

2025 年 11 月 19–20 日,OpenAI 发布了两项相关但彼此不同的升级:GPT-5.1-Codex-Max,这是一款面向 Codex 的新型代理式编程模型,强调长时程编码、令牌效率以及用于维持多窗口会话的“压缩(compaction)”;以及 GPT-5.1 Pro,这是面向 ChatGPT Pro 层级的更新模型,针对复杂、专业工作中的更清晰、更强大的回答进行了调优。
什么是 GPT-5.1-Codex-Max,它试图解决什么问题?
GPT-5.1-Codex-Max 是 OpenAI 推出的一款专用于 Codex 的模型,针对需要持续、长时程推理与执行的编码工作流进行了调优。普通模型在面对极长上下文时往往容易出错——例如多文件重构、复杂代理循环或持续性的 CI/CD 任务——而 Codex-Max 则被设计为能够在多个上下文窗口之间自动压缩并管理会话状态,从而在单个项目跨越数千乃至更多 token 时,依然保持连贯工作。OpenAI 将 Codex-Max 定位为让具备代码能力的代理真正适用于长期工程工作的下一步。
什么是 GPT-5.1-Codex-Max,它试图解决什么问题?
GPT-5.1-Codex-Max 是 OpenAI 推出的一款专用于 Codex 的模型,针对需要持续、长时程推理与执行的编码工作流进行了调优。普通模型在面对极长上下文时往往容易出错——例如多文件重构、复杂代理循环或持续性的 CI/CD 任务——而 Codex-Max 被设计为能够在多个上下文窗口之间自动压缩并管理会话状态,从而使其在单个项目跨越数千乃至更多 token 时仍能连贯地继续工作。
OpenAI 将其描述为“在开发周期的每个阶段都更快、更智能、且更具令牌效率”,并明确表示它将取代 GPT-5.1-Codex,成为 Codex 各使用界面的默认模型。
功能概览
- **用于多窗口连续性的压缩机制:**裁剪并保留关键上下文,从而能够在数百万 token 和数小时的跨度上保持连贯工作。0
- **相较 GPT-5.1-Codex 更高的令牌效率:**在某些代码基准测试中,以相似推理投入实现同等推理效果时,“思考”token 最多可减少约 ~30%。
- **长时程代理式耐久性:**内部观察显示其可持续运行多小时/多天的代理循环(OpenAI 记录了超过 24 小时的内部运行)。
- **平台集成:**目前已可在 Codex CLI、IDE 扩展、云端及代码审查工具中使用;API 访问即将推出。
- **Windows 环境支持:**OpenAI 特别指出,Codex 工作流首次支持 Windows,从而扩大了真实世界开发者的覆盖范围。
它与竞品(例如 GitHub Copilot、其他编程 AI)相比如何?
相较于按请求逐次补全的工具,GPT-5.1-Codex-Max 被定位为更具自主性、适合长时程协作的伙伴。Copilot 及类似助手擅长编辑器内的短期补全,而 Codex-Max 的优势在于编排多步骤任务、跨会话维持连贯状态,以及处理需要规划、测试和迭代的工作流。尽管如此,大多数团队的最佳方案仍将是混合使用:用 Codex-Max 处理复杂自动化和持续性代理任务,用更轻量的助手处理行级补全。
GPT-5.1-Codex-Max 如何工作?
什么是“压缩(compaction)”,它如何支持长时间运行的工作?
