

ครอบครัว Claude 4 ใหม่ของ Anthropic – คล็อด โอปุส 4 และ คล็อด ซอนเนต์ 4 – ได้รับการประกาศเมื่อเดือนพฤษภาคม 2025 ว่าเป็นผู้ช่วย AI รุ่นถัดไปที่ได้รับการปรับให้เหมาะสมสำหรับการใช้เหตุผลและการเข้ารหัสขั้นสูง Opus 4 ได้รับการอธิบายว่าเป็นของ Anthropic *“รุ่นที่ทรงพลังที่สุด”*โดดเด่นในงานเขียนโค้ดและการใช้เหตุผลแบบหลายขั้นตอนที่ซับซ้อน Sonnet 4 เป็นการอัปเกรดประสิทธิภาพสูงจาก Sonnet 3.7 ก่อนหน้านี้ โดยให้การใช้เหตุผลทั่วไปที่แข็งแกร่ง การปฏิบัติตามคำสั่งที่แม่นยำ และความสามารถในการเขียนโค้ดที่แข่งขันได้
ด้านล่างนี้ เราจะเปรียบเทียบโมเดลเหล่านี้ในมิติทางเทคนิคที่สำคัญซึ่งมีความสำคัญต่อนักพัฒนา ได้แก่ ประสิทธิภาพในการใช้เหตุผลและการเข้ารหัส ความหน่วงและประสิทธิภาพ คุณภาพการสร้างโค้ด ความโปร่งใส การใช้เครื่องมือ การบูรณาการ ต้นทุน/ประสิทธิภาพ ความปลอดภัย และกรณีการใช้งานการปรับใช้ การวิเคราะห์นี้ใช้การประกาศและเอกสารของ Anthropic เกณฑ์มาตรฐานอิสระ และรายงานของอุตสาหกรรม เพื่อให้มีมุมมองที่ครอบคลุมและทันสมัย
Claude Opus 4 และ Claude Sonnet 4 คืออะไร?
Claude Opus 4 และ Claude Sonnet 4 เป็นสมาชิกใหม่ล่าสุดของตระกูล Claude 4 ของ Anthropic ซึ่งออกแบบมาเป็นโมเดลภาษาที่ใช้เหตุผลแบบผสมผสานที่ผสมผสานห่วงโซ่ความคิดภายในเข้ากับการใช้เครื่องมือแบบไดนามิก โมเดลทั้งสองนี้มีนวัตกรรมสำคัญสองประการ:
- บทสรุปการคิด:สร้างภาพรวมโดยอัตโนมัติของขั้นตอนการใช้เหตุผลของโมเดล ซึ่งปรับปรุงความโปร่งใสและช่วยให้นักพัฒนาเข้าใจเส้นทางการตัดสินใจ
- การคิดแบบขยาย (เบต้า): โหมดที่สร้างสมดุลระหว่างการใช้เหตุผลภายในกับการเรียกเครื่องมือภายนอก เช่น การค้นหาเว็บหรือการรันโค้ด เพื่อปรับประสิทธิภาพการทำงานของงานในเวิร์กโฟลว์ที่ซับซ้อนและยาวนาน
ที่มาและตำแหน่ง
- คล็อด โอปุส 4 ถูกวางตำแหน่งให้เป็นเครื่องคิดเหตุผลเรือธงของ Anthropic โดยสามารถสนับสนุนการดำเนินการงานอัตโนมัติได้นานถึง 2.5 ชั่วโมง และทำงานได้ดีกว่าโมเดลขนาดใหญ่ของคู่แข่ง เช่น Gemini 3 Pro ของ Google, โมเดลการใช้เหตุผล o4.1 ของ OpenAI และ GPT-XNUMX ในการเขียนโค้ดและใช้งานเครื่องมือที่มีการเปรียบเทียบประสิทธิภาพ
