

17 июня 2025 года шанхайский лидер в области искусственного интеллекта MiniMax (также известный как Xiyu Technology) официально выпустил MiniMax-M1 (далее «M1») — первую в мире модель рассуждений с открытым весом, крупномасштабную, гибридную с вниманием. Объединяя архитектуру Mixture-of-Experts (MoE) с инновационным механизмом Lightning Attention, M1 достигает лидирующей в отрасли производительности в задачах, ориентированных на производительность, соперничая с ведущими системами с закрытым исходным кодом, сохраняя при этом непревзойденную экономическую эффективность. В этой подробной статье мы рассмотрим, что такое M1, как она работает, ее определяющие функции и практические рекомендации по доступу к модели и ее использованию.
Что такое MiniMax-M1?
MiniMax-M1 представляет собой кульминацию исследований MiniMaxAI в области масштабируемых, эффективных механизмов внимания. Основываясь на основе MiniMax-Text-01, итерация M1 объединяет молниеносное внимание с фреймворком MoE для достижения беспрецедентной эффективности как во время обучения, так и во время вывода. Эта комбинация позволяет модели поддерживать высокую производительность даже при обработке чрезвычайно длинных последовательностей — ключевое требование для задач, включающих обширные кодовые базы, юридические документы или научную литературу.
Основная архитектура и параметризация
В своей основе MiniMax-M1 использует гибридную систему MoE, которая динамически направляет токены через подмножество экспертных подсетей. Хотя модель включает в себя 456 миллиардов параметров в общей сложности, для каждого токена активируется только 45.9 миллиарда, что оптимизирует использование ресурсов. Эта конструкция черпает вдохновение из более ранних реализаций MoE, но совершенствует логику маршрутизации, чтобы минимизировать накладные расходы на связь между графическими процессорами во время распределенного вывода.
Молниеносное внимание и поддержка в длительном контексте
Определяющей особенностью MiniMax-M1 является его механизм молниеносного внимания, который радикально снижает вычислительную нагрузку на самовнимание для длинных последовательностей. Аппроксимируя матрицы внимания посредством комбинации локальных и глобальных ядер, модель сокращает FLOPs до 75% по сравнению с традиционными трансформаторами при обработке последовательностей из 100 тыс. токенов. Такая эффективность не только ускоряет вывод, но и открывает дверь для обработки контекстных окон размером до миллиона токенов без непомерных требований к оборудованию.
Каким образом MiniMax-M1 достигает вычислительной эффективности?
Повышение эффективности MiniMax-M1 обусловлено двумя основными инновациями: гибридной архитектурой Mixture-of-Experts и новым алгоритмом обучения с подкреплением CISPO, используемым во время обучения. Вместе эти элементы сокращают как время обучения, так и стоимость вывода, что позволяет проводить быстрые эксперименты и развертывание.
Гибридная маршрутизация смешанных экспертов
Компонент MoE использует 32 экспертные подсети, каждая из которых специализируется на различных аспектах рассуждений или задачах, специфичных для домена. Во время вывода обученный механизм стробирования динамически выбирает наиболее релевантных экспертов для каждого токена, активируя только те подсети, которые необходимы для обработки ввода. Эта выборочная активация сокращает избыточные вычисления и снижает требования к пропускной способности памяти, предоставляя MiniMax-M1 существенное преимущество в экономической эффективности по сравнению с моделями монолитных трансформаторов.
CISPO: новый алгоритм обучения с подкреплением
Для дальнейшего повышения эффективности обучения MiniMaxAI разработала CISPO (Clipped Importance Sampling with Partial Overrides), алгоритм RL, который заменяет обновления веса на уровне токенов на отсечение на основе выборки важности. CISPO смягчает проблемы взрывного роста веса, распространенные в крупномасштабных установках RL, ускоряет сходимость и обеспечивает стабильное улучшение политики в различных бенчмарках. В результате полное RL-обучение MiniMax-M1 на 512 графических процессорах H800 завершается всего за три недели, что обойдется примерно в 534,700 4 долларов США — это лишь малая часть стоимости, указанной для сопоставимых учебных запусков GPT-XNUMX.
