

Google และหน่วยวิจัยของบริษัท DeepMind ได้ผลักดันก้าวสำคัญอีกขั้นในโรดแมปของ Gemini แบบเงียบๆ (ก่อนจะไม่เงียบเท่าไร) นั่นคือ Gemini 3.1 Pro การเปิดตัวซึ่งทยอยปล่อยใช้งานผ่านอินเทอร์เฟซที่ผู้ใช้เข้าถึงได้และ CometAPI ถูกวางตำแหน่งให้เป็นการอัปเกรดด้านสมรรถนะและการให้เหตุผลของตระกูล Gemini 3 — โดยสัญญาถึงศักยภาพการให้เหตุผลแบบงานยาวที่แข็งแกร่งขึ้น ความเข้าใจแบบมัลติโมดัลที่ดีขึ้น และการสเกลเพื่อการใช้งานจริงที่ดีกว่าเดิม
โมเดลใหม่ล่าสุดของ Google — Gemini 3.1 Pro คืออะไร?
Gemini 3.1 Pro เป็นอัปเดตแบบเพิ่มพูนรุ่นแรกในตระกูล Gemini 3 ซึ่งถูกวางให้เป็นโมเดลให้เหตุผลที่ “ความสามารถสูงสุด” ที่ปรับแต่งเพื่อภารกิจหลายขั้นตอน มัลติโมดัล และลักษณะเชิงเอเจนต์ เปิดให้พรีวิวสาธารณะช่วงกลางกุมภาพันธ์ 2026 (ประกาศพรีวิว 19–20 ก.พ. 2026) โมเดลนี้มุ่งเป้าชัดเจนไปที่ฉากการใช้งานที่ต้องการโซ่การคิดต่อเนื่อง การใช้เครื่องมือ และความเข้าใจในบริบทยาว — เช่น การสังเคราะห์งานวิจัยขนาดใหญ่ เอเจนต์สำหรับงานวิศวกรรมที่ประสานเครื่องมือและระบบ และการวิเคราะห์มัลติโมดัลของเอกสารที่ผสมข้อความ ภาพ เสียง และวิดีโอ
ในภาพรวม นักพัฒนาระบุ Gemini 3.1 Pro ไว้ว่า:
- เป็นโมเดลแบบ มัลติโมดัล โดยกำเนิด — รับและให้เหตุผลบนข้อความ ภาพ เสียง และวิดีโอได้
- สร้างมาเพื่อ บริบทยาว — รองรับหน้าต่างบริบทขนาดใหญ่มาก เหมาะกับโค้ดเบสทั้งชุด แฟ้มข้อมูลหลายเอกสาร หรือทรานสคริปต์ยาว
- ปรับแต่งเพื่อ การให้เหตุผลที่เชื่อถือได้และเวิร์กโฟลว์เชิงเอเจนต์ หมายถึงถูกจูนให้วางแผน เรียกใช้เครื่องมือ และตรวจทานผลลัพธ์ในงานหลายขั้นตอน
เหตุใดจึงสำคัญตอนนี้: องค์กรและนักพัฒนากำลังก้าวจาก “ผู้ช่วยสนทนาที่ดี” ไปสู่ “เอเจนต์เพื่อสนับสนุนการตัดสินใจและงานวิจัยที่เดิมพันสูง” (การร่างเอกสารทางกฎหมาย การสังเคราะห์ R&D ความเข้าใจเอกสารแบบมัลติโมดัล) Gemini 3.1 Pro ถูกออกแบบมาเพื่อทางเดินนั้นโดยตรง — ลดการเพ้อเจ้อ สร้างการให้เหตุผลที่ตรวจสอบย้อนกลับได้ และผสานกับ CometAPI ทั้งเพื่อการต้นแบบและการผลิต
ไฮไลต์เชิงเทคนิคและคุณสมบัติของ Gemini 3.1 Pro มีอะไรบ้าง?