- คล็อด ซอนเนต์ 4 Claude Sonnet 3.7 ประสบความสำเร็จในฐานะซอฟต์แวร์ที่คุ้มต้นทุนและปรับให้เหมาะกับการใช้งานทั่วไป โดยซอฟต์แวร์นี้ให้ความสามารถในการปฏิบัติตามคำแนะนำ การเลือกเครื่องมือ และการแก้ไขข้อผิดพลาดที่เหนือกว่าเมื่อเทียบกับรุ่นก่อน ในขณะที่ยังคงรักษาปริมาณงานสูงสำหรับตัวแทนที่ติดต่อกับลูกค้าและเวิร์กโฟลว์ AI
มีจำหน่ายและราคา
- API และแพลตฟอร์มคลาวด์:สามารถเข้าถึงทั้งสองโมเดลได้ผ่าน Anthropic API เช่นเดียวกับตลาดคลาวด์ชั้นนำ ได้แก่ Amazon Bedrock, Google Cloud Vertex AI, Databricks, Snowflake Cortex AI และ GitHub Copilot
- ระดับฟรีและแบบชำระเงิน:ผู้ใช้ระดับฟรีสามารถเข้าถึง Claude Sonnet 4 ได้ ในขณะที่ Claude Opus 4 และฟีเจอร์การคิดขยายต้องสมัครสมาชิกแบบชำระเงิน
ความสามารถหลักของ Opus 4 และ Sonnet 4 เปรียบเทียบกันอย่างไร
แม้ว่าทั้งสองโมเดลจะมีสถาปัตยกรรมพื้นฐานและรากฐานด้านความปลอดภัยร่วมกัน แต่การปรับแต่งและประสิทธิภาพได้รับการปรับแต่งให้เหมาะกับกรณีการใช้งานที่แตกต่างกัน
เวิร์กโฟลว์การเขียนโค้ดและการพัฒนา
Claude Opus 4 สร้างมาตรฐานใหม่สำหรับวิศวกรรมซอฟต์แวร์ที่ขับเคลื่อนด้วย AI โดยได้รับคะแนนสูงสุดในเกณฑ์มาตรฐานอุตสาหกรรม เช่น SWE-bench (72.5%) และ Terminal-bench (43.2%) และรักษาการสร้างโค้ดอัตโนมัติสำหรับกระบวนการรีแฟกเตอร์ที่ใช้เวลานานหลายวัน การรองรับบริบทโทเค็น 32 K+ และการดำเนินการงานเบื้องหลัง (“Claude Code”) ช่วยให้นักพัฒนาสามารถโอนภาระการแก้ไขไฟล์หลายไฟล์ที่ซับซ้อนและการดีบักแบบวนซ้ำไปยังโมเดลได้ ในทางกลับกัน Claude Sonnet 4 แม้จะไม่ได้เทียบเท่ากับประสิทธิภาพสูงสุดอย่างแท้จริงของ Opus 4 แต่ก็ยังมีความแม่นยำมากกว่า Sonnet 20 โดยเฉลี่ย 3.7% ในเวิร์กโฟลว์ที่เน้นนักพัฒนา และโดดเด่นในด้านการสร้างต้นแบบอย่างรวดเร็ว การตรวจสอบโค้ด และความช่วยเหลือแบบโต้ตอบผ่านแชท
การใช้เหตุผล ความจำ และการวางแผน
ทั้งสองโมเดลนี้นำเสนอหน้าต่างหน่วยความจำแบบขยายที่เก็บรักษาบริบทไว้ตลอดเซสชันนานถึงเจ็ดชั่วโมง ซึ่งถือเป็นความก้าวหน้าสำหรับแอปพลิเคชันที่ต้องใช้การสนทนาอย่างต่อเนื่องหรือกระบวนการตัวแทนที่ดำเนินไปเป็นเวลานาน คุณสมบัติ "บทสรุปเชิงความคิด" ของทั้งสองโมเดลนี้จะแสดงภาพรวมที่กระชับของห่วงโซ่ความคิดภายใน ซึ่งช่วยเพิ่มความโปร่งใสให้กับเส้นทางการตัดสินใจที่ซับซ้อน บทสรุปของ Opus 4 นั้นมีรายละเอียดเป็นพิเศษ ซึ่งเหมาะสำหรับการวิเคราะห์ระดับการวิจัย ในขณะที่บทสรุปที่กระชับกว่าของ Sonnet 4 ให้ความสำคัญกับความชัดเจนและความเร็วในการให้บริการบอทสนับสนุนลูกค้าและอินเทอร์เฟซการแชทที่มีปริมาณมาก
