
.webp&w=3840&q=75)
GLM-5.1 представляет собой поворотный момент в сфере ИИ. По мере того как китайские ИИ-компании ускоряют коммерциализацию и одновременно открывают передовые возможности, эта модель сокращает разрыв с проприетарными лидерами, такими как OpenAI GPT-5.4, Anthropic Claude Opus 4.6 и Google Gemini 3.1 Pro — особенно в реальных задачах программной инженерии. Обученная на той же архитектуре MoE с 744 млрд параметров, что и GLM-5, но существенно оптимизированная под агентные рабочие процессы, она превосходит там, где большинство LLM спотыкаются: длительные, неоднозначные, итеративные задачи, требующие планирования, экспериментов, отладки и самокоррекции на протяжении тысяч вызовов инструментов.
Сейчас CometAPI интегрирует GLM-5.1 и GLM-5, а разработчики также могут видеть другие ведущие западные модели и получать к ним доступ по очень низкой цене API (что также является преимуществом CometAPI по сравнению с другими конкурентами).
Что такое GLM-5.1?
GLM-5.1 — это новейшая флагманская языковая модель Z.ai и очередной шаг компании в сторону длительной, агентной работы по разработке ПО. По словам самой Z.ai, она предназначена для задач, которым требуется непрерывное исполнение, а не одноразовые ответы, и позиционируется как модель, способная планировать, выполнять, уточнять и сдавать результат в рамках одного длительного прогонa. В релиз-нотах Z.ai говорится, что GLM-5.1 создана с многоходовым контролируемым дообучением, обучением с подкреплением и системой оценки качества процесса, а также улучшает стабильность, согласованность и работу с инструментами на протяжённых задачах.
Это позиционирование важно, потому что GLM-5.1 не продаётся как «ещё одна чат-модель». Она нацелена на инженерные процессы, где модели нужно удерживать цель, справляться с промежуточными шагами и восстанавливаться после ошибок, не теряя нить — то есть как модель для автономного планирования, длительного исполнения, исправления багов и итерации стратегии, что совсем другой продукт по сравнению с «повседневным ассистентом» или короткоконтекстным coding-copilot.
Практическая деталь: GLM-5.1 — только текст, поддерживается в GLM Coding Plan и может использоваться в популярных кодовых агентах, таких как Claude Code и OpenClaw, что особенно важно для команд, которым нужна модель, встроенная в существующий разработческий процесс, а не замещающая его.
Ключевые технические спецификации (унаследованные и улучшенные от GLM-5):
- Архитектура: Mixture-of-Experts (MoE) с 744 миллиардами параметров в сумме и примерно 40 миллиардов активных параметров на инференс.
- Окно контекста: 203K–204.8K токенов (с поддержкой до 131K токенов вывода).
- Ключевые улучшения: DeepSeek Sparse Attention (DSA) для эффективной работы с длинным контекстом и снижения затрат на развёртывание; продвинутая асинхронная инфраструктура обучения с подкреплением (через «slime»-фреймворк Z.ai) для более эффективного пост-тренинга.
- Доступность: открытые веса (лицензия MIT на Hugging Face через zai-org/GLM-5.1), доступ по API через платформу Z.ai и агрегаторы вроде CometAPI, интеграция в инструменты GLM Coding Plan (совместима с Claude Code / OpenClaw).
В отличие от более ранних моделей GLM, ориентированных на общие способности или «vibe coding» с коротким контекстом, GLM-5.1 нацелена на производственные автономные агенты. Она способна самостоятельно планировать, выполнять, бенчмаркить, отлаживать и итеративно улучшать сложные инженерные проекты часами без вмешательства человека — возможности, которые делают её прямым конкурентом специализированных кодовых агентов от Anthropic и OpenAI.
Выход модели совпал с повышением цен на API примерно на ~10% (входные токены ~$0.54/M, выход ~$4.40/M), при этом она остаётся значительно дешевле эквивалентов вроде Anthropic Opus 4.6 (на 250–470% дороже).
Результаты тестов GLM-5.1
Z.ai позиционирует GLM-5.1 как самую сильную открыто-исходную модель и топ-3 в мире в агентном кодинге. Данные о производительности получены из официальных оценок на SWE-Bench Pro, NL2Repo, Terminal-Bench 2.0 и собственных долгосрочных сценариев.