มัลติโมดัลโดยกำเนิดและหน้าต่างบริบทระดับสุดขั้ว
Gemini 3.1 Pro สานต่อโฟกัสด้านมัลติโมดัลของสายพันธุ์ Gemini ตามบัตรโมเดลและบันทึกผลิตภัณฑ์ โมเดลรองรับและให้เหตุผลบนข้อความ ภาพ เสียง และวิดีโอในไปป์ไลน์เดียว — ความสามารถที่ทำให้งานที่ข้อมูลหลากหลายชนิดง่ายขึ้น (เช่น ถ้อยคำให้การทางกฎหมายที่มีทั้งออดิโอ + ทรานสคริปต์ + สแกน) ที่โดดเด่นคือ โมเดลรองรับหน้าต่างบริบท 1,000,000 โทเค็น และสามารถสร้างผลลัพธ์ยาว (บันทึกเผยแพร่ระบุขีดจำกัดเอาต์พุตที่มีขนาดใหญ่มาก เหมาะกับงานเนื้อหายาว) สเกลนี้ทำให้เหมาะกับเคสอย่างการวิเคราะห์ทั้งรีโพซิทอรีโค้ด เอกสารหลายบท หรือทรานสคริปต์ยาว โดยไม่ต้องแบ่งชิ้น
“Dynamic thinking”: การให้เหตุผลและการวางแผนแบบเป็นขั้นตอนที่ดีขึ้น
Google อธิบาย 3.1 Pro ว่ามี “การคิด” ที่ดีขึ้น — กล่าวคือ จัดการห่วงโซ่การคิดภายในและเลือกกลยุทธ์การให้เหตุผลแบบไดนามิกตามความยากของงาน โมเดลถูกจูนให้เปิดใช้การวางแผนหลายขั้นตอนอย่างชัดแจ้งเมื่อจำเป็น และประหยัดโทเค็นระหว่างดำเนินการจริง ซึ่งในทางปฏิบัติแปลเป็นการเพ้อเจ้อน้อยลงในปัญหาที่ต้องแก้แบบทีละขั้น และความสอดคล้องเชิงข้อเท็จจริงที่ดีขึ้นบนชุดทดสอบการให้เหตุผลหลายขั้นตอน
เวิร์กโฟลว์เชิงเอเจนต์และการใช้เครื่องมือ
จุดเน้นการออกแบบหลักของ 3.1 Pro คือสมรรถนะเชิงเอเจนต์: ประสานเครื่องมือ เรียกใช้การยึดโยงกับเว็บหรือการค้นหา เขียนและรันโค้ดสั้นๆ และตรวจทานผลลัพธ์ผ่านการผ่านซ้ำ Google ได้ผสาน 3.1 Pro เข้ากับผลิตภัณฑ์ที่ยึดเอเจนต์เป็นศูนย์กลาง (เช่น สภาพแวดล้อมการพัฒนา Antigravity) เพื่อให้โมเดลรันงานที่เกี่ยวข้องกับเอดิเตอร์ เทอร์มินัล และเบราว์เซอร์ — และบันทึกอาร์ติแฟกต์อย่างสกรีนช็อตและการบันทึกเบราว์เซอร์เพื่อยืนยันความคืบหน้า ฟีเจอร์เหล่านี้มีเป้าหมายเพื่อลดช่องว่างระหว่างโมเดลที่ “ให้คำแนะนำ” กับโมเดลที่ปฏิบัติงานเวิร์กโฟลว์หลายเครื่องมือได้อย่างน่าเชื่อถือจริง
ซับโหมดเฉพาะทาง (Deep Research, Deep Think)
Google จับคู่ 3.1 Pro กับ “Deep Research” และอ้างถึง “Deep Think” ที่จะตามมา ซับโหมดเหล่านี้มุ่งไปที่ — ตามลำดับ — งานวิจัยที่ต้องการการครอบคลุมสูง และความลึกเชิงการให้เหตุผลสูงสุด (แลกกับค่าใช้จ่ายคอมพิวต์และการหน่วงเวลาที่เพิ่มขึ้น) พวกมันถูกออกแบบมาเพื่อผู้วิเคราะห์ นักวิจัย และนักพัฒนาที่ต้องการผลลัพธ์ที่รอบคอบ คุณภาพสูง มากกว่าคำตอบที่เร็วและถูกที่สุด
Gemini 3.1 Pro ทำผลงานบนเบนช์มาร์กอย่างไร?