ข้อพิจารณาด้านความปลอดภัยและจริยธรรม
ด้วยศักยภาพของ Claude Opus 4 ซึ่งแสดงให้เห็นจากความสามารถในการควบคุมงานหลายขั้นตอนที่อาจก่อให้เกิดความเสี่ยงต่อความปลอดภัยทางชีวภาพ Anthropic จึงได้นำนโยบายการปรับขยายตามความรับผิดชอบไปใช้ที่ระดับความปลอดภัยของ AI 3 (ASL-3) โดยบังคับใช้ตัวจำแนกประเภทป้องกันการเจลเบรก การเสริมความแข็งแกร่งด้านความปลอดภัยทางไซเบอร์ และโปรแกรมรางวัลภายนอกสำหรับการค้นพบช่องโหว่ Sonnet 4 แม้จะยังอยู่ภายใต้การควบคุมของโปรโตคอลฟิลเตอร์และทีมสีแดงที่แข็งแกร่ง แต่ได้รับการจัดอันดับ ASL-2 ซึ่งสะท้อนถึงโปรไฟล์ความเสี่ยงที่ต่ำกว่าซึ่งสอดคล้องกับสถานการณ์การใช้งานที่เป็นอิสระน้อยกว่า การควบคุมตนเองโดยสมัครใจของ Anthropic มุ่งหวังที่จะแสดงให้เห็นว่าความปลอดภัยที่เข้มงวดไม่จำเป็นต้องขัดขวางการใช้งานเชิงพาณิชย์
Benchmarks ประสิทธิภาพ
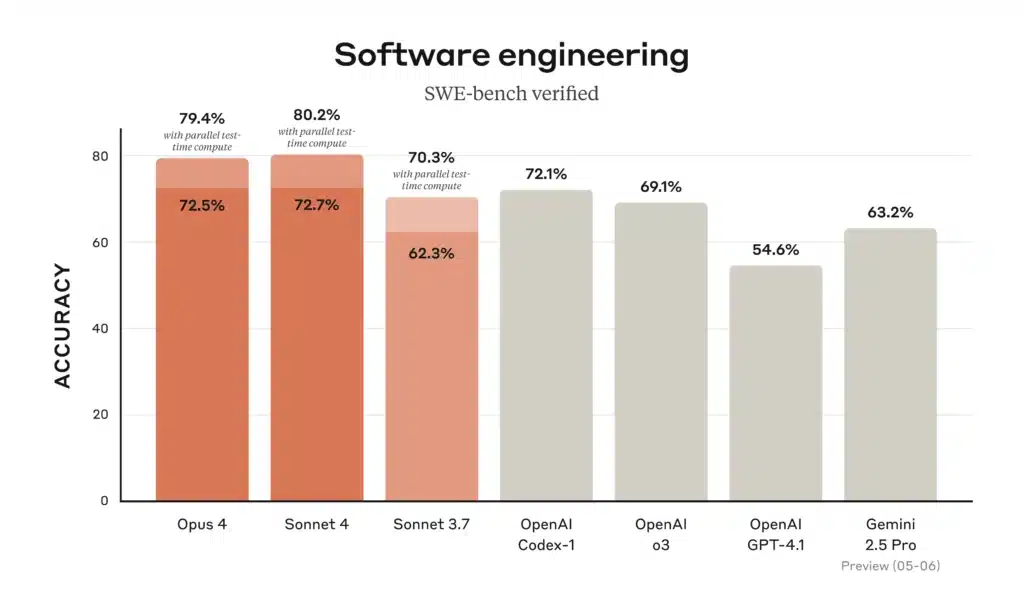
รูป: ความแม่นยำของวิศวกรรมซอฟต์แวร์ (SWE-bench Verified) สำหรับโมเดล Claude 4 เมื่อเทียบกับโมเดลก่อนหน้า (ยิ่งสูงยิ่งดี) Opus 4 และ Sonnet 4 ทั้งคู่ติดอันดับสูงสุดในเกณฑ์มาตรฐาน จาก Anthropic SWE-bench (วิศวกรรมซอฟต์แวร์) จากการทดสอบ Opus 4 ได้คะแนน ~72.5% และ Sonnet 4 ได้ ~72.7% (สูงกว่า Claude Sonnet 3.7 ที่ได้ ~62%) รูปภาพด้านบน (จาก Anthropic) แสดงให้เห็นว่าโมเดลใหม่ทั้งสองรุ่น (แถบสีส้ม) มีประสิทธิภาพเหนือกว่าเวอร์ชันก่อนหน้าของ Claude และแม้แต่ GPT-4.1 ในงานเขียนโค้ดจริง
- การเข้ารหัส (SWE-bench): Opus 4 = 72.5%; Sonnet 4 = 72.7% ทั้งสองรุ่นนั้นสูงกว่ารุ่นเก่ามาก (Sonnet 3.7 = 62.3%, GPT-4.1 ≈54.6%) ซึ่งยืนยันคำกล่าวอ้างของ Anthropic ที่ว่า ทั้งสอง แบบจำลอง Claude 4 เป็นผู้นำในการประเมินประสิทธิภาพการเข้ารหัส
- การใช้เหตุผลในระดับบัณฑิตศึกษา (GPQA Diamond): Anthropic รายงานว่า Opus 4 อยู่ที่ 74.9% เทียบกับ Sonnet 4 ที่ 70.0% ซึ่งเป็นเกณฑ์มาตรฐานภายในสำหรับการใช้เหตุผลทางวิทยาศาสตร์ที่ซับซ้อน Opus มีคะแนนเหนือกว่าเล็กน้อยในส่วนนี้
- ความรู้ (MMLU) : Opus 4: 87.4% เทียบกับ Sonnet 4: 85.4% ใน MMLU Opus สูงกว่าเล็กน้อย แต่ทั้งคู่ทำคะแนนได้ดีมาก (Anthropic ระบุว่า Sonnet 4 "ปรับปรุง" อย่างมีนัยสำคัญเมื่อเทียบกับ 3.7 ใน MMLU)