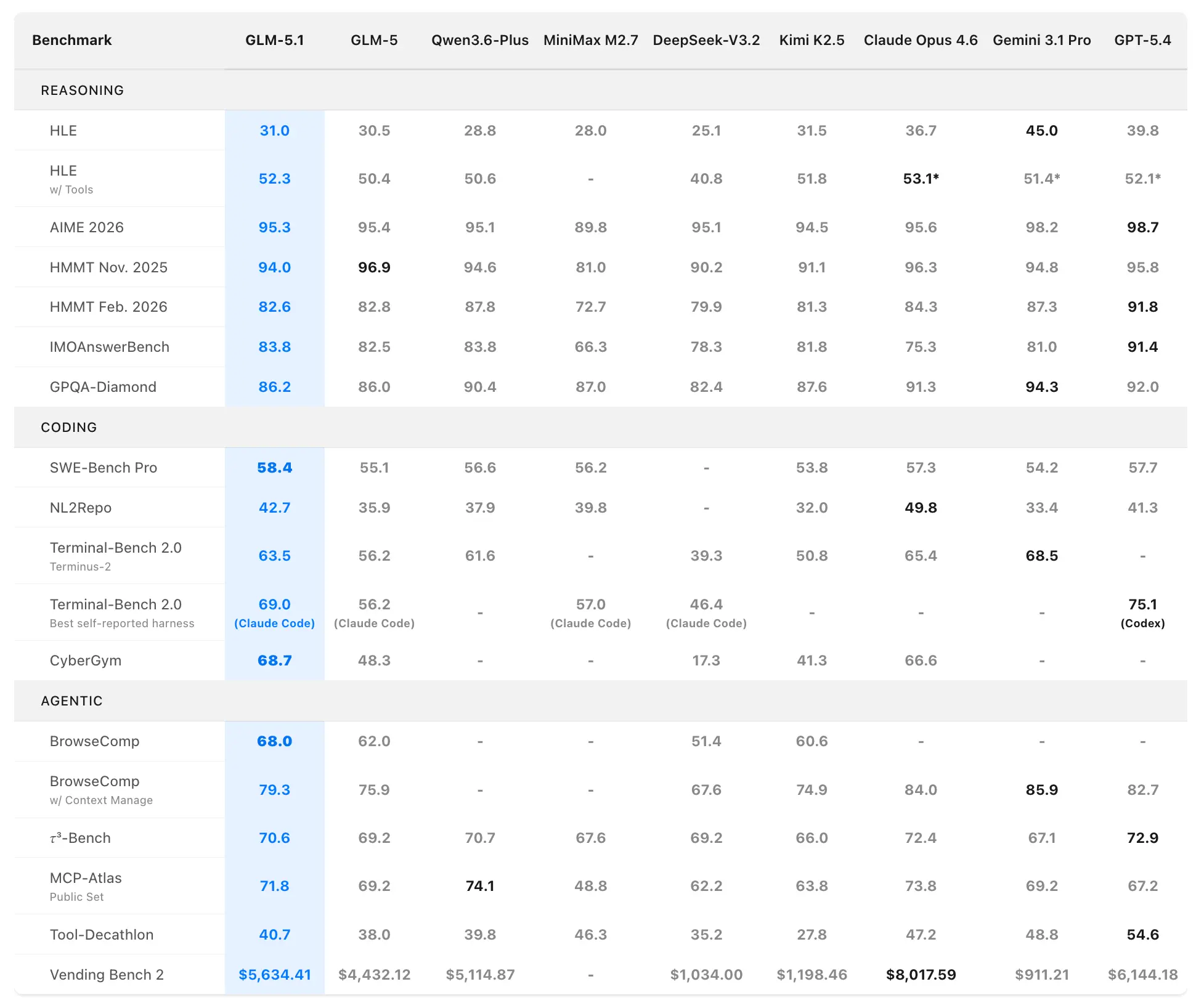
Бенчмарки по кодированию и агентности
SWE-Bench Pro (реалистичные задачи программной инженерии, требующие навигации по репозиторию, редактирования кода и функциональной верификации):
- GLM-5.1: 58.4 (новый state-of-the-art)
- GLM-5: 55.1
- GPT-5.4: 57.7
- Claude Opus 4.6: 57.3
- Gemini 3.1 Pro: 54.2
GLM-5.1 — первая отечественная (китайская) и открытая модель, заявившая лидерство в этом строгом бенчмарке, максимально приближенном к рабочим процессам профессиональных разработчиков.