Gemini 3.1 Pro ทำคะแนนดีขึ้นมากเมื่อเทียบกับผลของ Gemini 3 Pro รุ่นก่อนหน้า โดยมักขึ้นนำในชุดการวัดผลด้านการให้เหตุผลหลายขั้นตอนและมัลติโมดัลกว้างๆ — แต่ยังตามหลังคู่แข่งบางรายในภารกิจเฉพาะทางบางอย่าง (โดยเฉพาะงานโค้ดดิ้งขั้นสูงบางประเภทหรือชุดคำถามระดับผู้เชี่ยวชาญ) สรุปคือ: มีพัฒนาการกว้าง แต่ยังมีช่องที่คู่แข่งเฉือนนำ ในเบนช์มาร์กเฉพาะสาย
ตัวเลขเด่นและคำอ้างอิงเบนช์มาร์กสำคัญ
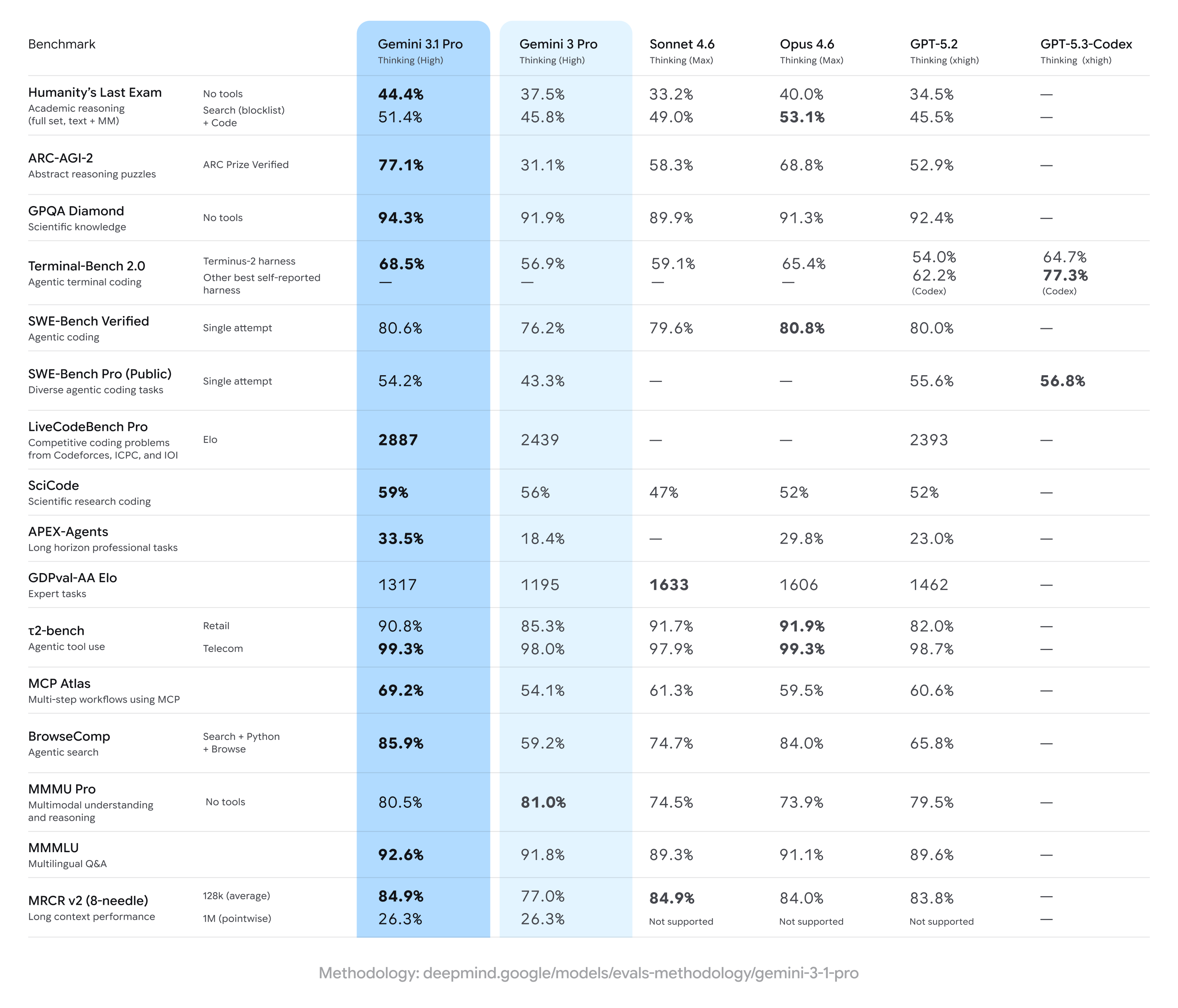
- ARC-AGI-2 (การให้เหตุผลเชิงนามธรรม/ปริศนาวิทยาศาสตร์หลายขั้นตอน): รายงานสำหรับ Gemini 3.1 Pro แสดง การปรับปรุงอย่างมาก จาก Gemini 3 Pro รุ่นก่อน ชุดทดสอบของคอมมูนิตีหนึ่งระบุว่าดีขึ้นมากกว่าสองเท่าเมื่อเทียบกับเบสไลน์ Gemini 3 Pro เดิมในแบบทดสอบสั้นและเน้นเฉพาะ รายงานตัวเลขบางส่วน (จากคอมมูนิตี) วาง Gemini 3.1 Pro ไว้ที่ราว ~77.1% บนการรวมแบบสไตล์ ARC บางรายการ (การรายงานสาธารณะ)
- GPQA Diamond และเบนช์มาร์กระดับบัณฑิตด้านวิทยาศาสตร์: ข้อมูลระบุว่า Gemini 3.1 Pro ทำสถิติสูงใหม่บน GPQA Diamond แซงหน้ารุ่น Gemini ก่อนๆ และสร้างหมุดหมายใหม่ให้ตระกูลนี้ในการรันทดสอบอิสระ สะท้อนการจูนห่วงโซ่การคิดและการให้เหตุผลทีละขั้นที่ดีขึ้น
