе Qwen3.
- Доступность: Предварительный доступ через Qwen Чат, Студия облачных моделей Alibaba (совместимые с OpenAI или конечные точки DashScope) и поставщики маршрутизации, такие как CometAPI.
Технические детали (архитектура и режимы)
- Архитектура: Qwen3-Max продолжает линию дизайна Qwen3, которая использует сочетание плотный + смесь экспертов (MoE) компоненты в более крупных вариантах, а также инженерные решения для оптимизации эффективности вывода для очень большого количества параметров.
- Режим мышления против режима немышления: Серия Qwen3 представила режим мышления (для многошаговых цепочек мыслительных процессов) и режим бездумья для более быстрых и кратких ответов; платформа предоставляет параметры для переключения этих моделей поведения.
- Контекстное кэширование/функции производительности: Списки модельных студий кэш контекста поддержка больших запросов для снижения затрат на повторный ввод и повышения пропускной способности в повторяющихся контекстах.
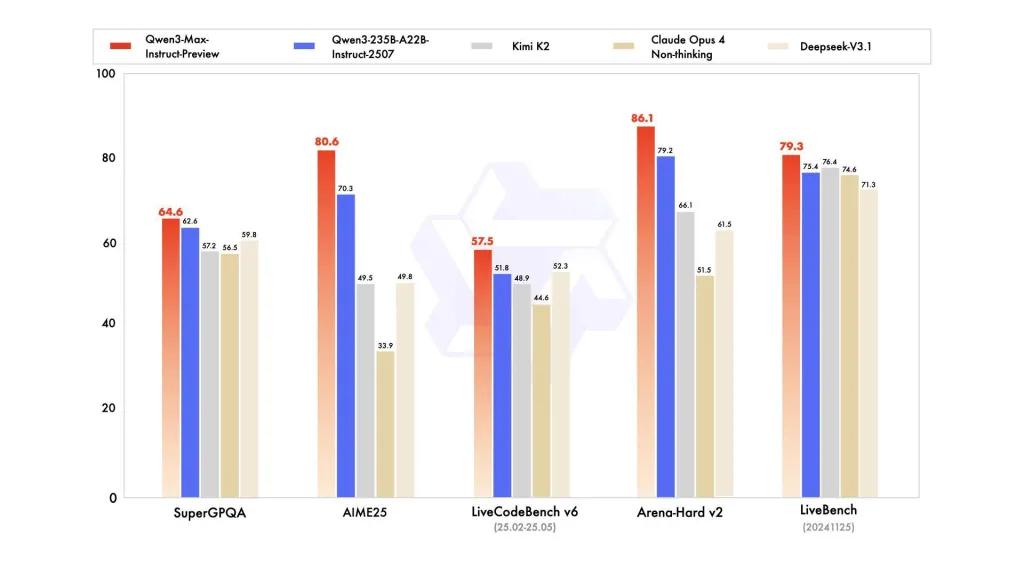
Контрольная производительность
В отчетах упоминаются варианты SuperGPQA, LiveCodeBench, AIME25 и другие наборы тестов/бенчмарков, где Qwen3-Max выглядит конкурентоспособным или лидирующим.
Ограничения и риски (практические замечания и замечания по безопасности)
- Непрозрачность для полного тренировочного рецепта/весов: В качестве предварительного ознакомления полный набор материалов по обучению, данным и весу, а также воспроизводимости может быть ограничен по сравнению с более ранними версиями Qwen3 с открытым весом. Некоторые модели семейства Qwen3 были выпущены с открытым весом, но Qwen3-Max предоставляется в виде контролируемой ознакомительной версии с облачным доступом. снижает воспроизводимость для независимых исследователей.
- Галлюцинации и реальность: В отчётах производителей утверждается об уменьшении галлюцинаций, но при реальном использовании всё равно будут обнаружены фактические ошибки и излишне самоуверенные утверждения — действуют стандартные оговорки для LLM. Перед серьёзным внедрением необходима независимая оценка.
- Стоимость при масштабировании: Благодаря огромному контекстному окну и высокой производительности, стоимость токена Может быть существенным для очень длинных запросов или производительности производства. Используйте кэширование, фрагментацию и контроль бюджета.
- Вопросы регулирования и суверенитета данных: Корпоративным пользователям следует проверять регионы Alibaba Cloud, местонахождение данных и правила соблюдения нормативных требований перед обработкой конфиденциальной информации. (Документация Model Studio включает конечные точки и примечания для конкретных регионов.)
Use cases
- Понимание документа/обобщение в масштабе: юридические справки, технические спецификации и многофайловые базы знаний (преимущество: 262К токен окно).
- Анализ кода в длинном контексте и помощь в написании кода в масштабе репозитория: понимание многофайлового кода, большие обзоры PR, предложения по рефакторингу на уровне репозитория.
- Сложные задачи на рассуждение и цепочку мыслей: математические конкурсы, многошаговое планирование, агентные рабочие процессы, в которых «мыслительные» следы способствуют прослеживаемости.
- Многоязычный корпоративный раздел вопросов и ответов и извлечение структурированных данных: Поддержка большого количества многоязычных корпусов и возможности структурированного вывода (JSON/таблицы).
Как вызвать API Qqwen3-max-preview из CometAPI
qwen3-max-preview Цены на API в CometAPI, скидка 20% от официальной цены:
| Входные токены | $0.24 |
| Выходные токены | $2.42 |
Необходимые шаги
- Войти в cometapi.com. Если вы еще не являетесь нашим пользователем, пожалуйста, сначала зарегистрируйтесь.
- Получите ключ API-интерфейса для доступа к учетным данным. Нажмите «Добавить токен» в API-токене в персональном центре, получите ключ токена: sk-xxxxx и отправьте.
- Получите URL этого сайта: https://api.cometapi.com/
Используйте метод
- Выберите конечную точку «qwen3-max-preview» для отправки API-запроса и задайте тело запроса. Метод запроса и тело запроса взяты из документации API на нашем сайте. Для вашего удобства на нашем сайте также доступен тест Apifox.
- Заменять с вашим реальным ключом CometAPI из вашей учетной записи.
- Введите свой вопрос или запрос в поле «Контент» — на него ответит модель.
- . Обработайте ответ API, чтобы получить сгенерированный ответ.
API-вызов
CometAPI предоставляет полностью совместимый REST API для беспроблемной миграции. Ключевые детали API документ:
- Основные параметры:
prompt,max_tokens_to_sample,temperature,stop_sequences - Конечная точка:
https://api.cometapi.com/v1/chat/completions - Параметр модели: qwen3-max-preview
- Аутентификация:
Bearer YOUR_CometAPI_API_KEY - Тип содержимого:
application/json.
Замените
CometAPI_API_KEYс вашим ключом; обратите внимание на базовый URL-адрес.
Python (запросы) — совместимый с OpenAI
import os, requests
API_KEY = os.getenv("CometAPI_API_KEY")
url = "https://api.cometapi.com/v1/chat/completions"
headers = {"Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json"}
payload = {
"model": "qwen3-max-preview",
"messages": [
{"role":"system","content":"You are a concise assistant."},
{"role":"user","content":"Explain the pros and cons of using an MoE model for summarization."}
],
"max_tokens": 512,
"temperature": 0.1,
"enable_thinking": True
}
resp = requests.post(url, headers=headers, json=payload)
print(resp.status_code, resp.json())
Наконечник: используют max_input_tokens, max_output_tokensи модельной студии кэш контекста возможности при отправке очень больших контекстов для контроля стоимости и пропускной способности.
См. также Qwen3-Кодер