

ในช่วงไม่กี่เดือนที่ผ่านมา ได้เห็นการพัฒนาอย่างรวดเร็วของการเขียนโค้ดแบบเอเจนต์: โมเดลเฉพาะทางที่ไม่เพียงแต่ตอบคำถามแบบครั้งเดียว แต่ยังวางแผน แก้ไข ทดสอบ และทำซ้ำในคลังข้อมูลทั้งหมด สองในผู้เข้าแข่งขันที่มีชื่อเสียงสูงสุดคือ แต่งโมเดลการเข้ารหัสแบบหน่วงเวลาต่ำที่สร้างขึ้นโดยเฉพาะซึ่งเปิดตัวโดย Cursor พร้อมกับการเปิดตัว Cursor 2.0 และ จีพีที-5-โคเด็กซ์GPT-5 เวอร์ชันที่ปรับแต่งให้เหมาะสมกับตัวแทนของ OpenAI ได้รับการปรับแต่งเพื่อเวิร์กโฟลว์การเขียนโค้ดที่ยั่งยืน ทั้งหมดนี้แสดงให้เห็นถึงข้อบกพร่องใหม่ๆ ในเครื่องมือสำหรับนักพัฒนา ได้แก่ ความเร็วเทียบกับความลึก การรับรู้พื้นที่ทำงานเฉพาะพื้นที่เทียบกับการใช้เหตุผลทั่วไป และความสะดวกในการเขียนโค้ดแบบ "Vibe-coding" เทียบกับความเข้มงวดทางวิศวกรรม
ภาพรวม: ความแตกต่างแบบตัวต่อตัว
- เจตนาการออกแบบ: GPT-5-Codex — การใช้เหตุผลเชิงลึกและแข็งแกร่งสำหรับเซสชันที่ซับซ้อนและยาวนาน Composer — การวนซ้ำที่ฉับไว คำนึงถึงพื้นที่ทำงาน ได้รับการปรับให้เหมาะสมเพื่อความเร็ว
- พื้นผิวการรวมหลัก: GPT-5-Codex — ผลิตภัณฑ์ Codex/Responses API, IDE, การผสานรวมองค์กร; Composer — ตัวแก้ไขเคอร์เซอร์และ UI มัลติเอเจนต์ของ Cursor
- ความหน่วง/การวนซ้ำ: Composer เน้นที่ความเร็วรอบต่ำกว่า 30 วินาทีและอ้างข้อได้เปรียบด้านความเร็วที่มาก GPT-5-Codex ให้ความสำคัญกับความละเอียดถี่ถ้วนและการวิ่งอัตโนมัติหลายชั่วโมงตามที่จำเป็น
ฉันทดสอบ API GPT-5-โคเด็กซ์ แบบจำลองที่ให้มาโดย โคเมทเอพีไอ (ผู้ให้บริการรวบรวม API ของบุคคลที่สาม ซึ่งราคา API มักจะถูกกว่าเจ้าที่เป็นทางการ) สรุปประสบการณ์ของฉันในการใช้โมเดล Composer ของ Cursor 2.0 และเปรียบเทียบทั้งสองในมิติต่างๆ ของการตัดสินการสร้างโค้ด
Composer และ GPT-5-Codex คืออะไร
GPT-5-Codex คืออะไร และมีจุดมุ่งหมายเพื่อแก้ไขปัญหาอะไร?
GPT-5-Codex ของ OpenAI คือภาพรวมเฉพาะของ GPT-5 ที่ OpenAI ระบุว่าได้รับการปรับให้เหมาะสมสำหรับสถานการณ์การเขียนโค้ดแบบเอเจนต์ ได้แก่ การรันการทดสอบ การแก้ไขโค้ดในระดับคลัง และการวนซ้ำแบบอัตโนมัติจนกว่าจะผ่านการตรวจสอบ จุดเน้นอยู่ที่ความสามารถที่ครอบคลุมในงานวิศวกรรมมากมาย เช่น การใช้เหตุผลเชิงลึกสำหรับการรีแฟกเตอร์ที่ซับซ้อน การดำเนินการแบบ “เอเจนต์” ในระยะยาว (ซึ่งโมเดลสามารถใช้เวลาเพียงไม่กี่นาทีถึงหลายชั่วโมงในการคิดเหตุผลและทดสอบ) และประสิทธิภาพที่ดีขึ้นบนเกณฑ์มาตรฐานมาตรฐานที่ออกแบบมาเพื่อสะท้อนปัญหาทางวิศวกรรมในโลกแห่งความเป็นจริง
Composer คืออะไร และมีจุดมุ่งหมายเพื่อแก้ไขปัญหาอะไรบ้าง?
