

Gemini Embedding 2 — первая у Google по-настоящему мультимодальная модель эмбеддингов, которая отображает текст, изображения, аудио, видео и PDF в единое 3,072-мерное семантическое векторное пространство (с настраиваемым размером выхода). Она вводит обучение представлений Matryoshka (MRL), чтобы предоставлять вложенные/усечённые эмбеддинги, улучшенную многоязычную производительность (100+ языков) и оптимизированные настройки для задач-специфичных эмбеддингов (например, task:search, task:code).
Что такое Gemini Embedding 2?
Gemini Embedding 2 — единая модель эмбеддингов от Google, которая отображает несколько входных модальностей — текст, изображения, аудио, видео и документы — в единое семантическое векторное пространство. Каждый эмбеддинг (по умолчанию) — это 3,072-мерный вектор с плавающей точкой, представляющий семантическое значение входных данных, чтобы семантически похожие объекты (независимо от модальности) располагались близко друг к другу в векторном пространстве. Ключевые возможности:
- Широкий охват языков и форматов: одна модель принимает текст, изображения, аудио, видео и документы и помещает их в одно семантическое векторное пространство. Согласно документации, Gemini Embedding 2 фиксирует семантическое намерение на 100+ языках и принимает распространённые форматы файлов (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF) с конкретными ограничениями на запрос (например, до нескольких изображений или десятков секунд аудио/видео на запрос — см. «Как использовать» ниже).
- Настоящая мультимодальность: одна модель принимает текст, изображения, аудио, видео и документы и помещает их в одно семантическое векторное пространство, чтобы можно было сравнивать и извлекать данные между модальностями (например, текст → изображение, аудио → текст).
- Большая размерность по умолчанию с гибким усечением: модель по умолчанию выдаёт векторы размерности 3072, но использует Matryoshka Representation Learning (MRL), чтобы концентрировать наиболее важное семантическое содержание в первых измерениях, поэтому можно усекать до 1536, 768 (или ниже) с лишь умеренным падением качества извлечения. Это снижает затраты на хранение и вычисления.
Почему это важно. Исторически эмбеддинги были преимущественно только текстовыми или требовали отдельных энкодеров для каждой модальности со сложными слоями межмодального выравнивания. Gemini Embedding 2 снимает этот барьер благодаря нативной поддержке нескольких форматов — текстовый запрос может напрямую извлечь изображение или короткий клип по семантической близости без промежуточной транскрипции или ручного сопоставления. Это упрощает RAG (генерацию с дополнением извлечением), семантический поиск и мультимодальные конвейеры извлечения.
Ключевые возможности и функции (что нового)
1. Настоящая нативная мультимодальность (одно пространство эмбеддингов)
Одна модель принимает текст, изображения, аудио, видео и документы и помещает их в одно семантическое векторное пространство. Gemini Embedding 2 отображает текст, изображения, аудио, видео и документы в то же пространство эмбеддингов, поэтому кросс-модальное извлечение (текст→изображение, аудио→текст) работает напрямую без межмодельного выравнивания. Это снижает сложность конвейера и упрощает стеки RAG (Retrieval-Augmented Generation).
2. Векторы по умолчанию размерности 3,072 с настраиваемым выходом
Gemini Embedding 2 по умолчанию выдаёт векторы размерности 3072, но использует Matryoshka Representation Learning (MRL), чтобы концентрировать наиболее важное семантическое содержание в первых измерениях, поэтому можно усекать до 1536, 768 (или ниже) с лишь умеренным падением качества извлечения. Это снижает затраты на хранение и вычисления.
3. Matryoshka Representation Learning (MRL)
MRL создаёт «вложенные» эмбеддинги — как русские матрёшки — так что срезы меньшей размерности сохраняют высокоуровневую семантику. Это позволяет системам выбирать рабочую точку (компромисс хранение/точность) без поддержки нескольких отдельных моделей эмбеддингов. Ранние блоги и документация описывают эту технику как ключевую инновацию ради гибкости.
4. Подсказки по задачам / настраиваемые цели эмбеддингов
API принимает подсказки task (например, task:search, task:code retrieval, task:semantic-similarity), чтобы модель оптимизировала геометрию эмбеддингов под конкретные downstream-взаимосвязи — аналогично кондиционированию по задаче в ранних системах эмбеддингов, но расширено на мультимодальные входы.