- การทดสอบการเข้ารหัสอิสระ: ในการประเมินแบบเปิด โมเดลทั้งสองทำงานได้ดีเยี่ยม ตัวอย่างเช่น การทดสอบของบุคคลที่สามในงานเขียนโค้ด Next.js ให้คะแนน Opus 4 9.5/10 และ Sonnet 4 9.25/10 (ทั้งคู่เสมอหรือสูงกว่า GPT-4.1 ในความท้าทายดังกล่าว) โมเดลทั้งสองสร้างโค้ดที่กระชับและถูกต้องได้น่าเชื่อถือมากกว่า LLM อื่นๆ
- เกณฑ์มาตรฐานอื่นๆ: ในการแข่งขันคณิตศาสตร์ระดับมัธยมศึกษาตอนปลาย (AIME) ทั้งสองแบบมีคะแนนต่ำ (~33% ซึ่งเป็นระดับความยากที่ทราบกันดีสำหรับ LLM ทั้งหมด) สำหรับงานการใช้เครื่องมือและงานตัวแทน (ตัวแปร TAU-bench) Anthropic รายงานผลลัพธ์ที่แข็งแกร่ง (>80% สำหรับงานย่อยบางงาน) สำหรับทั้งสองโมเดล โดยสรุปแล้ว Opus 4 มักจะมีข้อได้เปรียบด้านประสิทธิภาพเล็กน้อยในการทดสอบประสิทธิภาพที่ยาก แต่ Sonnet 4 ยังคงมีความสามารถสูงมาก โดยมักจะต้องแลกมาด้วยต้นทุนและความเร็ว
รวม, คล็อด โอปุส 4 เป็นรุ่นระดับสูงสุด (ดีที่สุดสำหรับงานที่ต้องการความแม่นยำสูง) ในขณะที่ คล็อด ซอนเนต์ 4 ให้พลังงานที่ใกล้เคียงกันแต่มีประสิทธิภาพสูงกว่ามาก ราคาและความพร้อมใช้งานสะท้อนให้เห็นดังนี้: Sonnet 4 เหมาะอย่างยิ่งสำหรับแอปพลิเคชันที่ปรับขนาดได้ (และผู้ใช้ฟรี) ในขณะที่ Opus 4 นั้นสงวนไว้สำหรับทีมที่ต้องการประสิทธิภาพสูงสุด
ราคา
ค่าใช้จ่ายโทเค็น (API): Opus 4 มีราคาอยู่ที่ 15 เหรียญสหรัฐฯ ต่อโทเค็นอินพุต 75 ล้านโทเค็น และ 4 เหรียญสหรัฐฯ ต่อโทเค็นเอาท์พุต 3 ล้านโทเค็น ในขณะที่ Sonnet 15 มีราคาเพียง 4 เหรียญสหรัฐฯ/XNUMX เหรียญสหรัฐฯ (อินพุต/เอาท์พุต) อัตราเหล่านี้ตรงกับราคา Claude vXNUMX ของ Anthropic ก่อนหน้านี้
ส่วนลด: Anthropic นำเสนอส่วนลดมากมายสำหรับ Opus 4: การแคชอย่างรวดเร็วสามารถลดต้นทุนโทเค็นได้มากถึง 90% และการประมวลผลแบบแบตช์ได้มากถึง 50% (ต้นทุนพื้นฐานที่ต่ำกว่าของ Sonnet 4 ทำให้ถูกกว่าแม้จะไม่มีฟีเจอร์เหล่านี้ก็ตาม)
รวมการสมัครสมาชิก: Sonnet 4 รวมอยู่ด้วยแม้ใน ฟรี แผน Claude ในขณะที่ Opus 4 ต้องใช้การสมัครใช้งาน Claude Pro/Team/Enterprise แบบชำระเงิน ในทางปฏิบัติ หมายความว่าการใช้งาน Sonnet 4 ทั้งหมด (ใน Claude Chat หรือ API) มีค่าใช้จ่ายต่ำมาก แต่ Opus 4 มีให้บริการเฉพาะลูกค้าที่ชำระเงินเท่านั้น
Sonnet 4 เปรียบเทียบกับ Claude Opus 4 ในกรณีการใช้งานอย่างไร?
แม้ว่า Opus 4 จะเป็นรุ่นเรือธงของ Anthropic ในด้านประสิทธิภาพสูงสุด แต่ Sonnet 4 ก็แกะสลักเฉพาะของตัวเองในด้านการใช้งานจริงและการเข้าถึง
ประสิทธิภาพเทียบกับความเหมาะสม
- ความสามารถแบบดิบ:ในการทดสอบประสิทธิภาพแบบตัวต่อตัว Opus 4 เหนือกว่า Sonnet 4 ในด้านการใช้เหตุผลที่ซับซ้อน ความแม่นยำในการสร้างโค้ด และเวิร์กโฟลว์หลายขั้นตอนอย่างต่อเนื่อง ซึ่งสะท้อนถึงสถานะ “ดีที่สุดในระดับเดียวกัน”
- อย่างมีประสิทธิภาพ:Sonnet 4 มอบประสิทธิภาพประมาณ 80 เปอร์เซ็นต์ของ Opus 4 ด้วยค่าใช้จ่ายในการคำนวณเพียงครึ่งเดียว ทำให้เป็นตัวเลือกที่น่าสนใจสำหรับงานประจำและโปรเจ็กต์ที่มีงบประมาณจำกัด
ใช้สถานการณ์กรณีและปัญหา
| ใช้กรณี | คล็อด ซอนเนต์ 4 | คล็อด โอปุส 4 |
|---|---|---|
| การเขียนโค้ดแบบรายวัน | ✔️ ความเร็วและความแม่นยำที่สมดุล | ✔️ ความแม่นยำสูงสุด |
| การวิจัยและปัญญาประดิษฐ์ทางวิทยาศาสตร์ | ✔️ เหมาะสำหรับการสรุปและสร้างต้นแบบ | ✔️ การให้เหตุผลเชิงลึกที่เหนือชั้น |
| เวิร์กโฟลว์ของตัวแทนอิสระ | ✔️ ตัวแทนระดับเริ่มต้น | ✔️ ความซับซ้อนสูง, ขอบเขตยาวไกล |
| การปรับใช้ที่คำนึงถึงต้นทุน | ✔️ ปรับให้เหมาะสมเพื่อประสิทธิภาพการใช้ทรัพยากร | ❌ เฉพาะระดับพรีเมี่ยมเท่านั้น |
ความพร้อมใช้งานและการบูรณาการกับเครื่องมือสำหรับนักพัฒนา
Claude แชทและแอพ: โมเดลทั้งสองสามารถเข้าถึงได้บนอินเทอร์เฟซ Claude ของ Anthropic (เว็บและแอป) Sonnet 4 พร้อมให้บริการแก่ผู้ใช้ทุกคน รวมถึงผู้ใช้ระดับฟรี ในขณะที่ Opus 4 สามารถใช้ได้เฉพาะแผนแบบชำระเงินเท่านั้น (Pro/Max/Team/Enterprise)
Anthropic API และแพลตฟอร์มคลาวด์: ทั้งสองโมเดลของ Claude สามารถเข้าถึงได้ผ่าน REST API ของ Anthropic และแสดงรายการอยู่ในแพลตฟอร์มคลาวด์หลัก Anthropic กล่าวว่าสิ่งนี้ "ทำให้ผู้พัฒนาเข้าถึงโมเดลและความสามารถในการใช้เหตุผลและตัวแทนได้ทันที"
IDE และปลั๊กอินตัวแก้ไข: Anthropic ได้บูรณาการ Claude 4 เข้ากับเวิร์กโฟลว์การเขียนโค้ดอย่างลึกซึ้ง รหัสคล็อด ผลิตภัณฑ์ฝัง Claude ไว้ในสภาพแวดล้อมของนักพัฒนาโดยตรง ส่วนขยายเบต้าสำหรับ VS Code และ JetBrains IDE ช่วยให้โมเดลเสนอการแก้ไขโค้ดแบบอินไลน์ภายในไฟล์ของคุณ นอกจากนี้ยังมีการรวม GitHub Actions อีกด้วย: คุณสามารถแท็ก Claude Code ในคำขอแบบดึงเพื่อแก้ไขการทดสอบ CI ที่ล้มเหลวโดยอัตโนมัติหรือตอบกลับความคิดเห็นของผู้ตรวจสอบ SDK ของ Claude Code ช่วยให้คุณสามารถเรียกใช้ Claude เป็นกระบวนการย่อยบนเครื่องภายในได้ กล่าวโดยย่อ Sonnet 4 และ Opus 4 สามารถทำงานเป็นโปรแกรมเมอร์คู่ในเครื่องมือที่คุ้นเคยได้แล้ว Anthropic ระบุว่า GitHub จะใช้ Sonnet 4 เป็นโมเดลเบื้องหลังตัวแทนการเข้ารหัสด้วยความช่วยเหลือของ AI ใหม่ และมีตัวเชื่อมต่อสำหรับ VS Code, JetBrains และ GitHub อยู่แล้ว ระบบนิเวศนี้หมายความว่านักพัฒนาสามารถใช้ประโยชน์จากความสามารถของ Claude ได้โดยไม่ต้องออกจากสภาพแวดล้อมปกติ
API และการทำงานอัตโนมัติของเวิร์กโฟลว์: ทั้งสองโมเดลรองรับการใช้งานตามโปรแกรมได้อย่างเต็มที่ API ของ Anthropic (v1) ได้รับการอัปเดตเพื่อให้คุณสามารถสลับโหมดการคิด กำหนดระดับความปลอดภัย และเชื่อมต่อตัวเชื่อมต่อเครื่องมือได้ ในทางปฏิบัติ การเรียกใช้ไคลเอนต์ Python อาจมีลักษณะเหมือนกันทุกประการ ยกเว้นชื่อโมเดล (claude-opus-4-20250514 vs claude-sonnet-4-20250514). บน โคเมทเอพีไอAPI มอบอินเทอร์เฟซรวมสำหรับเรียกใช้โมเดลใดโมเดลหนึ่ง นักพัฒนาสามารถรวมโมเดลเหล่านี้เข้ากับเวิร์กโฟลว์อัตโนมัติ (CI/CD, การตรวจสอบ, ไพล์ไลน์ข้อมูล) โดยใช้ภาษาที่ต้องการหรือไคลเอนต์ REST
แผนภูมิเปรียบเทียบ
| ลักษณะ | คล็อด โอปุส 4 | คล็อด ซอนเนต์ 4 |
|---|---|---|
| ประเภทรุ่น | โมเดล “Opus” ที่ใหญ่ที่สุด – มุ่งเน้นไปที่พลังการใช้เหตุผลสูงสุด | โมเดลขนาดกลาง – ความสมดุลของความเร็ว ต้นทุน และความสามารถ |
| หน้าต่างบริบท | โทเค็น 200 รายการ (บริบทขนาดใหญ่); เอกสารยาวมากหรือโค้ดหลายไฟล์ | โทเค็น 200 โทเค็น (บริบทใหญ่เดียวกัน) |
| ความยาวเอาต์พุต | โทเค็นสูงสุด 32 โทเค็นต่อการตอบกลับ (เหมาะสำหรับเอาท์พุตโค้ดที่ซับซ้อน) | โทเค็นสูงสุด 64K ต่อการตอบกลับ (เอาท์พุตที่ยาวกว่า) |
| ประสิทธิภาพการทำงาน (SWE-bench) | ~72.5–79% (เกณฑ์มาตรฐานการเข้ารหัสชั้นนำ) | ~72.7–80% (คะแนนการเข้ารหัสใกล้เคียงกันมาก) |
| ประสิทธิภาพการทำงาน (ไอคิวทั่วไป) | การใช้เหตุผลขั้นสูงที่แข็งแกร่ง (MMLU ~87%) มีประสิทธิภาพดีกว่า Sonnet เล็กน้อย | การใช้เหตุผลที่แข็งแกร่ง (MMLU ~85%) ต่ำกว่า Opus เล็กน้อยในงานที่ยาก |
| ใช้ตัวอย่างกรณี | เหมาะสำหรับ โครงการโค้ดที่ดำเนินมายาวนานการวิจัยเชิงลึก และการวางแผนตัวแทน (เช่น การรีแฟกเตอร์โครงการหลายไฟล์ การจำลองแบบใช้เวลานานหลายชั่วโมง) | เหมาะสำหรับ งานที่มีปริมาณมาก และตัวแทนแบบโต้ตอบ (เช่น แชทบอทสด การตรวจสอบโค้ด ระบบอัตโนมัติ CI) |
| การคิดแบบขยาย | ใช่ (โหมดการคิดแบบ 64K โทเค็น ยอดเยี่ยมสำหรับการใช้เหตุผลหลายขั้นตอนอย่างล้ำลึก) เหมาะสำหรับงานที่ได้รับประโยชน์จาก "ความคิด" ที่ยาวขึ้น | ใช่ (โหมดการคิดแบบโทเค็น 64K) รองรับด้วย โดยมีการสรุปเหตุผลที่ผู้ใช้มองเห็นได้ |
| การสนับสนุนเครื่องมือ | การใช้งานเครื่องมือแบบเต็มรูปแบบ (การค้นหาเว็บแบบคู่ขนาน การดำเนินการรหัส การ I/O ไฟล์ ฯลฯ) | ใช้เครื่องมือเต็มรูปแบบ (ความสามารถเท่ากัน) |
| หน่วยความจำและ “ไฟล์” | หน่วยความจำระยะยาวขั้นสูงผ่าน Files API โดดเด่นในการติดตามสถานะของโครงการ | คุณสมบัติหน่วยความจำเหมือนกัน สามารถจัดเก็บและเรียกคืนข้อเท็จจริงได้เช่นกัน |
| อินพุตต่อเนื่องหลายรูปแบบ | โค้ด+ข้อความที่แข็งแกร่ง สามารถประมวลผลภาพผ่านเครื่องมือ (การวิเคราะห์ภาพ) โดยเน้นไปที่งานข้อความ/การเข้ารหัสเป็นหลัก | รวมถึงความสามารถในการมองเห็นและ UI สามารถวิเคราะห์รูปภาพ/ภาพหน้าจอ และแม้แต่ "ใช้" UI ของซอฟต์แวร์ |
| เวลาแฝงและปริมาณงาน | ความหน่วงเวลาที่สูงขึ้น (การประมวลผลหนักขึ้น) เหมาะที่สุดสำหรับเวิร์กโฟลว์แบบแบตช์/อัตโนมัติที่ความลึกมีความสำคัญ | ความหน่วงต่ำกว่า (ตอบสนองเร็วขึ้น) ปรับให้เหมาะสมสำหรับการใช้งานแบบโต้ตอบและสตรีมมิ่ง |
| ความพร้อมที่จะให้บริการ | Anthropic API (Pro/Enterprise), AWS Bedrock, GCP Vertex เฉพาะแบบชำระเงินเท่านั้น | Anthropic API (ทุกระดับ), AWS Bedrock, GCP Vertex และฟรีสำหรับ Claude |
| การกำหนดราคา (โทเค็น) | $15 ต่ออินพุต M $75 ต่อเอาต์พุต M | $3 ต่ออินพุต M $15 ต่อเอาต์พุต M |
| ความปลอดภัย/การจัดตำแหน่ง | ความปลอดภัยระดับสูงสุด (มาตรการ ASL-3+) “มีโอกาสเกิดทางลัดน้อยที่สุด” | มาตรการความปลอดภัยที่เข้มงวดเท่ากัน (ASL-3) มีประสิทธิภาพมากกว่าเล็กน้อย การจัดตำแหน่งยังเหมือนเดิม |
สรุป
ในปี 2025 Claude Opus 4 และ Sonnet 4 ของ Anthropic ถือเป็นก้าวกระโดดครั้งสำคัญสำหรับ AI ที่เน้นนักพัฒนา โดยทั้งสองโครงการได้นำเสนอการใช้เหตุผลแบบมัลติโมดัลที่ขยายขอบเขต การรวมเครื่องมือที่ลึกซึ้งยิ่งขึ้น และความยาวบริบทที่ไม่เคยมีมาก่อน ซึ่งช่วยแก้ไขปัญหาในเวิร์กโฟลว์การพัฒนาสมัยใหม่ได้โดยตรง ด้วยการฝังโมเดลเหล่านี้ผ่าน API หรือแพลตฟอร์มคลาวด์ ทีมงานสามารถทำให้วงจรชีวิตของซอฟต์แวร์เป็นอัตโนมัติได้มากขึ้น ตั้งแต่การออกแบบโค้ดไปจนถึงการปรับใช้ โดยไม่สูญเสียความแม่นยำหรือการจัดแนว Opus 4 นำการใช้เหตุผลของ AI แนวหน้ามาสู่ภารกิจที่ซับซ้อนและเปิดกว้าง ในขณะที่ Sonnet 4 นำประสิทธิภาพความเร็วสูงที่เป็นมิตรกับงบประมาณมาสู่การเขียนโค้ดและความต้องการของเอเจนต์ในชีวิตประจำวัน
การปรับปรุงเหล่านี้ – การคิดแบบขยาย ไฟล์หน่วยความจำ เครื่องมือคู่ขนาน และการรวม IDE ที่ปรับให้เหมาะสม – ไม่ใช่แค่การเพิ่มขึ้นทีละน้อยเท่านั้น แต่ยังช่วยปรับเปลี่ยนวิธีที่นักพัฒนาโต้ตอบกับ AI อีกด้วย โดยเปลี่ยนจากการทำงานเพียงครั้งเดียวอย่างรวดเร็วเป็นการทำงานร่วมกันอย่างต่อเนื่องตลอดหลายชั่วโมงของการทำงาน ผลลัพธ์ก็คือ งานพัฒนาตามปกติจะเร็วขึ้นและเชื่อถือได้มากขึ้น ช่วยให้วิศวกรสามารถมุ่งเน้นไปที่ความคิดสร้างสรรค์และการดูแลได้ ดังที่ Anthropic กล่าวไว้ ด้วย Claude 4 “คุณสามารถใช้ Opus 4 เพื่อเขียนและรีแฟกเตอร์โค้ดสำหรับทั้งโครงการ” และ Sonnet 4 เพื่อขับเคลื่อน “งานพัฒนาประจำวัน”
เริ่มต้นใช้งาน
CometAPI มอบอินเทอร์เฟซ REST แบบรวมที่รวบรวมโมเดล AI หลายร้อยโมเดล รวมถึงตระกูล Claude ภายใต้จุดสิ้นสุดที่สอดคล้องกัน โดยมีการจัดการคีย์ API ในตัว โควตาการใช้งาน และแดชบอร์ดการเรียกเก็บเงิน แทนที่จะต้องจัดการ URL และข้อมูลรับรองของผู้ขายหลายราย
นักพัฒนาสามารถเข้าถึงได้ คล็อด ซอนเน็ต 4 API (รุ่น: claude-sonnet-4-20250514 ; claude-sonnet-4-20250514-thinking) and คล็อด โอปุส 4 เอพีไอ (รุ่น: claude-opus-4-20250514; claude-opus-4-20250514-thinking)ฯลฯ ผ่านทาง โคเมทเอพีไอ. . เริ่มต้นด้วยการสำรวจความสามารถของโมเดลใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าถึง โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว CometAPI ยังได้เพิ่ม cometapi-sonnet-4-20250514และcometapi-sonnet-4-20250514-thinking เพื่อการใช้งานในเคอร์เซอร์โดยเฉพาะ
ใหม่สำหรับ CometAPI หรือไม่? เริ่มทดลองใช้ฟรี 1$ และปลดปล่อย Sonnet 4 ออกมาเพื่อรับมือกับภารกิจที่ยากที่สุดของคุณ
เราแทบรอไม่ไหวที่จะเห็นสิ่งที่คุณสร้าง หากรู้สึกว่ามีบางอย่างผิดปกติ โปรดกดปุ่มแสดงความคิดเห็น การแจ้งให้เราทราบว่าสิ่งใดเสียหายเป็นวิธีที่เร็วที่สุดที่จะทำให้สิ่งนั้นดีขึ้น