其核心技术进展之一是压缩(compaction)——一种内部机制,会在裁剪会话历史的同时保留最关键的上下文内容,使模型能够跨多个上下文窗口继续保持连贯工作。实际而言,这意味着当 Codex 会话接近上下文上限时,会进行压缩(较早或价值较低的 token 会被总结/保留),从而为代理腾出一个新的窗口,并能够反复继续迭代直到任务完成。OpenAI 报告称,在内部运行中,该模型曾连续工作超过 24 小时。
自适应推理与令牌效率
GPT-5.1-Codex-Max 采用了改进的推理策略,从而提升了令牌效率:在 OpenAI 报告的内部基准中,Max 模型在使用显著更少“思考”token 的情况下,取得了与 GPT-5.1-Codex 相当或更好的表现——OpenAI 表示,在相同推理投入下运行 SWE-bench Verified 时,思考 token 大约减少了 30%。该模型还引入了面向非低延迟敏感任务的 “Extra High (xhigh)” 推理强度模式,使其能够投入更多内部推理以获得更高质量输出。
系统集成与代理式工具链
Codex-Max 正通过 Codex 工作流(CLI、IDE 扩展、云端及代码审查界面)进行分发,以便与真实开发者工具链交互。早期集成包括 Codex CLI 和 IDE 代理(VS Code、JetBrains 等),API 访问计划随后推出。其设计目标不仅是更智能的代码生成,更是打造一个能够执行多步骤工作流的 AI:打开文件、运行测试、修复失败、重构并重新运行。
GPT-5.1-Codex-Max 在基准测试和真实工作中的表现如何?
持续推理与长时程任务
评估显示,它在持续推理与长时程任务方面有可衡量的提升:
- **OpenAI 内部评估:**在内部实验中,Codex-Max 可在任务上持续工作“超过 24 小时”,且将 Codex 集成到开发者工具链后,提高了内部工程生产力指标(例如使用率和拉取请求吞吐量)。这些是 OpenAI 的内部说法,表明其在真实生产力层面带来了任务级改进。
- 独立评估(METR):METR 的独立报告测得 GPT-5.1-Codex-Max 的观测到的 50% 时间跨度(即模型能够连贯维持长任务的中位持续时间)约为 2 小时 40 分钟(置信区间较宽),相比 GPT-5 在可比测量中的 2 小时 17 分钟有所提升——这是在持续连贯性方面具有意义且符合趋势的改进。METR 的方法论和置信区间强调了波动性,但该结果支持了 Codex-Max 提升实际长时程表现的叙述。
代码基准
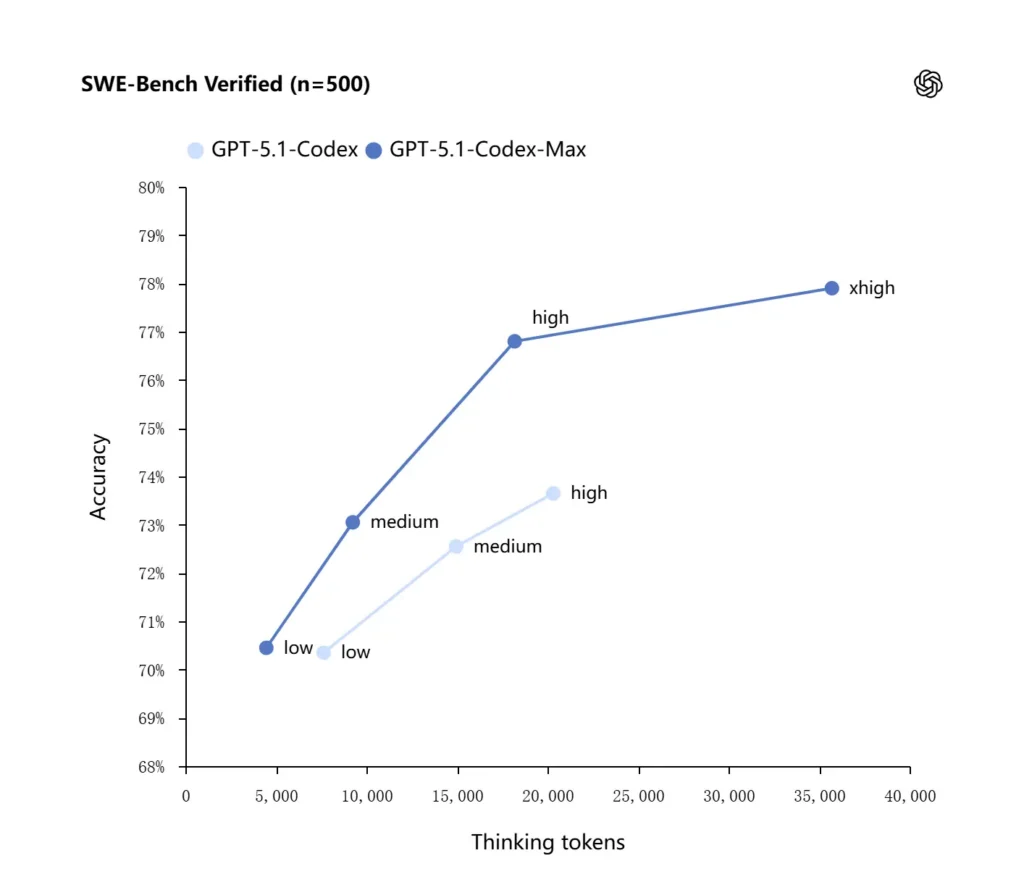
OpenAI 报告称,在前沿编码评测中结果有所提升,尤其是在 SWE-bench Verified 上,GPT-5.1-Codex-Max 以更高的令牌效率优于 GPT-5.1-Codex。公司强调,在相同“中等”推理投入下,Max 模型能产出更好的结果,同时“思考”token 使用量减少约 30%;对于允许更长内部推理的用户,xhigh 模式可以以增加延迟为代价进一步提升答案质量。
| GPT‑5.1-Codex (high) | GPT‑5.1-Codex-Max (xhigh) | |
| SWE-bench Verified (n=500) | 73.7% | 77.9% |
| SWE-Lancer IC SWE | 66.3% | 79.9% |
| Terminal-Bench 2.0 | 52.8% | 58.1% |
GPT-5.1-Codex-Max 与 GPT-5.1-Codex 相比如何?
性能与定位差异
- **范围:**GPT-5.1-Codex 是 GPT-5.1 家族中的高性能编码变体;Codex-Max 则明确是其代理式、长时程方向的继任者,旨在成为 Codex 及类似环境中的推荐默认模型。
- **令牌效率:**Codex-Max 在 SWE-bench 和内部使用中展现出显著的令牌效率提升(OpenAI 声称“思考”token 减少约 ~30%)。
- **上下文管理:**Codex-Max 引入了压缩和原生多窗口处理能力,以维持超出单一上下文窗口的任务;Codex 并未以相同规模原生提供这一能力。
- **工具链就绪度:**Codex-Max 作为默认 Codex 模型在 CLI、IDE 和代码审查界面中发布,表明生产级开发者工作流正在向其迁移。
何时使用哪种模型?
- **使用 GPT-5.1-Codex:**适合交互式编码辅助、快速修改、小型重构,以及所有相关上下文都能轻松放入单一窗口的低延迟使用场景。
- **使用 GPT-5.1-Codex-Max:**适合多文件重构、需要多轮迭代的自动化代理任务、类似 CI/CD 的工作流,或当你需要模型在多次交互中保持项目级视角时。
实用提示模式与最佳实践示例?