Каковы показатели производительности MiniMax-M1?
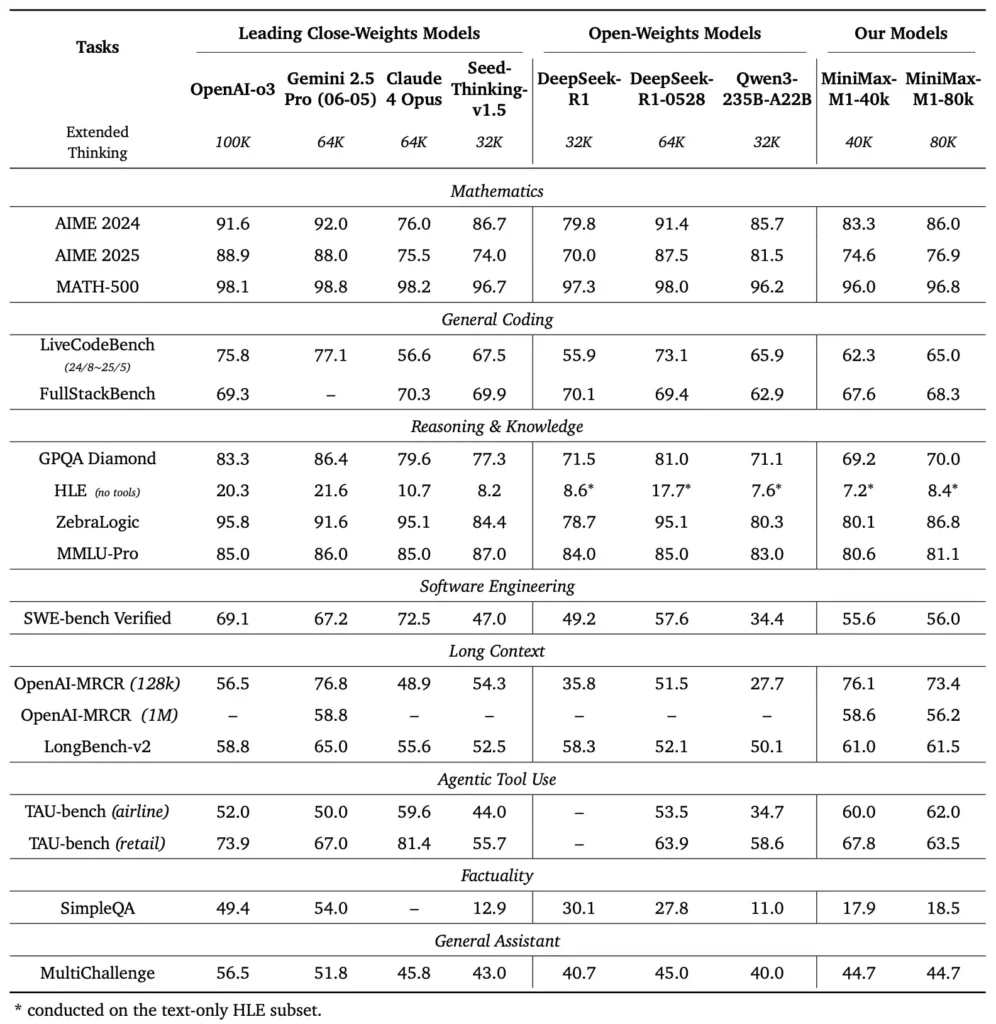
MiniMax-M1 демонстрирует превосходные результаты в различных стандартных и предметно-ориентированных тестах, демонстрируя свои способности в обработке длинных контекстных рассуждений, решении математических задач и генерации кода.