5. Широта языков и модальностей
Согласно документации, Gemini Embedding 2 фиксирует семантическое намерение на 100+ языках и принимает распространённые форматы файлов (PNGs/JPEGs, MP4/MOV, MP3/WAV, PDF) с конкретными ограничениями на запрос (например, до нескольких изображений или десятков секунд аудио/видео на запрос — см. «Как использовать» ниже).
Результаты производительности
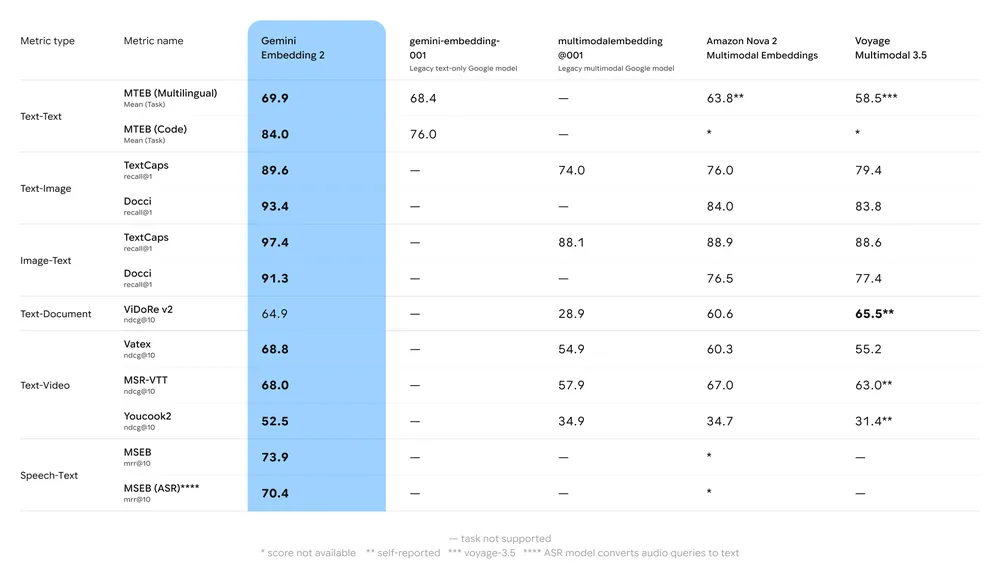
Краткое резюме бенчмарков:
- MTEB (Massive Text Embedding Benchmark): Сообщается о сильных позициях на многоязычных таблицах лидеров MTEB по английским и многоязычным задачам; анализы показывают заметный рост по сравнению с предыдущими моделями эмбеддингов Gemini и многими проприетарными альтернативами.
- Мультимодальное извлечение: Превосходит или сопоставим с ведущими одно-модальными эмбеддингами при кросс-модальной семантической близости (например, извлечение изображения по тексту) благодаря нативному мультимодальному обучению.
- Задержка и пропускная способность: Генерация эмбеддингов в облаке, но сценарии, чувствительные к задержке, могут предпочесть усечённые векторы или альтернативные лёгкие модели эмбеддингов для задач на периферии.
Gemini Embedding 2 vs gemini-embedding-001 и text-embedding-3-large
| Attribute | Gemini Embedding 2 (embedding-2) | Gemini Embedding (gemini-embedding-001) | OpenAI text-embedding-3-large |
|---|---|---|---|
| Release / availability | 10 марта 2026 — публичная предварительная версия (Gemini API / Vertex AI). | Ранний эмбеддинг Gemini (варианты только для текста) — GA ранее. | Анонсирован в январе 2024 (только текст, GA). |
| Modalities supported | Текст, изображения, аудио, видео, документы (PDF) — единое векторное пространство. | Текст (в основном). | Только текст (высококачественный многоязычный). |
| Default embedding dim. | 3072 (MRL / рекомендованное усечение: 1536, 768). | 3072 (для большого) — только текст. | 3072 (text-embedding-3-large). |
| Reported MTEB (example) | High-60s на MTEB; показывает 68.17 при 1536 в таблице вендора (см. доки). | gemini-embedding-001 сообщала ~68.32 среднее в некоторых списках лидеров. | ~64.6 (MTEB среднее, заявленное OpenAI для text-embedding-3-large). |
| Native audio/video support | Да (прямое эмбеддирование аудио/видео). | Нет (только текст). | Нет (только текст). |
| Typical use cases | Мультимодальное извлечение, RAG, семантический поиск по типам файлов, поиск по речи, поиск по видео. | Текстовое извлечение, многоязычный RAG. | Текстовое извлечение, семантический поиск, RAG — сильная многоязычная текстовая производительность. |
Технические характеристики и ограничения
Размер эмбеддинга по умолчанию и настраиваемый
- По умолчанию: 3,072 измерений.
- Настраиваемый: параметр
output_dimensionalityпозволяет запрашивать выход меньшей размерности для экономии хранения/CPU. Варианты использования с массивными векторными хранилищами часто уменьшают размерность до 512–1,024 ради снижения затрат, принимая некоторые компромиссы по точности.
Поддерживаемые модальности и лимиты на запрос
- Изображения: PNG, JPEG — до 6 изображений на запрос (по данным вендора).
- Видео: MP4, MOV — вендор сообщает до ~128 секунд видео для одного запроса на эмбеддинг.
- Аудио: MP3, WAV — вендор сообщает до ~80 секунд на один аудиовход.
- Документы: PDFs — до 6 страниц на запрос (по данным вендора).
- Лимит токенов для текста: модель поддерживает большие текстовые входы; существуют практические лимиты токенов на запрос (см. API-документацию и квоты Vertex AI).
Доступность и доступ
- Публичная предварительная версия: Gemini Embedding 2 выпущена как публичная предварительная версия и доступна через Gemini API и Vertex AI в Google Cloud для немедленного экспериментального использования
Часто задаваемые вопросы (FAQ)
Q1: Какие модальности поддерживает Gemini Embedding 2?
A: Текст, изображения (PNG/JPEG), видео (MP4/MOV), аудио (MP3/WAV) и PDF-документы — все отображаются в одном семантическом векторном пространстве.
Q2: Каков размер вектора по умолчанию для Gemini Embedding 2?
A: По умолчанию — 3,072 измерения. Вы можете запросить меньшую размерность выхода через API.
Q3: Доступна ли Gemini Embedding 2 уже сейчас?
A: Да — она анонсирована как публичная предварительная версия и доступна через Gemini API и Vertex AI (проверьте идентификатор модели gemini-embedding-2-preview и актуальный changelog).
Q4: Как она сравнивается с эмбеддингами других провайдеров?
A: Независимые тесты вендоров сообщают, что Gemini Embedding 2 входит в число топовых проприетарных моделей для многоязычного текста и показывает state-of-the-art для ряда мультимодальных задач. Точные рейтинги зависят от задачи и датасета; тестируйте на своих данных.
Q5: Нужно ли транскрибировать аудио, чтобы использовать Gemini Embedding 2?
A: Нет — Gemini Embedding 2 может принимать аудио напрямую и создавать эмбеддинги без предварительной транскрипции в текст, позволяя выполнять энд-ту-энд семантическое извлечение аудио.
Q6: Как снизить затраты на хранение векторов размерности 3,072?
A: Варианты включают запрос меньшей output_dimensionality, использование float16/квантования/PQ и хранение сжатых представлений в вашей векторной БД. Посты вендора содержат рабочие процессы и лучшие практики.
Что дальше — стоит ли внедрять сейчас?
Gemini Embedding 2 — значительный шаг к унификации мультимодального извлечения и упрощает архитектуры, которым ранее требовались отдельные ретриверы для текста, визуальных данных и речи. Ключевые точки принятия решения:
- Внедряйте скорее, если вашему продукту требуется устойчивое кросс-модальное извлечение (текст↔изображение/видео/аудио) или если поддержание нескольких одно-модальных ретриверов затратно и сложно.
- Пилотируйте сейчас, если хотите оценить усечение MRL и измерить компромисс стоимость/качество (держите гибридное развёртывание: 1536 как основной, 3072 для повторного ранжирования).
- Подождите, если ваша нагрузка крайне чувствительна к затратам и требуется только текстовое извлечение — топовые модели только для текста (например, OpenAI text-embedding-3-large) остаются конкурентоспособными и иногда дешевле, в зависимости от вашего конвейера и контракта.
Разработчики уже могут получить доступ к Gemini Embedding 2 и API OpenAI text-embedding-3 через CometAPI. Для начала изучите возможности модели в Playground и обратитесь к API guide за подробными инструкциями. Перед доступом убедитесь, что вы вошли в CometAPI и получили API-ключ. CometAPI предлагает цену значительно ниже официальной, чтобы помочь вам интегрироваться.
Готовы начать?→ Sign up for cometapi today !
Если хотите больше советов, гайдов и новостей об ИИ, следите за нами в VK, X и Discord!