- “Humanity’s Last Exam” เมื่อเปิดใช้เครื่องมือ (หลายเครื่องมือ ยึดโยงข้อมูล): ในการเทียบกับ Claude Opus 4.6 ของ Anthropic แบบตัวต่อตัว Claude ทำได้ 53.1% ขณะที่ Gemini 3.1 Pro ได้ 51.4% ในรอบทดสอบเดียวกัน — แสดงว่า Gemini ไล่หลังมาติดๆ แต่ยังไม่ขึ้นนำในการสอบแบบหลายเครื่องมือนี้
- เบนช์มาร์กโค้ดดิ้งและเทอร์มินัล (Terminal-Bench 2.0, SWE-Bench Pro): เบนช์มาร์กโค้ดดิ้งเฉพาะทางมีความต่างมากขึ้น บน Terminal-Bench 2.0 กับฮาร์เนสเฉพาะ GPT-5.3-Codex ทำได้ราว 77.3% เทียบกับ Gemini 3.1 Pro ที่ราว ~68.5% ในการทดสอบเดียวกัน บน SWE-Bench Pro ตามผลที่รายงานสาธารณะ Gemini 3.1 Pro ทำได้ราว 54.2% เทียบกับ GPT-5.3-Codex ที่ 56.8% — ใกล้กันขึ้น แต่ตระกูล Codex ของ OpenAI ยังมีแต้มต่อบนงานโปรแกรมมิงเฉพาะทางในรอบนั้น
- GDPval-AA Elo (การจัดอันดับงานผู้เชี่ยวชาญแบบ Elo): ในการจัดอันดับแบบ Elo รวมสำหรับงานผู้เชี่ยวชาญ รุ่น Claude Sonnet/Opus ได้คะแนนสูงกว่า (เช่น ~1606–1633 คะแนน) ขณะที่รายงานหนึ่งวาง Gemini 3.1 Pro ไว้ที่ ~1317 คะแนนในดาต้าเซ็ตเดียวกัน — บ่งชี้ว่ายังมีพื้นที่ให้พัฒนาในโดเมนผู้เชี่ยวชาญบางแคบ
ผลลัพธ์จากการลองใช้งานจริงและทดสอบด้วยตนเอง
บันทึกจากนักวิเคราะห์ที่ลองใช้งานชี้ว่า Gemini 3.1 Pro เด่นเป็นพิเศษใน:
- การสรุปบริบทยาว และการสังเคราะห์ข้ามหลายเอกสาร ซึ่งหน้าต่าง 1M โทเค็นช่วยหลีกเลี่ยงอาร์ติแฟกต์จากการแบ่งชิ้น
- งานทำความเข้าใจแบบมัลติโมดัล ที่การยึดโยงระหว่างภาพ + ข้อความช่วยปรับปรุงการดึงข้อเท็จจริง
- ระบบอัตโนมัติแบบเอเจนต์ (เช่น ประสานชุดเครื่องมืออย่างง่าย) — โดยการลองผ่าน Antigravity แสดงว่าการจัดวงจรงานแบบหลายเอเจนต์ทำได้จริง พร้อมอาร์ติแฟกต์บันทึกแต่ละขั้น
จุดที่ Gemini 3.1 Pro ยังตามหลัง (ตามตัวเลข)
ไม่มีโมเดลใดดีที่สุดในทุกเรื่อง ความเห็นอิสระและการทดสอบโดยคอมมูนิตีชี้ช่องโหว่เฉพาะ:
- เบนช์มาร์กวิศวกรรมซอฟต์แวร์และบำรุงรักษาโค้ด (SWE-Bench Pro และคล้ายกัน) — Gemini 3.1 Pro ตามหลังคู่แข่ง (Claude Opus 4.6 ของ Anthropic) ในงานที่ทดสอบทักษะวิศวกรรมซอฟต์แวร์จริง: รีแฟกเตอร์ขนาดใหญ่ การคัดแยกบั๊กในโค้ดเบสที่รก และการซ่อมโปรแกรมอัตโนมัติบางแบบ กล่าวคือ สำหรับงานบำรุงรักษาประจำวัน โมเดลเฉพาะทางยังคงได้เปรียบบนบางชุดทดสอบ
- ไมโครทาสก์ที่ไวต่อความหน่วง — เพราะ 3.1 Pro ถูกจูนเพื่อความลึก งานที่ต้องการความหน่วงต่ำมากและทะลุผ่านสูง (เช่น อินเฟอเรนซ์งานเบาสำหรับ UI สนทนา) อาจเหมาะกับรุ่น “Flash” หรือรุ่นปรับแต่งอื่นในตระกูล Gemini มากกว่า
ราคา Gemini 3.1 Pro เป็นอย่างไร?
คุณสามารถเข้าถึง Gemini 3.1 Pro ได้สองวิธี — สมัครใช้สำหรับผู้บริโภค หรือผ่าน Developer API — โดยราคาแตกต่างกัน
- ผู้ใช้ทั่วไป (แอป Gemini / Google AI Pro): การเข้าถึง Gemini 3.1 Pro รวมอยู่ในสมาชิก Google AI Pro ซึ่งในสหรัฐฯ คือ $19.99 / เดือน (Google ยังมีระดับ “AI Plus” ที่ถูกกว่า และ “AI Ultra” ที่สูงกว่า) Google.
- นักพัฒนา / API (คิดตามโทเค็น): หากคุณเรียกใช้โมเดล Gemini ผ่าน Gemini/AI developer API จะคิดราคาตามโทเค็น สำหรับพรีวิว Gemini 3.x Pro ราคาโดยสรุปคือ: $2.00 ต่อ 1M โทเค็นอินพุต และ $12.00 ต่อ 1M โทเค็นเอาต์พุต สำหรับแบนด์มาตรฐาน (≤200k prompts) — โดยมีระดับสูงกว่า (เช่น $4/$18 ต่อ 1M) สำหรับคอนเท็กซ์ที่ใหญ่มาก (ดูตารางราคา Gemini API สำหรับรายละเอียดเต็มและราคาแบบแบตช์)
- หากคุณใช้ Gemini 3.1 Pro ผ่าน CometAPI:
| ราคา Comet (USD / M Tokens) | ราคาอย่างเป็นทางการ (USD / M Tokens) |
|---|---|
| อินพุต:$1.6/M; เอาต์พุต:$9.6/M | อินพุต:$2/M; เอาต์พุต:$12/M |
ราคาสมาชิกรุ่นผู้ใช้ (แอป Gemini)
สำหรับแผนผู้ใช้ภายในแอป Gemini Google จัดระดับที่จำกัดการเข้าถึงรุ่นโมเดลและฟีเจอร์เสริม: Google AI Pro และ Google AI Ultra ราคาแตกต่างกันตามประเทศและสกุลเงิน; ตัวอย่างที่เผยแพร่แสดงว่า Google AI Pro ราคา $19.99/เดือน (มีโปรโมชันให้ทดลองใช้งาน) และมีการตั้งราคาตามสกุลเงินในหน้าโปรดักต์ (รวมทั้งข้อเสนอทดลองและส่วนลดช่วงสั้น) แผน AI Ultra ให้การเข้าถึงสูงกว่า (เช่น สิทธิพิเศษเข้าถึงนวัตกรรมใหม่ เครดิตสำหรับสร้างวิดีโอที่สูงขึ้น) ในอัตรารายเดือนที่มากกว่า ราคาสำหรับผู้บริโภคเหล่านี้แข่งขันได้เมื่อเทียบกับสมาชิกรุ่นผู้ใช้ระดับไฮเอนด์รายอื่น และวางตำแหน่งเพื่อให้ผู้ใช้ระดับพาวเวอร์หรือทีมเล็กเข้าถึงความสามารถของ 3.1 Pro ได้โดยไม่ต้องผสาน API
เคล็ดลับพรอมป์ต์และการใช้งานจริง (ที่แนะนำให้ทำ)
ใช้สิ่งเหล่านี้เพื่อให้ได้ผลลัพธ์ที่เชื่อถือได้และทำซ้ำได้:
- ตัววางแผนแบบเป็นขั้นตอนอย่างชัดเจน
รูปแบบพรอมป์ต์:1) Give a 3-step plan you will follow to complete X. 2) Execute step 1 and show artifact. 3) Confirm step 1 succeeded, then continue to step 2.สิ่งนี้ใช้ประโยชน์จากการดำเนินการทีละขั้นที่แข็งแรงขึ้นของ 3.1 Pro และให้จุดตรวจ - เอาต์พุตแบบมีโครงสร้างพร้อมสคีมา
ขอ JSON พร้อมสคีมาและstrict: trueเนื่องจาก 3.1 Pro สร้างผลลัพธ์ยาวที่ยึดตามสคีมาได้สม่ำเสมอกว่า คุณจึงได้คำตอบก้อนใหญ่ที่พาร์สต่อปลายน้ำได้ - แซนด์วิชตรวจด้วยเครื่องมือ
เมื่อเรียกใช้เครื่องมือภายนอก (API, ตัวรันโค้ด) ให้โมเดลสร้าง: แผน → คำสั่งเรียกเครื่องมือแบบตรงเป๊ะ (คัดลอก/วางได้) → ขั้นตอนตรวจสอบ แล้วจึงยืนยันขั้นตอนตรวจสอบเหล่านั้นนอกโมเดลก่อนเดินหน้าต่อ - อย่าเชื่อคำตอบขั้นเดียว
แม้โมเดลจะเขียนโค้ดหรือคำสั่งที่ดูสมบูรณ์แบบ ให้รันการตรวจสอบอิสระ (เทสต์ ไลน์เตอร์ การรันในแซนด์บ็อกซ์) โดยเฉพาะสำหรับการกระทำเชิงเอเจนต์/อัตโนมัติ
ทดลองใช้งานจริงกับ Gemini 3.1 Pro
เคสทดลอง 1: ผู้ช่วยวิจัยบริบทยาว (NotebookLM / Deep Research)
เป้าหมาย: ประเมินความสามารถของโมเดลในการสังเคราะห์เอกสารยาว 10–50 ฉบับ (เช่น รายงาน ไวท์เปเปอร์) เป็นสรุปผู้บริหารหลายหน้า พร้อมการอ้างอิงและรายการแผนปฏิบัติ
การตั้งค่า: ป้อนคลังข้อมูลรวม 200k–800k โทเค็น; มอบหมายให้โมเดลสร้างสรุป 2–4 หน้า พร้อมการอ้างอิงอย่างชัดเจนและข้อเสนอ “ขั้นตอนถัดไป” ใช้เทมเพลตพรอมป์ต์ที่ทำซ้ำได้ และวัดเวลา การใช้โทเค็น (ค่าใช้จ่าย) และความถูกต้องตามข้อเท็จจริง
ผลลัพธ์: การสรุปแบบครบวงจรที่เร็วขึ้นและมีอาร์ติแฟกต์จากการแบ่งชิ้นน้อยลงเมื่อเทียบกับรุ่นเก่า ความเที่ยงตรงของการอ้างอิงที่สูงขึ้นในสรุป และความสอดคล้องที่ดีขึ้นเมื่อสเกล — แลกกับการใช้โทเค็นจำนวนมาก (จึงควรวางแผนงบประมาณ) เบนช์มาร์กและการลองใช้งานชี้ว่า Gemini 3.1 Pro โดดเด่นในการสังเคราะห์ข้ามหลายเอกสารด้วยหน้าต่าง 1M โทเค็น
เคสทดลอง 2: ผู้ช่วยโค้ดดิ้งเชิงเอเจนต์ (Antigravity + GitHub Copilot)
เป้าหมาย: วัดการลดเวลาเสร็จงานสำหรับงานนักพัฒนาหลายขั้นตอน (เช่น เพิ่มฟีเจอร์ข้ามหลายไฟล์ รันเทสต์ แก้เทสต์ที่ล้มเหลว)
การตั้งค่า: ใช้ Antigravity หรือ GitHub Copilot เวอร์ชันพรีวิวโดยเลือก Gemini 3.1 Pro กำหนดงานที่ทำซ้ำได้ (สร้างอีซู → ลงมือทำ → รันเทสต์) บันทึกขั้นตอนและอาร์ติแฟกต์ของเอเจนต์ และเทียบกับเบสไลน์ที่ทำโดยมนุษย์ล้วน
ผลลัพธ์: การจัดลำดับงานหลายขั้นตอนที่ดีขึ้น (มีการบันทึกอาร์ติแฟกต์ เสนอแพตช์แคนดิเดตอัตโนมัติ) ความสามารถให้เหตุผลข้ามหลายไฟล์ที่ดีกว่า Gemini 3 Pro รุ่นก่อน และประหยัดเวลาว่างานฟีเจอร์ประจำที่วัดได้ งานดีบักระบบระดับล่างแบบเฉพาะทางอาจยังเป็นจุดแข็งของโมเดลที่เน้นโค้ดเป็นหลัก (ผลจากคอมมูนิตีแสดงช่องว่างเมื่อเทียบกับบางรุ่น GPT-Codex บนเบนช์มาร์กเทอร์มินัลบางรายการ)
เคสทดลอง 3: รีวิวเอกสารกฎหมาย/การแพทย์แบบมัลติโมดัล
เป้าหมาย: ใช้โมเดลกลืนข้อมูลแบบผสม (PDF สแกน ภาพ ทรานสคริปต์ออดิโอ) ดึงข้อเท็จจริงสำคัญ และสร้างเมทริกซ์ความเสี่ยงและแผนงานจัดลำดับความสำคัญ
การตั้งค่า: ป้อนชุดข้อมูลที่มีภาพสแกนและข้อความ OCR พร้อมออดิโอประกอบ วัดความแม่นยำในการดึงชื่อเอนทิตี อัตราบวกลวง และความสามารถของโมเดลในการอ้างถึงแหล่งที่มาของอาร์ติแฟกต์
ผลลัพธ์:
การให้เหตุผลแบบบูรณาการข้ามโมดัลที่แข็งแรงขึ้นและเอาต์พุตที่ตรวจสอบย้อนกลับได้ดีขึ้น (ความสามารถในการชี้ไปยังรูป/หน้า/เวลาในออดิโอที่รองรับข้อกล่าวอ้าง) หน้าต่างบริบทขนาดใหญ่ช่วยลดความจำเป็นในการแบ่งชิ้นและเทียบข้ามด้วยมือ อย่างไรก็ตาม ในโดเมนที่มีข้อกำกับ ควรให้นักเชี่ยวชาญโดเมนตรวจทานผลลัพธ์ และใช้ไปป์ไลน์ยึดโยง/ตรวจสอบ
ความประทับใจแรก (สิ่งที่รู้สึกต่าง)
- การให้เหตุผลแบบเป็นขั้นลึกขึ้น. งานที่ก่อนหน้านี้ต้องโต้ตอบไปมาหลายรอบ — เช่น การสังเคราะห์หลายเอกสาร คณิต/ตรรกะหลายขั้น — มักเสร็จในรอบน้อยลงและมีเอาต์พุตที่แสดงลำดับการคิดชัดเจนกว่า (โดยไม่เปิดเผยข้อความคำสั่งภายใน)
- เอาต์พุตแบบมีโครงสร้างที่ยาวและคุณภาพสูงขึ้น. JSON และงานอัตโนมัติเนื้อหายาวมีความสม่ำเสมอขึ้นและมักยาวกว่ามาก (ผู้ใช้บางรายรายงานเอาต์พุตใหญ่กว่ารุ่น 3.0 มาก) เหมาะกับงานเจเนอเรชันที่ต้องการเพย์โหลดก้อนเดียวใหญ่ๆ ควรเตรียมรับมือเอาต์พุตใหญ่และสตรีมมิง
- การใช้โทเค็น/บริบทมีประสิทธิภาพขึ้น. ประสิทธิภาพโทเค็นที่ดีขึ้นและพฤติกรรมที่ “ยึดโยงและถูกข้อเท็จจริงมากกว่า” ในสถานการณ์ใช้เครื่องมือ สะท้อนในอาการเพ้อเจ้อน้อยลงเมื่อค้นข้อเท็จจริงสั้นๆ
บทวิเคราะห์สรุป: ควรรับเอา Gemini 3.1 Pro ไปใช้ตอนนี้หรือไม่?
Gemini 3.1 Pro เป็นก้าวที่มีนัยสำคัญของตระกูล Gemini พร้อมหลักฐานปรับปรุงด้านการให้เหตุผล โค้ดดิ้ง และเบนช์มาร์กเชิงเอเจนต์ — หนุนหลังด้วย model card ที่ Google เผยแพร่และตัวติดตามอิสระที่ชี้การกระโดดใหญ่บนลีดเดอร์บอร์ดบางรายการ สำหรับทีมที่ต้องการการให้เหตุผลขั้นสูง การประสานเครื่องมือแบบเอเจนต์ หรือความสามารถมัลติโมดัลบริบทยาว 3.1 Pro เป็นตัวเลือกที่น่าพิจารณา
นักพัฒนาสามารถเข้าถึง Gemini 3.1 Pro ผ่าน CometAPI ได้แล้ว ขึ้นตอนเริ่มต้น ลองสำรวจความสามารถของโมเดลใน Playground และดู API guide สำหรับคำแนะนำละเอียด ก่อนใช้งาน โปรดตรวจให้แน่ใจว่าคุณได้ล็อกอิน CometAPI และได้รับ API key แล้ว CometAPI มีราคา thấpกว่าราคาอย่างเป็นทางการมากเพื่อช่วยให้คุณผสานรวมได้ง่ายขึ้น
พร้อมลุยหรือยัง?→ สมัครใช้งาน Gemini 3.1 Pro วันนี้
หากคุณต้องการเคล็ดลับ คู่มือ และข่าวสารด้าน AI เพิ่มเติม ติดตามเราได้ทาง VK, X และ Discord!