NL2Repo (генерация полноценного репозитория по описанию на естественном языке):
- GLM-5.1: 42.7 (значительное преимущество над 35.9 у GLM-5)
- Конкурирующие модели — в диапазоне 32.0–49.8 (конкретные лидеры зависят от harness).
Terminal-Bench 2.0 (реальные терминальные и системные задачи):
- Обвязка Terminus-2: GLM-5.1 63.5 (против 56.2 у GLM-5)
- Лучший саморепорт (Claude Code): до 69.0.
В отдельной оценке на кодовом стенде (в стиле Claude Code) GLM-5.1 набрала 45.3, достигнув 94.6% от 47.9 у Claude Opus 4.6 и показав +28% к 35.4 у GLM-5.
Сводный рейтинг: #1 среди open-source, #1 среди китайских моделей, #3 в мире по совокупности SWE-Bench Pro + NL2Repo + Terminal-Bench.
Производительность на задачах с длинным горизонтом: ключевое отличие
Стандартные бенчмарки измеряют одноходовую или короткую сессию. GLM-5.1 раскрывается на длительных автономных прогонах:
- VectorDBBench Optimization (600+ итераций, 6,000+ вызовов инструментов): Начиная с «скелета» на Rust, GLM-5.1 итеративно переработала индексацию, сжатие, маршрутизацию и отсев, достигнув 21.5k QPS (в 6 раз выше прежнего 50-ходового рекорда в 3,547 QPS у Claude Opus 4.6) при сохранении ≥95% полноты на SIFT-1M. Наблюдался «ступенчатый» прогресс со структурными прорывами каждые 100–200 итераций.
- KernelBench Level 3 (полная оптимизация ML-моделей, 1,000+ ходов): Геометрическое среднее ускорение 3.6× по 50 сложным задачам (против 1.49× у max-autotune в torch.compile). GLM-5.1 продолжала улучшаться задолго после того, как GLM-5 вышла на плато; лишь Claude Opus 4.6 опередила её с 4.2×.
- Сборка веб-приложения настольного окружения Linux (8+ часов, открытый конец): Получив только текстовый промпт без стартового кода, GLM-5.1 автономно построила функциональное окружение в стиле Linux — с панелью задач, окнами, интеракциями и полировкой — тогда как прежние модели выдавали лишь базовые «скелеты».
Эти результаты демонстрируют способность GLM-5.1 сохранять связность, самооценивать результат, пересматривать стратегии и выходить из локальных оптимумов на крайне длинных горизонтах — способности, которые Z.ai целенаправленно закладывала для реальных агентных систем.
Чем GLM-5.1 отличается от GLM-5?
GLM-5 и GLM-5.1 тесно связаны, но позиционируются по-разному. GLM-5 — более ранняя базовая модель Z.AI для Agentic Engineering. Она спроектирована для сложной системной инженерии и дальнодействующих агентных задач, с открытыми весами, SOTA по кодированию и агентным возможностям, и производительностью в реальном программировании, приближающейся к Claude Opus 4.5. Она набирает 77.8 на SWE-bench Verified и 56.2 на Terminal Bench 2.0.
GLM-5.1, напротив, заявлена как следующий шаг к долгосрочным задачам и более надёжному устойчивому исполнению; улучшены стабильность, согласованность и работа с инструментами на длительных задачах, а также общая «согласованность» с Claude Opus 4.6. Иными словами, GLM-5 — это более ранняя инженерно-ориентированная базовая модель, а GLM-5.1 — флагман, ориентированный на выносливость задач.
Есть и архитектурные/тренировочные различия в поколении GLM-5, которые объясняют скачок. GLM-5 расширилась с 355B параметров (32B активированы) до 744B параметров (40B активированы), увеличила объём предобучающих данных с 23T до 28.5T, добавила асинхронный фреймворк обучения с подкреплением и интегрировала DeepSeek Sparse Attention для сохранения качества на длинных текстах при росте эффективности. Эти детали относятся к GLM-5, но служат фундаментом, на котором, судя по всему, построена GLM-5.1.
GLM-5.1 против других передовых моделей
GLM-5.1 выделяется как самый сильный открытый претендент, предлагая убедительное соотношение цена/производительность.
Таблица сравнения: основные бенчмарки по кодингу и агентности (апрель 2026)
| Model | SWE-Bench Pro | NL2Repo | Terminal-Bench 2.0 (Terminus-2) | Coding Harness Score | Long-Horizon Sustained? | Open-Source? | Approx. API Price (Input/Output per M tokens) |
|---|---|---|---|---|---|---|---|
| GLM-5.1 | 58.4 (SOTA) | 42.7 | 63.5 | 45.3 (94.6% of Opus) | Yes (600+ iter, 8 hrs) | Yes | $0.54 / $4.40 |
| GLM-5 | 55.1 | 35.9 | 56.2 | 35.4 | Limited | Yes | Lower (pre-hike) |
| GPT-5.4 | 57.7 | — | — | — | Strong | No | Higher |
| Claude Opus 4.6 | 57.3 | — | — | 47.9 | Strongest | No | ~250–470% more expensive |
| Gemini 3.1 Pro | 54.2 | — | — | — | Good | No | Higher |
Вердикт: GLM-5.1 побеждает по доступности открытого кода, стоимости и отдельным метрикам долгосрочного кодинга. Она на равных соперничает с закрытыми лидерами в агентных сценариях, демократизируя передовые возможности.
Сценарии применения GLM-5.1
1) Автономная разработка ПО
GLM-5.1 наиболее убедительна, когда задача напоминает реальный инженерный спринт: прочитать кодовую базу, спланировать изменение, реализовать его, протестировать, исправить регрессии и продолжать итерации до стабильного результата. Релиз-ноты Z.ai прямо подчёркивают автономное планирование, длительное исполнение, исправление ошибок и итерацию стратегии, что делает эту модель будто специально созданной для кодовых агентов и конвейеров поставки ПО.
2) Долгоработающие агентные процессы
Если ваш кейс включает множество вызовов инструментов, длинные многошаговые воркфлоу или повторяющуюся самокоррекцию, дизайн GLM-5.1 отлично подходит. Документация отмечает вызов инструментов, структурированный вывод, интеграцию MCP и поддержку потоковой работы с инструментами — всё это полезно, когда модель не просто отвечает, а действует внутри более крупной системы.
3) Корпоративная работа с знаниями и отчётность
GLM-5.1 также ориентирована на офисные задачи — PowerPoint, Word, PDF и Excel. Z.ai говорит об улучшениях в сложной организации контента, дизайне макетов, структурированном выводе и визуальной «полировке», что делает её подходящей для генерации отчётов, учебных материалов, исследовательских резюме и другой документно‑насыщенной работы.
4) Прототипирование фронтенда и артефакты
По заявлению Z.ai, GLM-5.1 хорошо подходит для генерации сайтов, интерактивных страниц и фронтенд-прототипирования, с меньшей шаблонностью структуры и более высоким качеством завершения задач. Это делает её удачным выбором для продуктовых команд, которым нужен быстрый мост от задания к прототипу, причём прототип должен быть пригодным к использованию, а не просто «красивым».
5) Сложные диалоги и следование инструкциям
Хотя главный сюжет — кодинг, GLM-5.1 также описывается как более сильная в открытом Q&A, сложных инструкциях и многоходовом взаимодействии. Это делает её полезной для ассистентных сценариев, где модель должна учитывать ограничения, пересматривать ответы и сохранять контекст на протяжении длинных разговоров.
Заключение: почему GLM-5.1 важен в 2026 году
GLM-5.1 — не просто очередной инкремент; это сигнал появления действительно способного открытого агентного ИИ. Превосходя в самых сложных «приближенных к реальности» инженерных бенчмарках и оставаясь доступной и открытой, Z.ai подняла планку для всей индустрии. Будь вы единственный разработчик, командный энтерпрайз или исследователь, GLM-5.1 предлагает непревзойдённую автономность для долгосрочных задач кодинга за долю стоимости проприетарных решений.
Хотите попробовать? Загляните в модель GLM-5.1 на CometAPI, репозиторий на Hugging Face или GLM Coding Plan для мгновенного доступа.