Composer คือโมเดลการเขียนโค้ดเนทีฟตัวแรกของ Cursor ซึ่งมาพร้อมกับ Cursor 2.0 Cursor อธิบายว่า Composer เป็นโมเดลที่ล้ำสมัย เน้นเอเจนต์ สร้างขึ้นเพื่อประหยัดเวลาแฝงและการทำงานวนซ้ำที่รวดเร็วภายในเวิร์กโฟลว์ของนักพัฒนาซอฟต์แวร์ โดยประกอบด้วยการวางแผนความแตกต่างของไฟล์หลายไฟล์ การใช้การค้นหาเชิงความหมายทั่วทั้งคลังข้อมูล และการทำงานส่วนใหญ่ให้เสร็จภายในเวลาไม่ถึง 30 วินาที Composer ได้รับการฝึกฝนด้วยการเข้าถึงเครื่องมือในลูป (ค้นหา แก้ไข และทดสอบ) เพื่อให้มีประสิทธิภาพในงานวิศวกรรมเชิงปฏิบัติ และเพื่อลดความยุ่งยากจากวงจรพร้อมท์→การตอบสนองซ้ำๆ ในการเขียนโค้ดในชีวิตประจำวัน Cursor วางตำแหน่ง Composer ให้เป็นโมเดลที่ปรับให้เหมาะสมที่สุดสำหรับความเร็วของนักพัฒนาซอฟต์แวร์และลูปฟีดแบ็กแบบเรียลไทม์
ขอบเขตของโมเดลและพฤติกรรมรันไทม์
- นักแต่งเพลง: ปรับให้เหมาะสมที่สุดสำหรับการโต้ตอบที่รวดเร็วโดยเน้นที่ตัวแก้ไขและความสอดคล้องกันของไฟล์หลายไฟล์ การผสานรวมระดับแพลตฟอร์มของ Cursor ช่วยให้ Composer มองเห็นพื้นที่เก็บข้อมูลได้มากขึ้น และมีส่วนร่วมในการจัดการแบบหลายเอเจนต์ (เช่น เอเจนต์ Composer สองตัวเทียบกับเอเจนต์อื่นๆ) ซึ่ง Cursor ระบุว่าช่วยลดการพึ่งพาที่หายไประหว่างไฟล์ต่างๆ
- GPT-5-โคเด็กซ์: ได้รับการปรับให้เหมาะสมสำหรับการให้เหตุผลที่ลึกซึ้งและมีความยาวแปรผัน OpenAI โฆษณาความสามารถของโมเดลนี้ในการแลกการคำนวณ/เวลาสำหรับการให้เหตุผลที่ลึกซึ้งยิ่งขึ้นเมื่อจำเป็น — รายงานระบุว่าใช้เวลาเพียงไม่กี่วินาทีสำหรับงานเบาๆ ไปจนถึงหลายชั่วโมงสำหรับงานอัตโนมัติขนาดใหญ่ — ช่วยให้สามารถรีแฟกเตอร์และดีบักแบบทดสอบได้อย่างละเอียดมากขึ้น
เวอร์ชันสั้น: Composer = โมเดลการเขียนโค้ดที่คำนึงถึงพื้นที่ทำงานภายใน Cursor ใน IDE; GPT-5-Codex = รูปแบบ GPT-5 เฉพาะของ OpenAI สำหรับวิศวกรรมซอฟต์แวร์ ซึ่งมีให้บริการผ่าน Responses/Codex
Composer และ GPT-5-Codex เปรียบเทียบกันในเรื่องความเร็วอย่างไร
ผู้ขายอ้างว่าอะไร?