Задачи на рассуждение в длительном контексте
В обширных тестах на понимание документов MiniMax-M1 обрабатывает контекстные окна до 1,000,000 1 100 токенов, превосходя DeepSeek-RXNUMX в восемь раз по максимальной длине контекста и вдвое снижая требования к вычислительным ресурсам для последовательностей из XNUMX тыс. токенов. В таких тестах, как расширенная оценка контекста NarrativeQA, модель достигает самых высоких оценок понимания, что объясняется ее способностью молниеносного внимания эффективно улавливать как локальные, так и глобальные зависимости.
Разработка программного обеспечения и использование инструментов
MiniMax-M1 был специально обучен в изолированных средах разработки программного обеспечения с использованием крупномасштабного RL, что позволило ему генерировать и отлаживать код с замечательной точностью. В тестах кодирования, таких как HumanEval и MBPP, модель достигает показателей, сопоставимых или превышающих показатели Qwen3-235B и DeepSeek-R1, особенно в многофайловых кодовых базах и задачах, требующих перекрестных ссылок на длинные сегменты кода. Кроме того, ранние демонстрации MiniMaxAI демонстрируют способность модели интегрироваться с инструментами разработчика, от создания конвейеров CI/CD до рабочих процессов автоматического документирования.
Как разработчики могут получить доступ к MiniMax-M1?
Для содействия широкому внедрению MiniMaxAI сделал MiniMax-M1 свободно доступным как модель с открытым весом. Разработчики могут получить доступ к предварительно обученным контрольным точкам, весам модели и коду вывода через официальный репозиторий GitHub.
Открытый релиз на GitHub
MiniMaxAI опубликовал файлы модели MiniMax-M1 и сопутствующие скрипты под разрешительной лицензией с открытым исходным кодом на GitHub. Заинтересованные пользователи могут клонировать репозиторий по адресу https://github.com/MiniMax-AI/MiniMax-M1, где размещены контрольные точки для вариантов бюджета токенов 40K и 80K, а также примеры интеграции для распространенных фреймворков машинного обучения, таких как PyTorch и TensorFlow.
Конечные точки API и интеграция с облаком
Помимо локального развертывания, MiniMaxAI сотрудничает с крупными поставщиками облачных услуг для предоставления управляемых API-сервисов. Благодаря этим партнерствам разработчики могут вызывать MiniMax-M1 через конечные точки RESTful с SDK, доступными для Python, JavaScript и Java. API включают настраиваемые параметры для длины контекста, пороговые значения экспертной маршрутизации и бюджеты токенов, что позволяет пользователям настраивать производительность в соответствии со своими вариантами использования, одновременно отслеживая потребление вычислений в режиме реального времени.
Как интегрировать и использовать MiniMax-M1 в реальных приложениях?
Использование возможностей MiniMax-M1 требует понимания шаблонов его API, передовых методов работы с длинными контекстными подсказками и стратегий оркестровки инструментов.
Пример использования простого API
Типичный вызов API включает отправку полезной нагрузки JSON, содержащей входной текст и необязательные переопределения конфигурации. Например:
POST /v1/minimax-m1/generate
{
"input": "Analyze the following 500K token legal document and summarize the key obligations:",
"max_output_tokens": 1024,
"context_window": 500000,
"expert_threshold": 0.6
}
Ответ возвращает структурированный JSON со сгенерированным текстом, статистикой использования токенов и журналами маршрутизации, что позволяет осуществлять детальный мониторинг активаций экспертов.
Использование инструмента и MiniMax Agent
Наряду с базовой моделью MiniMaxAI представил MiniMax Agent, бета-фреймворк агента, который может вызывать внешние инструменты — от сред выполнения кода до веб-скрейперов — под капотом. Разработчики могут создать экземпляр сеанса агента, который связывает рассуждения модели с вызовом инструмента, например, для получения данных в реальном времени, выполнения вычислений или обновления баз данных. Эта парадигма агента упрощает сквозную разработку приложений, позволяя MiniMax-M1 функционировать как оркестратор в сложных рабочих процессах.