效果较好的提示方式
- 明确目标与约束:“重构 X,保留公共 API,保持函数名不变,并确保测试 A、B、C 通过。”
- **提供最小可复现上下文:**链接失败测试,附上堆栈跟踪和相关文件片段,而不是直接倾倒整个仓库。Codex-Max 会在需要时压缩历史。
- **对复杂任务使用分步指令:**将大型工作拆分为一系列子任务,并让 Codex-Max 迭代处理(例如:“1) 运行测试 2) 修复最严重的 3 个失败测试 3) 运行 linter 4) 总结改动”)。
- **要求解释与 diff:**同时请求补丁和简短理由,以便人工审查者快速评估安全性和意图。
示例提示模板
重构任务
“将
payment/模块重构为把支付处理提取到payment/processor.py。为现有调用方保持公共函数签名稳定。为process_payment()创建单元测试,覆盖成功、网络失败和无效卡片场景。运行测试套件,并以 unified diff 格式返回失败的测试和补丁。”
修复缺陷 + 测试
“测试
tests/test_user_auth.py::test_token_refresh失败,并出现 traceback 。调查根因,以最小改动提出修复,并添加一个单元测试以防止回归。应用补丁并运行测试。”
迭代式 PR 生成
“实现功能 X:添加已认证的
POST /api/export端点,用于流式返回导出结果。创建该端点,补充文档,编写测试,并提交一个包含摘要和人工检查项清单的 PR。”
对于大多数此类任务,从 medium 强度开始;当你需要模型跨多个文件和多轮测试迭代进行深度推理时,再切换到 xhigh。
如何访问 GPT-5.1-Codex-Max
当前可用位置
OpenAI 现已将 GPT-5.1-Codex-Max 集成到Codex 工具链中:Codex CLI、IDE 扩展、云端和代码审查流程默认使用 Codex-Max(你也可以选择 Codex-Mini)。API 可用性仍在准备中;GitHub Copilot 已提供包含 GPT-5.1 和 Codex 系列模型的公开预览。
开发者可以通过 CometAPI 访问 GPT-5.1-Codex-Max 和 GPT-5.1-Codex API。要开始使用,请在 Playground 中探索 CometAPI 的模型能力,并查阅 API 指南以获取详细说明。在访问之前,请确保你已登录 CometAPI 并获得 API 密钥。CometAPI 提供远低于官方价格的价格,以帮助你完成集成。
准备好开始了吗?→ 立即注册 CometAPI!
如果你想了解更多关于 AI 的技巧、指南和新闻,请在 VK、X 和 Discord 上关注我们!
快速开始(实用分步指南)
- **确认你拥有访问权限:**确认你的 ChatGPT/Codex 产品方案(Plus、Pro、Business、Edu、Enterprise)或开发者 API 方案支持 GPT-5.1/Codex 系列模型。
- **安装 Codex CLI 或 IDE 扩展:**如果你想在本地运行代码任务,请根据需要安装 Codex CLI 或适用于 VS Code / JetBrains / Xcode 的 Codex IDE 扩展。在受支持的配置中,工具会默认使用 GPT-5.1-Codex-Max。
- **选择推理强度:**大多数任务从 medium 强度开始。对于深度调试、复杂重构,或当你希望模型进行更多思考且不在意响应延迟时,切换到 high 或 xhigh 模式。对于快速的小修复,low 也是合理的。
- **提供仓库上下文:**给模型一个清晰的起点——仓库 URL,或一组文件加上一条简短指令(例如,“将 payment 模块重构为使用 async I/O 并添加单元测试,保持函数级契约不变”)。Codex-Max 会在接近上下文上限时压缩历史,并继续任务。
- **结合测试迭代:**当模型生成补丁后,运行测试套件,并将失败结果作为持续会话的一部分反馈回来。压缩机制和多窗口连续性使 Codex-Max 能保留重要的失败测试上下文并继续迭代。
结论:
GPT-5.1-Codex-Max 代表着代理式编程助手向前迈出的重要一步:它能够以更高效率和更强推理能力,持续处理复杂、长期运行的工程任务。其技术进展(压缩机制、推理强度模式、Windows 环境训练)使其非常适合现代工程组织——前提是团队为其配套保守的运营控制、清晰的人类参与策略以及健全的监控机制。对于谨慎采用它的团队而言,Codex-Max 有潜力改变软件设计、测试和维护的方式——将重复性的工程苦活,转变为人类与模型之间更高价值的协作。