เคอร์เซอร์วางตำแหน่ง Composer ให้เป็นโค้ดเดอร์แบบ “fast frontier”: ตัวเลขที่เผยแพร่เน้นย้ำถึงทรูพุตของการสร้างที่วัดเป็นโทเค็นต่อวินาที และอ้างว่ามีเวลาดำเนินการแบบอินเทอร์แอคทีฟที่เร็วขึ้น 2–4 เท่า เมื่อเทียบกับโมเดล “frontier” ในฮาร์ดแวร์ภายในของเคอร์เซอร์ การรายงานข่าวอิสระ (สื่อมวลชนและผู้ทดสอบรุ่นแรกๆ) รายงานว่า Composer ผลิตโค้ดได้ประมาณ 200–250 โทเค็นต่อวินาทีในสภาพแวดล้อมของเคอร์เซอร์ และในหลายกรณี การเขียนโค้ดแบบอินเทอร์แอคทีฟทั่วไปเสร็จสิ้นภายในเวลาไม่ถึง 30 วินาที
GPT-5-Codex ของ OpenAI ไม่ได้ถูกวางตำแหน่งให้เป็นการทดลองความหน่วง แต่จะให้ความสำคัญกับความทนทานและการใช้เหตุผลที่ลึกซึ้งยิ่งขึ้น และเมื่อใช้ในเวิร์กโหลดการใช้เหตุผลที่สูงในระดับที่เทียบเคียงได้ อาจทำงานช้าลงเมื่อใช้ในขนาดบริบทที่ใหญ่กว่า ตามรายงานของชุมชนและเธรดปัญหา
เราประเมินประสิทธิภาพความเร็วอย่างไร (วิธีการ)
ในการเปรียบเทียบความเร็วอย่างยุติธรรม คุณต้องควบคุมประเภทของงาน (การทำงานเสร็จในระยะเวลาสั้นเทียบกับการใช้เหตุผลระยะยาว) สภาพแวดล้อม (ความหน่วงของเครือข่าย การรวมระบบภายในกับระบบคลาวด์) และวัดทั้งสองอย่าง เวลาถึงผลลัพธ์ที่เป็นประโยชน์ครั้งแรก และ นาฬิกาติดผนังแบบ end-to-end (รวมถึงขั้นตอนการดำเนินการทดสอบหรือคอมไพล์ใดๆ) ประเด็นสำคัญ:
- งานที่เลือก — การสร้างชิ้นส่วนขนาดเล็ก (การใช้งานจุดสิ้นสุด API), งานขนาดกลาง (การรีแฟกเตอร์ไฟล์หนึ่งไฟล์และอัปเดตการนำเข้า), งานขนาดใหญ่ (การใช้งานฟีเจอร์ในสามไฟล์, อัปเดตการทดสอบ)
- ตัวชี้วัด — เวลาถึงโทเค็นแรก เวลาถึงความแตกต่างที่เป็นประโยชน์ครั้งแรก (เวลาจนกว่าจะปล่อยแพตช์ผู้สมัคร) และเวลาทั้งหมดรวมถึงการดำเนินการทดสอบและการตรวจยืนยัน
- ซ้ำ — แต่ละงานรัน 10 เท่า ค่ามัธยฐานใช้เพื่อลดสัญญาณรบกวนเครือข่าย
- สภาพสิ่งแวดล้อม — การวัดจากเครื่องของนักพัฒนาในโตเกียว (เพื่อสะท้อนความหน่วงในโลกแห่งความเป็นจริง) ด้วยลิงก์ที่เสถียร 100/10 Mbps ผลลัพธ์จะแตกต่างกันไปในแต่ละภูมิภาค
ด้านล่างนี้เป็นแบบจำลองที่สามารถทำซ้ำได้ สายรัดความเร็ว สำหรับ GPT-5-Codex (Responses API) และคำอธิบายเกี่ยวกับวิธีการวัด Composer (ภายใน Cursor)
Speed Harness (Node.js) — GPT-5-Codex (Responses API):
// node speed_harness_gpt5_codex.js
// Requires: node16+, npm install node-fetch
import fetch from "node-fetch";
import { performance } from "perf_hooks";
const API_KEY = process.env.OPENAI_API_KEY; // set your key
const ENDPOINT = "https://api.openai.com/v1/responses"; // OpenAI Responses API
const MODEL = "gpt-5-codex";
async function runPrompt(prompt) {
const start = performance.now();
const body = {
model: MODEL,
input: prompt,
// small length to simulate short interactive tasks
max_output_tokens: 256,
};
const resp = await fetch(ENDPOINT, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json"
},
body: JSON.stringify(body)
});
const json = await resp.json();
const elapsed = performance.now() - start;
return { elapsed, output: json };
}
(async () => {
const prompt = "Implement a Node.js Express route POST /signup that validates email and stores user in-memory with hashed password (bcrypt). Return code only.";
const trials = 10;
for (let i=0;i<trials;i++){
const r = await runPrompt(prompt);
console.log(`trial ${i+1}: ${Math.round(r.elapsed)} ms`);
}
})();
การวัดนี้จะวัดเวลาแฝงของคำขอแบบครบวงจรสำหรับ GPT-5-Codex โดยใช้ Responses API สาธารณะ (เอกสาร OpenAI อธิบายการใช้งาน Responses API และโมเดล gpt-5-codex)
วิธีการวัดความเร็วของ Composer (เคอร์เซอร์):
Composer ทำงานภายใน Cursor 2.0 (แยกฝั่งเดสก์ท็อป/VS Code) Cursor (ณ ขณะที่เขียน) ไม่ได้จัดเตรียม HTTP API ภายนอกทั่วไปสำหรับ Composer ที่ตรงกับ Responses API ของ OpenAI จุดแข็งของ Composer คือ การรวมพื้นที่ทำงานแบบมีสถานะใน IDEดังนั้น ให้วัด Composer เหมือนกับนักพัฒนาที่เป็นมนุษย์:
- เปิดโครงการเดียวกันภายใน Cursor 2.0
- ใช้ Composer เพื่อรันพรอมต์แบบเดียวกับงานของตัวแทน (สร้างเส้นทาง รีแฟกเตอร์ เปลี่ยนแปลงไฟล์หลายไฟล์)
- เริ่มจับเวลาเมื่อคุณส่งแผน Composer หยุดเมื่อ Composer ปล่อย diff แบบอะตอมและรันชุดการทดสอบ (อินเทอร์เฟซของเคอร์เซอร์สามารถรันการทดสอบและแสดง diff แบบรวมได้)
- ทำซ้ำ 10 เท่า และใช้ค่ามัธยฐาน
เอกสารเผยแพร่และบทวิจารณ์เชิงปฏิบัติของ Cursor แสดงให้เห็นว่า Composer สามารถทำภารกิจทั่วไปหลายๆ อย่างเสร็จได้ภายในเวลาไม่ถึง 30 วินาทีในทางปฏิบัติ นี่เป็นเป้าหมายความล่าช้าแบบโต้ตอบมากกว่าเวลาในการอนุมานโมเดลแบบดิบๆ
Takeaway: เป้าหมายในการออกแบบของ Composer คือการแก้ไขแบบโต้ตอบอย่างรวดเร็วภายในโปรแกรมแก้ไข หากคุณให้ความสำคัญกับลูปการเขียนโค้ดแบบสนทนาที่มีเวลาแฝงต่ำ Composer ก็ถูกสร้างขึ้นมาเพื่อกรณีการใช้งานนั้น GPT-5-Codex ได้รับการปรับให้เหมาะสมเพื่อความถูกต้องและการใช้เหตุผลแบบเอเจนต์ในเซสชันที่ยาวนานขึ้น ซึ่งสามารถแลกเวลาแฝงที่มากขึ้นเล็กน้อยเพื่อการวางแผนที่ลึกซึ้งยิ่งขึ้น หมายเลขผู้ขายสนับสนุนตำแหน่งนี้
Composer และ GPT-5-Codex เปรียบเทียบกันในเรื่องความแม่นยำอย่างไร
ความแม่นยำหมายถึงอะไรในการเขียนโค้ด AI
ความแม่นยำที่นี่มีหลายแง่มุม: ความถูกต้องของฟังก์ชัน (โค้ดคอมไพล์และผ่านการทดสอบหรือไม่) ความถูกต้องทางความหมาย (พฤติกรรมตรงตามสเปคหรือไม่) และ ความแข็งแรง (จัดการกับกรณีขอบและข้อกังวลด้านความปลอดภัย)
หมายเลขผู้ขายและหมายเลขกด
OpenAI รายงานประสิทธิภาพอันแข็งแกร่งของ GPT-5-Codex บนชุดข้อมูลที่ผ่านการตรวจสอบ SWE-bench และเน้นย้ำถึง อัตราความสำเร็จ 74.5% จากเกณฑ์มาตรฐานการเขียนโค้ดในโลกแห่งความเป็นจริง (รายงานในรายงานข่าว) และการเพิ่มขึ้นอย่างเห็นได้ชัดในความสำเร็จในการรีแฟกเตอร์ (51.3% เทียบกับ 33.9 สำหรับ GPT-5 พื้นฐานในการทดสอบรีแฟกเตอร์ภายใน)
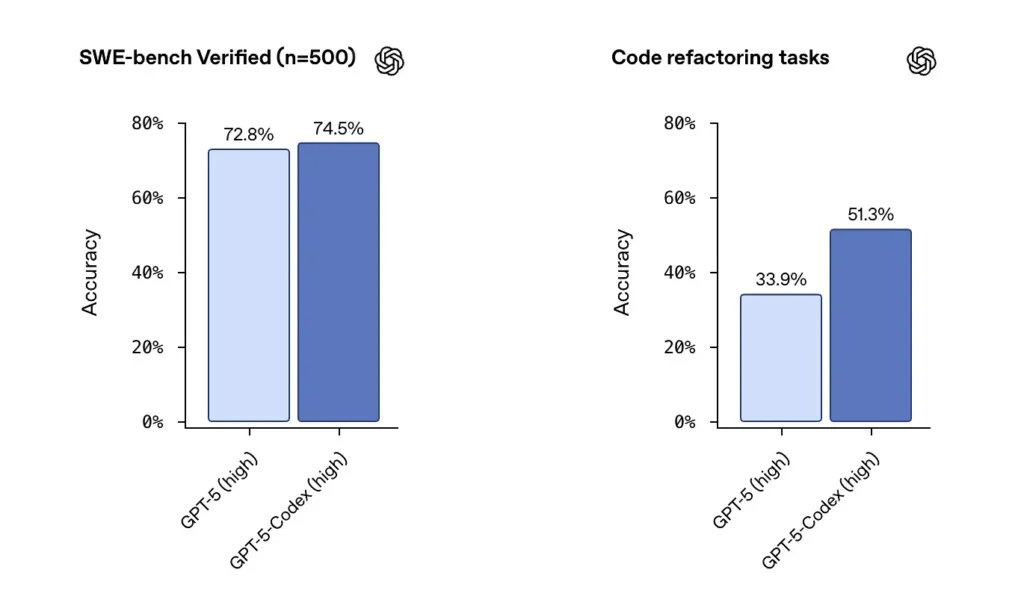
การเปิดตัว Cursor บ่งชี้ว่า Composer มักจะโดดเด่นในการแก้ไขแบบหลายไฟล์ที่คำนึงถึงบริบท ซึ่งการผสานรวมตัวแก้ไขและการมองเห็น repo เป็นสิ่งสำคัญ หลังจากการทดสอบของฉัน ฉันได้รายงานว่า Composer สร้างข้อผิดพลาดการอ้างอิงที่หายไปน้อยลงในระหว่างการรีแฟกเตอร์หลายไฟล์ และได้คะแนนสูงขึ้นในการทดสอบแบบปิดสำหรับเวิร์กโหลดหลายไฟล์บางรายการ ฟีเจอร์ความหน่วงและตัวแทนแบบขนานของ Composer ยังช่วยฉันปรับปรุงความเร็วในการวนซ้ำอีกด้วย
การทดสอบความแม่นยำแบบอิสระ (วิธีที่แนะนำ)
การทดสอบที่ยุติธรรมใช้การผสมผสานของ:
- การทดสอบหน่วย: ป้อน repo และชุดทดสอบเดียวกันให้กับทั้งสองโมเดล สร้างโค้ด และรันการทดสอบ
- การทดสอบรีแฟกเตอร์: ให้ฟังก์ชันที่ยุ่งวุ่นวายโดยตั้งใจและขอให้โมเดลรีแฟกเตอร์และเพิ่มการทดสอบ
- การตรวจสอบความปลอดภัย: รันการวิเคราะห์แบบคงที่และเครื่องมือ SAST บนโค้ดที่สร้างขึ้น (เช่น Bandit, ESLint, semgrep)
- การตรวจสอบโดยมนุษย์:คะแนนการตรวจสอบโค้ดโดยวิศวกรที่มีประสบการณ์เพื่อความสามารถในการบำรุงรักษาและแนวทางปฏิบัติที่ดีที่สุด
ตัวอย่าง: สายรัดทดสอบอัตโนมัติ (Python) — รันโค้ดที่สร้างขึ้นและทดสอบยูนิต
# python3 run_generated_code.py
# This is a simplified harness: it writes model output to file, runs pytest, captures results.
import subprocess, tempfile, os, textwrap
def write_file(path, content):
with open(path, "w") as f:
f.write(content)
# Suppose `generated_code` is the string returned from model
generated_code = """
# sample module
def add(a,b):
return a + b
"""
tests = """
# test_sample.py
from sample import add
def test_add():
assert add(2,3) == 5
"""
with tempfile.TemporaryDirectory() as d:
write_file(os.path.join(d, "sample.py"), generated_code)
write_file(os.path.join(d, "test_sample.py"), tests)
r = subprocess.run(, cwd=d, capture_output=True, text=True, timeout=30)
print("pytest returncode:", r.returncode)
print(r.stdout)
print(r.stderr)
ใช้รูปแบบนี้เพื่อยืนยันโดยอัตโนมัติว่าผลลัพธ์ของโมเดลถูกต้องตามฟังก์ชันหรือไม่ (ผ่านการทดสอบ) สำหรับงานรีแฟกเตอร์ ให้รัน Harness เทียบกับที่เก็บต้นฉบับบวกกับค่า diff ของโมเดล แล้วเปรียบเทียบอัตราการผ่านการทดสอบและการเปลี่ยนแปลงการครอบคลุม
Takeaway: ในชุดเกณฑ์มาตรฐานแบบดิบ GPT-5-Codex รายงานตัวเลขที่ยอดเยี่ยมและความสามารถในการรีแฟกเตอร์ที่แข็งแกร่ง ในเวิร์กโฟลว์การซ่อมแซมและแก้ไขไฟล์หลายไฟล์ในโลกแห่งความเป็นจริง การรับรู้พื้นที่ทำงานของ Composer สามารถสร้างการยอมรับในทางปฏิบัติที่สูงขึ้นและข้อผิดพลาด "เชิงกลไก" ที่น้อยลง (การนำเข้าที่หายไป ชื่อไฟล์ที่ไม่ถูกต้อง) สำหรับความถูกต้องของฟังก์ชันสูงสุดในงานอัลกอริทึมไฟล์เดียว GPT-5-Codex เป็นตัวเลือกที่แข็งแกร่ง สำหรับการเปลี่ยนแปลงที่ไวต่อข้อตกลงหลายไฟล์ภายใน IDE Composer มักจะโดดเด่น
Composer เทียบกับ GPT-5: ทั้งสองตัวนี้เปรียบเทียบกันในเรื่องคุณภาพของโค้ดได้อย่างไร?
อะไรคือสิ่งที่นับเป็นคุณภาพ?
คุณภาพประกอบด้วยความสามารถในการอ่าน การตั้งชื่อ การจัดทำเอกสาร ความครอบคลุมของการทดสอบ การใช้รูปแบบสำนวน และความปลอดภัย มีการวัดทั้งแบบอัตโนมัติ (ลินเตอร์ เมตริกความซับซ้อน) และแบบเชิงคุณภาพ (การตรวจสอบโดยมนุษย์)
ความแตกต่างที่สังเกตได้
- จีพีที-5-โคเด็กซ์: แข็งแกร่งในการสร้างรูปแบบสำนวนเมื่อถูกถามอย่างชัดเจน โดดเด่นในด้านความชัดเจนของอัลกอริทึม และสามารถสร้างชุดการทดสอบที่ครอบคลุมเมื่อถูกถาม เครื่องมือ Codex ของ OpenAI ประกอบด้วยการทดสอบ/การรายงานแบบบูรณาการ และบันทึกการดำเนินการ
- แต่ง: ได้รับการปรับให้เหมาะสมเพื่อสังเกตรูปแบบและข้อตกลงของ repo โดยอัตโนมัติ Composer สามารถติดตามรูปแบบโครงการที่มีอยู่และประสานการอัปเดตไปยังไฟล์หลายไฟล์ (การเปลี่ยนชื่อ/รีแฟกเตอร์การเผยแพร่ การนำเข้าการอัปเดต) มอบความสามารถในการบำรุงรักษาตามความต้องการที่ยอดเยี่ยมสำหรับโครงการขนาดใหญ่
ตัวอย่างการตรวจสอบคุณภาพโค้ดที่คุณสามารถรันได้
- ลินเตอร์ — ESLint / ไพลินท์
- ความซับซ้อน — เรดอน / ความซับซ้อนของเกล็ด 8
- ความปลอดภัย — semgrep / Bandit
- ความคุ้มครองการทดสอบ — รัน coverage.py หรือ vitest/nyc สำหรับ JS
ทำการตรวจสอบเหล่านี้โดยอัตโนมัติหลังจากใช้แพตช์ของโมเดลเพื่อประเมินการปรับปรุงหรือการถดถอย ตัวอย่างลำดับคำสั่ง (ที่เก็บ JS):
# after applying model patch
npm ci
npm test
npx eslint src/
npx semgrep --config=auto .
การตรวจสอบโดยมนุษย์และแนวทางปฏิบัติที่ดีที่สุด
ในทางปฏิบัติ โมเดลจำเป็นต้องมีคำสั่งเพื่อปฏิบัติตามแนวปฏิบัติที่ดีที่สุด เช่น ขอ docstring, คำอธิบายประกอบประเภท, การตรึง dependency pinning หรือรูปแบบเฉพาะ (เช่น async/await) GPT-5-Codex จะยอดเยี่ยมมากเมื่อมีคำสั่งที่ชัดเจน Composer จะได้รับประโยชน์จากบริบทของ repository ที่เป็นนัย ใช้วิธีผสมผสาน: สั่งโมเดลอย่างชัดเจนและให้ Composer บังคับใช้สไตล์โครงการหากคุณอยู่ใน Cursor
คำแนะนำ: สำหรับงานวิศวกรรมหลายไฟล์ภายใน IDE ควรใช้ Composer ส่วนสำหรับงานภายนอก งานวิจัย หรือการทำงานอัตโนมัติของเครื่องมือที่คุณสามารถเรียกใช้ API และจัดเตรียมบริบทขนาดใหญ่ได้ GPT-5-Codex ถือเป็นตัวเลือกที่แข็งแกร่ง
ตัวเลือกการรวมและการปรับใช้
Composer เป็นส่วนหนึ่งของ Cursor 2.0 ซึ่งฝังอยู่ในตัวแก้ไข Cursor และ UI วิธีการของ Cursor เน้นที่ control plane ของผู้ผลิตรายเดียวที่รัน Composer ควบคู่ไปกับโมเดลอื่นๆ ช่วยให้ผู้ใช้รันอินสแตนซ์โมเดลหลายตัวบนพรอมต์เดียวกัน และเปรียบเทียบผลลัพธ์ภายในตัวแก้ไขได้ ()
GPT-5-Codex กำลังถูกผนวกรวมเข้ากับข้อเสนอ Codex และผลิตภัณฑ์กลุ่ม ChatGPT ของ OpenAI โดยพร้อมให้บริการผ่าน ChatGPT แบบชำระเงินและ API ซึ่งแพลตฟอร์มบุคคลที่สาม เช่น CometAPI มอบความคุ้มค่ามากกว่า นอกจากนี้ OpenAI ยังผสานรวม Codex เข้ากับเครื่องมือสำหรับนักพัฒนาและเวิร์กโฟลว์ของพันธมิตรคลาวด์ (เช่น การผสานรวม Visual Studio Code/GitHub Copilot)
Composer และ GPT-5-Codex อาจผลักดันอุตสาหกรรมต่อไปได้อย่างไร
ผลกระทบระยะสั้น
- รอบการวนซ้ำที่เร็วขึ้น: โมเดลที่ฝังตัวแก้ไขเช่น Composer ช่วยลดความยุ่งยากในการแก้ไขเล็กๆ น้อยๆ และการสร้าง PR
- ความคาดหวังที่เพิ่มขึ้นสำหรับการตรวจสอบ: การที่ Codex ให้ความสำคัญกับการทดสอบ บันทึก และความสามารถในการทำงานอัตโนมัติ จะผลักดันให้ผู้จำหน่ายจัดหาการตรวจสอบแบบพร้อมใช้งานที่เข้มงวดยิ่งขึ้นสำหรับโค้ดที่ผลิตเป็นโมเดล
ระยะกลางถึงระยะยาว
- การประสานกันหลายโมเดลกลายเป็นเรื่องปกติ: GUI หลายเอเจนต์ของ Cursor เป็นคำแนะนำเบื้องต้นที่วิศวกรคาดว่าจะรันเอเจนต์เฉพาะทางหลายตัวพร้อมกันในเร็วๆ นี้ (การลินต์ การรักษาความปลอดภัย การรีแฟกเตอร์ การเพิ่มประสิทธิภาพการทำงาน) และยอมรับเอาต์พุตที่ดีที่สุด
- วงจรข้อเสนอแนะ CI/AI ที่เข้มงวดยิ่งขึ้น: เมื่อมีการปรับปรุงโมเดลให้ดีขึ้น กระบวนการ CI จะมีการนำการสร้างการทดสอบที่ขับเคลื่อนด้วยโมเดลและข้อเสนอแนะการซ่อมแซมอัตโนมัติมาใช้เพิ่มมากขึ้น แต่การตรวจสอบโดยมนุษย์และการเปิดตัวแบบเป็นขั้นตอนยังคงมีความสำคัญ
สรุป
Composer และ GPT-5-Codex ไม่ใช่อาวุธชนิดเดียวกันในการแข่งขันด้านอาวุธเดียวกัน แต่เป็นเครื่องมือเสริมที่ปรับให้เหมาะสมสำหรับส่วนต่างๆ ของวงจรชีวิตซอฟต์แวร์ คุณค่าของ Composer คือความเร็ว: การวนซ้ำที่รวดเร็วและอิงกับพื้นที่ทำงาน ช่วยให้นักพัฒนาซอฟต์แวร์ทำงานได้อย่างราบรื่น คุณค่าของ GPT-5-Codex คือความลึกซึ้ง: ความคงอยู่ของเอเจนต์ ความถูกต้องที่ขับเคลื่อนด้วยการทดสอบ และความสามารถในการตรวจสอบสำหรับการแปลงข้อมูลขนาดใหญ่ กลยุทธ์ทางวิศวกรรมเชิงปฏิบัติคือ ประสานทั้งสอง:เอเจนต์แบบ Composer วงจรสั้นสำหรับโฟลว์การใช้งานในชีวิตประจำวัน และเอเจนต์แบบ GPT-5-Codex สำหรับการทำงานแบบเกตเวย์ที่มีความมั่นใจสูง เกณฑ์มาตรฐานเบื้องต้นชี้ให้เห็นว่าทั้งสองอย่างนี้จะเป็นส่วนหนึ่งในชุดเครื่องมือสำหรับนักพัฒนาในระยะใกล้ แทนที่จะมาแทนที่กัน
ไม่มีผู้ชนะเป้าหมายเดียวในทุกมิติ โมเดลเหล่านี้แลกเปลี่ยนจุดแข็ง:
- GPT-5-โคเด็กซ์: แข็งแกร่งยิ่งขึ้นในด้านเกณฑ์มาตรฐานความถูกต้องเชิงลึก การใช้เหตุผลในขอบเขตกว้าง และเวิร์กโฟลว์แบบอัตโนมัติที่ใช้เวลานานหลายชั่วโมง โดดเด่นเมื่อความซับซ้อนของงานต้องใช้การใช้เหตุผลที่ยาวนานหรือการตรวจสอบอย่างละเอียด
- นักแต่งเพลง: แข็งแกร่งยิ่งขึ้นในกรณีการใช้งานที่ผสานรวมกับโปรแกรมแก้ไขที่รัดกุม ความสอดคล้องของบริบทหลายไฟล์ และความเร็วในการวนซ้ำที่รวดเร็วภายในสภาพแวดล้อมของ Cursor เหมาะอย่างยิ่งสำหรับประสิทธิภาพการทำงานของนักพัฒนาในแต่ละวันที่ต้องการการแก้ไขที่คำนึงถึงบริบทอย่างแม่นยำและทันที
ดูสิ่งนี้ด้วย Cursor 2.0 และ Composer: วิธีที่ตัวแทนหลายตัวคิดใหม่เกี่ยวกับการเขียนโค้ด AI ที่น่าประหลาดใจ
เริ่มต้นใช้งาน
CometAPI เป็นแพลตฟอร์ม API แบบรวมที่รวบรวมโมเดล AI มากกว่า 500 โมเดลจากผู้ให้บริการชั้นนำ เช่น ซีรีส์ GPT ของ OpenAI, Gemini ของ Google, Claude ของ Anthropic, Midjourney, Suno และอื่นๆ ไว้ในอินเทอร์เฟซเดียวที่เป็นมิตรกับนักพัฒนา ด้วยการนำเสนอการตรวจสอบสิทธิ์ การจัดรูปแบบคำขอ และการจัดการการตอบสนองที่สอดคล้องกัน CometAPI จึงทำให้การรวมความสามารถของ AI เข้ากับแอปพลิเคชันของคุณง่ายขึ้นอย่างมาก ไม่ว่าคุณจะกำลังสร้างแชทบ็อต เครื่องกำเนิดภาพ นักแต่งเพลง หรือไพพ์ไลน์การวิเคราะห์ที่ขับเคลื่อนด้วยข้อมูล CometAPI ช่วยให้คุณทำซ้ำได้เร็วขึ้น ควบคุมต้นทุน และไม่ขึ้นอยู่กับผู้จำหน่าย ทั้งหมดนี้ในขณะที่ใช้ประโยชน์จากความก้าวหน้าล่าสุดในระบบนิเวศ AI
นักพัฒนาสามารถเข้าถึงได้ API GPT-5-โคเด็กซ์ผ่านทาง CometAPI รุ่นใหม่ล่าสุด ได้รับการอัปเดตอยู่เสมอจากเว็บไซต์อย่างเป็นทางการ เริ่มต้นด้วยการสำรวจความสามารถของโมเดลใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว โคเมทเอพีไอ เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยคุณบูรณาการ
พร้อมไปหรือยัง?→ ลงทะเบียน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม โปรดติดตามเราที่ VK, X และ ไม่ลงรอยกัน!