Лучшие практики и подводные камни
- Быстрое проектирование для длинных контекстов: Разбейте входные данные на связные сегменты, вставляйте резюме в логические интервалы и используйте стратегии «обобщить, а затем рассуждать», чтобы сохранять фокус модели.
- Компромисс между вычислительной мощностью и производительностью: Поэкспериментируйте с более низкими порогами эксперта или сокращенными бюджетами мышления (например, вариант 40 КБ) для приложений, чувствительных к задержкам.
- Мониторинг и управление: Используйте журналы маршрутизации и статистику токенов для аудита использования экспертов и обеспечения соблюдения бюджетов затрат, особенно в производственных средах.
Следуя этим рекомендациям, разработчики смогут использовать сильные стороны MiniMax-M1 — обширную обработку контекста и эффективные рассуждения — и одновременно снизить риски, связанные с развертыванием крупномасштабных моделей.
Как использовать MiniMax-M1?
После установки M1 можно вызывать с помощью простых скриптов Python или интерактивных блокнотов.
Как выглядит базовый сценарий вывода?
from minimax_m1 import MiniMaxM1Tokenizer, MiniMaxM1ForCausalLM
tokenizer = MiniMaxM1Tokenizer.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
model = MiniMaxM1ForCausalLM.from_pretrained("MiniMax-AI/MiniMax-M1-40k")
inputs = tokenizer("Translate the following paragraph to French: ...", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs))
В этом примере используется вариант с бюджетом 40 тыс.; замена на "MiniMax-AI/MiniMax-M1-80k" разблокирует полный бюджет рассуждений в 80 тыс. ().
Как вы справляетесь с очень длинными контекстами?
Для входных данных, превышающих типичные размеры буфера, M1 поддерживает потоковую токенизацию. Используйте stream=True флаг в токенизаторе для подачи токенов порциями и использования вывода с перезапуском контрольной точки для поддержания производительности при обработке последовательностей из миллиона токенов.
Как можно настроить или адаптировать M1?
Хотя базовых контрольных точек достаточно для большинства задач, исследователи могут применять тонкую настройку RL, используя код CISPO, включенный в репозиторий. Предоставляя пользовательские функции вознаграждения — от корректности кода до семантической точности — практики могут адаптировать M1 к рабочим процессам, специфичным для домена.
Заключение
MiniMax-M1 выделяется как новаторская модель ИИ, расширяющая границы понимания и рассуждения языка в длинном контексте. Благодаря своей гибридной архитектуре MoE, механизму молниеносного внимания и поддерживаемому CISPO режиму обучения модель обеспечивает высокую производительность при выполнении задач от юридического анализа до разработки программного обеспечения, при этом значительно сокращая вычислительные затраты. Благодаря своему выпуску с открытым весом и предложениям облачного API, MiniMax-M1 доступен широкому кругу разработчиков и организаций, стремящихся создавать приложения на базе ИИ следующего поколения. Поскольку сообщество ИИ продолжает изучать потенциал моделей с большим контекстом, инновации MiniMax-M1 готовы повлиять на будущие исследования и разработку продуктов во всей отрасли.
Первые шаги
CometAPI предоставляет унифицированный интерфейс REST, который объединяет сотни моделей ИИ, включая семейство ChatGPT, в единой конечной точке со встроенным управлением ключами API, квотами использования и панелями выставления счетов. Вместо жонглирования несколькими URL-адресами поставщиков и учетными данными.
Для начала изучите возможности моделей в Детская Площадка и проконсультируйтесь с API-руководство для получения подробных инструкций. Перед доступом убедитесь, что вы вошли в CometAPI и получили ключ API.
Последняя интеграция MiniMax‑M1 API скоро появится на CometAPI, так что следите за обновлениями! Пока мы завершаем загрузку модели MiniMax‑M1, изучите наши другие модели на Страница моделей или попробуйте их в Площадка с искусственным интеллектом. Последняя модель MiniMax в CometAPI — это API Minimax ABAB7-Preview и API MiniMax Video-01 ,см.:
