

เมื่อวันที่ 3 มีนาคม 2026 Google ได้เปิดตัว Gemini 3.1 Flash-Lite สมาชิกใหม่ล่าสุดของตระกูล Gemini 3 ที่ออกแบบมาโดยเฉพาะให้เป็นเอนจินที่มีปริมาณงานสูง เวลาแฝงต่ำ และคุ้มค่าต้นทุน สำหรับเวิร์กโหลดของนักพัฒนาและองค์กร Google วางตำแหน่ง Flash-Lite ว่าเป็นโมเดล “เร็วที่สุดและคุ้มค่าที่สุด” ในไลน์ Gemini 3: เวอร์ชันแบบเบาที่มุ่งเน้นการมอบปฏิสัมพันธ์แบบสตรีมมิง การประมวลผลเบื้องหลังขนาดใหญ่ และงานโปรดักชันความถี่สูง (เช่น การแปล การดึงข้อมูล การสร้าง UI และการจัดหมวดหมู่ปริมาณมาก) ที่มีราคาต่ำกว่าเวอร์ชัน Pro อย่างมาก
ด้านล่างนี้คือการอธิบายว่า Flash-Lite คืออะไร
What is Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite เป็นสมาชิกของตระกูล Gemini 3 ของ Google ที่ตั้งใจแลกความลึกในการให้เหตุผลระดับสูงบางส่วนกับความเร็วและความคุ้มค่าต้นทุน โดยเป็นมัลติโหมดแบบเนทีฟตามสายพันธุ์ของ Gemini (รับอินพุตได้ทั้งข้อความ รูปภาพ และโมดาลิตีอื่นๆ) แต่ได้รับการปรับจูนและปรับใช้โดยเฉพาะเพื่อให้ได้อัตราการประมวลผลโทเค็นต่อวินาทีสูงสุด และลดค่าใช้จ่ายต่อโทเค็นอย่างมากสำหรับเวิร์กโหลดที่ต้องการการอนุมานที่รวดเร็วและซ้ำๆ มากกว่าความลึกด้านการคิดวิเคราะห์สูงสุด โมเดลนี้อธิบายว่าพัฒนามาจากสถาปัตยกรรม 3.1 Pro แต่ปรับให้เหมาะสมกับอัตราส่งผ่าน เวลาแฝง และต้นทุน
Key design tradeoffs
ชื่อ “Lite” สื่อถึงการเน้นด้านวิศวกรรมของโมเดล:
- ให้อัตราส่งผ่านสำคัญกว่าการให้เหตุผลแบบหนัก: Flash-Lite ลดการคำนวณต่อโทเค็นโดยตั้งใจ เพื่อให้ได้เวลาถึงโทเค็นแรก (TTFT) ที่เร็วขึ้นและความเร็วเอาต์พุตต่อเนื่องสูงขึ้น เหมาะสำหรับไปป์ไลน์ที่ต้องตอบสนองคำขอแต่ละรายการอย่างรวดเร็วและที่สเกล (เช่น ฟิลเตอร์ความปลอดภัย ผู้ช่วยแบบเรียลไทม์ การสร้างเนื้อหาปริมาณสูง)
- คุ้มค่าต้นทุนสำหรับปริมาณงานสูง: ด้วยการลดการคำนวณต่อโทเค็น โมเดลจึงตั้งราคาได้ต่ำลงต่อหนึ่งล้านโทเค็น ซึ่งช่วยลดต้นทุนส่วนเพิ่มในแอปพลิเคชันขนาดใหญ่ (เช่น หลายล้านถึงพันล้านโทเค็นต่อเดือน) ตัวอย่างราคาพรีวิวของ Google แสดงให้เห็นความต่างที่ชัดเจนเมื่อเทียบกับระดับ Pro
- คุณภาพที่ปรับให้เหมาะกับงานเชิงปฏิบัติ: จากสรุปการให้คะแนนช่วงแรก Flash-Lite รักษาความแข็งแกร่งในงานจัดหมวดหมู่ มัลติงวล และงานมัลติโหมดจำนวนมาก แต่ไม่ได้วางตำแหน่งให้ชนะ Pro ในเบนช์มาร์กการให้เหตุผลหลายขั้นตอนที่ซับซ้อนหรือการสร้างโค้ดที่ต้องการความลึก
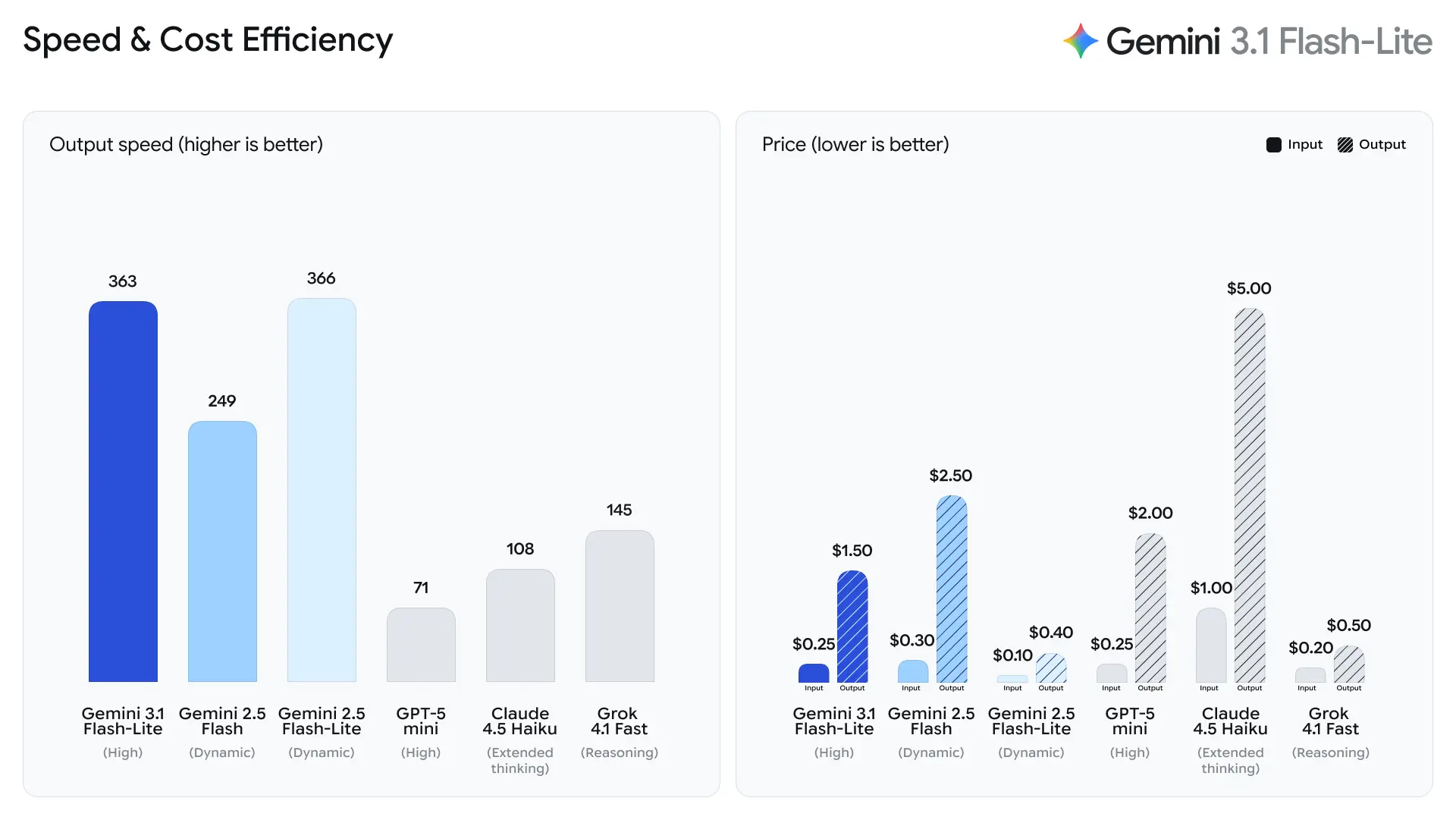
เวิร์กโหลดเหล่านี้ต้องการทั้ง ความน่าเชื่อถือของผลลัพธ์และอัตราส่งผ่านสูง แต่ไม่ได้ต้องการความสามารถในการให้เหตุผลหลายขั้นตอนที่ซับซ้อนของโมเดลเรือธงเสมอไป
Key Features of Gemini 3.1 Flash-Lite
1. เวลาแฝงต่ำและเวลาถึงโทเค็นแรกที่รวดเร็ว
Google เน้นเมตริก เวลาไปยังโทเค็นคำตอบตัวแรก เป็นเมตริกหลักของ Flash-Lite โดยรายงานว่าเวลาไปยังโทเค็นแรกเร็วขึ้น ประมาณ 2.5× เมื่อเทียบกับ Gemini 2.5 Flash และการสร้างเอาต์พุตเร็วขึ้นถึง 45% — ซึ่งส่งผลโดยตรงต่อความรู้สึกตอบสนองของผู้ใช้ปลายทางและต้นทุนอัตราส่งผ่านสำหรับระบบแบ็กเอนด์ การพัฒนานี้ทำให้ Flash-Lite เหมาะกับฟีเจอร์แบบโต้ตอบ (เช่น แชตบอทที่ฝังในแอป) และไปป์ไลน์ที่มี QPS สูงซึ่งระดับไมโครวินาทีมีความสำคัญ
การปรับปรุงนี้ช่วยเสริมประสิทธิภาพสำหรับแอปพลิเคชันเรียลไทม์อย่างมาก เช่น:
- conversational AI
- ผู้ช่วยค้นหาที่ขับเคลื่อนด้วย AI
- แชตบอทเชิงโต้ตอบ
- บริการแปลแบบสด
เวลาแฝงที่ต่ำลงช่วยยกระดับประสบการณ์ผู้ใช้ด้วยการลดเวลารอและทำให้การโต้ตอบลื่นไหลยิ่งขึ้น
2. การตั้งราคาต่อโทเค็นที่คุ้มค่า
ต้นทุนการอนุมานของ AI มักคิดตามจำนวนโทเค็น ทำให้ราคาเป็นปัจจัยสำคัญสำหรับการปรับใช้ในสเกลใหญ่
Gemini 3.1 Flash-Lite นำเสนอโครงสร้างราคาที่แข่งขันได้อย่างมาก:
| ประเภทโทเค็น | ราคา |
|---|---|
| โทเค็นอินพุต | $0.25 ต่อ 1M โทเค็น |
| โทเค็นเอาต์พุต | $1.50 ต่อ 1M โทเค็น |
นี่เป็นการลดลงเมื่อเทียบกับโมเดล Flash ก่อนหน้า ทำให้โมเดลนี้น่าดึงดูดสำหรับองค์กรที่รันเวิร์กโหลดขนาดใหญ่
เพื่อเปรียบเทียบ:
| โมเดล | ราคาอินพุต | ราคาเอาต์พุต |
|---|---|---|
| Gemini 3 Flash | $0.50 / 1M | $3.00 / 1M |
| Gemini 3.1 Flash-Lite | $0.25 / 1M | $1.50 / 1M |
กลยุทธ์การตั้งราคานี้ทำให้นักพัฒนาสามารถ รัน AI ในสเกลใหญ่โดยไม่ทำให้ต้นทุนการดำเนินงานเพิ่มขึ้นอย่างมาก
หากคุณกำลังมองหาราคาที่ดีกว่านี้ Gemini Flash-Lite มอบส่วนลด 20% บน CometAPI
3. “Thinking levels” (ระดับการคิดที่ควบคุมได้)
Gemini 3.1 Flash-Lite มาพร้อมความสามารถ “thinking levels” — ตัวปรับที่นักพัฒนาตั้งค่าได้เพื่อสั่งให้โมเดลเลือกประมวลผลแบบเร็วและตื้นสำหรับงานง่าย และทำเหตุผลลึกขึ้นสำหรับงานยาก ซึ่งสำคัญในทางปฏิบัติ เพราะช่วยให้เกิดการแลกเปลี่ยนระหว่างต้นทุน/เวลาแฝงแบบไดนามิกในแต่ละคำขอโดยไม่ต้องสลับโมเดล
นักพัฒนาสามารถกำหนดความลึกในการให้เหตุผลของโมเดลให้สอดคล้องกับความซับซ้อนของงานได้ Thinking levels: รองรับ 4 ระดับ: Minimal, Low, Medium และ High
แนวทางแบบไดนามิกนี้ช่วยให้อัปพลิเคชัน ปรับใช้ทรัพยากรอย่างเหมาะสม พร้อมรักษาคุณภาพในจุดที่สำคัญ ยุทธศาสตร์ในทางปฏิบัติโดยสรุปคือ:
- Minimal/Low: เหมาะกับงานพร้อมกันสูงแต่มีเหตุผลเชิงตรรกะไม่ซับซ้อน เช่น การแปล การจัดหมวดหมู่ และการวิเคราะห์ความรู้สึก โดยให้ความสำคัญกับความเร็วสูงสุดและต้นทุนต่ำสุด
- Medium: เหมาะกับงานโปรดักชันส่วนใหญ่ สมดุลระหว่างคุณภาพและประสิทธิภาพ
- High: เหมาะกับงานที่ต้องใช้เหตุผลลึก เช่น การสร้างส่วนติดต่อผู้ใช้ การสร้างแบบจำลองจำลอง และการปฏิบัติตามคำสั่งที่ซับซ้อน
4. ความสามารถแบบมัลติโหมดพร้อมขนาดที่เบา
แม้ Flash-Lite จะถูกปรับให้เหมาะกับความเร็วและต้นทุน แต่ยังคงฐานรากมัลติโหมดของไลน์ Gemini 3: สามารถรับอินพุตรูปภาพเพื่อการจัดหมวดหมู่หรือการให้เหตุผลแบบมัลติโหมดแบบเบาเมื่อกรณีใช้งานต้องการ — แต่นักพัฒนาควรคาดหวังว่าการออกแบบเชิงประหยัดจะเหมาะกับงานมัลติโหมดที่สั้นและมีขอบเขต มากกว่างานที่ใช้รูปภาพขนาดใหญ่มาก เช่นเดียวกับโมเดล Gemini อื่นๆ Gemini 3.1 Flash-Lite รองรับ อินพุตแบบมัลติโหมด ช่วยให้นักพัฒนาประมวลผลข้อมูลหลายประเภทได้
อินพุตที่รองรับประกอบด้วย:
- ข้อความ
- รูปภาพ
- วิดีโอ
- เสียง
ความสามารถของโมเดลในการวิเคราะห์ข้อมูลหลายประเภทช่วยเปิดทางให้กรณีใช้งานใหม่ๆ เช่น:
- การประมวลผลเอกสารอัตโนมัติ
- การดึงข้อมูลจากภาพ
- สรุปเนื้อหามัลติมีเดีย
โมเดล Gemini รุ่นก่อนหน้าแสดงให้เห็นถึงความสามารถในการให้เหตุผลแบบมัลติโหมดที่แข็งแกร่งในเบนช์มาร์กด้านภาพและความรู้เช่นกัน
Performance benchmarks — ตัวเลขจริงและความหมาย
ประกาศและเอกสารผลิตภัณฑ์ของ Google นำเสนอข้อมูลเบนช์มาร์กหลายรายการ เพื่อช่วยให้ผู้ซื้อมองเห็นตำแหน่งของ Flash-Lite ภายในอีโคซิสเต็ม
เมตริกความเร็วที่มุ่งสู่ฝั่งนักพัฒนา
- เวลาไปยังโทเค็นคำตอบตัวแรกเร็วขึ้น 2.5× เทียบกับ Gemini 2.5 Flash (ตามการเปรียบเทียบภายในที่ Google ระบุ)
- การสร้างเอาต์พุตเร็วขึ้น 45% เทียบกับ Gemini 2.5 Flash
สิ่งเหล่านี้เป็นเมตริกด้านวิศวกรรมประสิทธิภาพ ไม่ใช่เมตริกคุณภาพที่มนุษย์ตัดสิน; สะท้อนการปรับปรุงในไมโครอาร์คิเท็กเจอร์รันไทม์ การแบตช์ และการปรับแต่งสแตกอนุมานที่ลดเวลาแฝงสำหรับคำตอบสั้นๆ เวลาโทเค็นแรกที่เร็วยิ่งขึ้นช่วยลดความหน่วงที่รู้สึกได้ในแอปเชิงโต้ตอบและเพิ่มอัตราส่งผ่านต่อเซิร์ฟเวอร์โดยรวม ซึ่งสามารถลดต้นทุนคอมพิวต์รวมสำหรับ QPS เท่าเดิม
โทเค็นต่อวินาที (t/s) และอัตราส่งผ่าน
ตามข้อมูลการทดสอบของ Artificial Analysis 3.1 Flash-Lite ทำความเร็วเอาต์พุตได้ 388.8 โทเค็นต่อวินาที (ค่ามัธยฐานของโมเดลในช่วงราคาเดียวกันอยู่ที่เพียง 96.7 โทเค็น/วินาที) ความเร็วนับว่าอยู่ระดับท็อปในคลาสของมัน
อย่างไรก็ตาม Artificial Analysis ชี้ให้เห็นอีกประเด็น: เวลาโทเค็นแรก (TTFT) ของ 3.1 Flash-Lite อยู่ที่ 5.18 วินาที ซึ่งค่อนข้างสูงเมื่อเทียบกับโมเดลอนุมานในช่วงราคาเดียวกัน (ค่ามัธยฐานคือ 1.82 วินาที) นอกจากนี้ โมเดลยังสร้างเอาต์พุตรวม 53 ล้านโทเค็นในระหว่างการประเมิน ซึ่งสูงกว่าโดยเฉลี่ยที่ 20 ล้านพอสมควร หมายความว่าหากกรณีใช้งานของคุณไวต่อเวลาโทเค็นแรกมาก หรือมีข้อกำหนดที่เคร่งครัดด้านความกระชับของเอาต์พุต คุณอาจต้องปรับระดับการคิดและพรอมป์ต์ให้เหมาะสม
คะแนนเบนช์มาร์กด้านการให้เหตุผลและความถูกต้องเชิงข้อเท็จจริง
Google รวมการเปรียบเทียบข้ามโมเดลที่แสดงให้เห็นว่า Gemini 3.1 Flash-Lite ทำได้อย่างแข็งแกร่งเมื่อเทียบกับคู่แข่งและรุ่นก่อนในตระกูล Gemini บนงานรวมด้านการให้เหตุผล/ข้อเท็จจริง:
- คะแนน Elo ของ Arena.ai: รายงานว่า Gemini 3.1 Flash-Lite ได้ Elo 1432 บนกระดานจัดอันดับ Arena — เป็นการจัดอันดับแบบดวลตัวต่อตัวที่สะท้อนความสามารถแข่งขันโดยสัมพัทธ์ในสถานการณ์จับคู่จริง
- GPQA Diamond: 86.9% (ตัวชี้วัดความแกร่งในการตอบคำถาม)
- MMMU Pro: 76.8% (เมตริกมัลติโหมด/งานหลายอย่างที่ใช้ทั้งภายใน/ภายนอกโดยบางแล็บ)
- LiveCodeBench (ความสามารถด้านโค้ด): 72.0%
- CharXiv Reasoning (การให้เหตุผลเชิงกราฟิก): 73.2%
- Video-MMMU (ความเข้าใจวิดีโอ): 84.8%
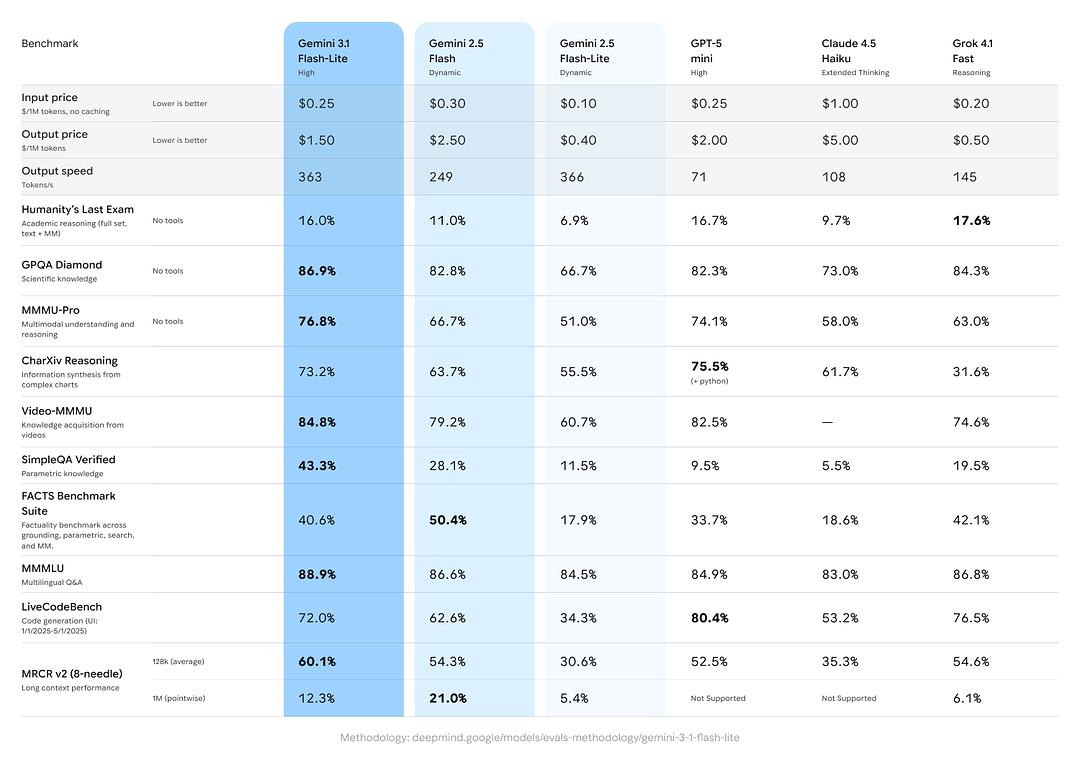
Gemini 3.1 Flash-Lite แซง Gemini 2.5 Flash รุ่นเก่าในหลายเมตริกเหล่านี้ พร้อมทั้งให้ความเร็ว/ต้นทุนที่ดีกว่าอย่างมาก
กรณีใช้งานที่เหมาะกับ Gemini 3.1 Flash-Lite
Gemini 3.1 Flash-Lite ถูกออกแบบมาสำหรับเวิร์กโหลดเชิงปฏิบัติชุดชัดเจน ที่ซึ่งอัตราส่งผ่านสูงและต้นทุนต่อโทเค็นที่ต่ำลงเป็นตัวแปรชี้ขาด:
เอเจนต์สนทนาความถี่สูงและ UI แบบสตรีมมิง
แชตบอทเรียลไทม์ สตรีมถอดความ+แปลแบบสด และ UI เชิงร่วมมือที่แสดงคำตอบบางส่วนระหว่างที่โมเดลกำลังสร้างผลลัพธ์ ได้ประโยชน์จากเอาต์พุตโทเค็นแบบสตรีมมิงและเวลาโทเค็นแรกที่ต่ำของ Flash-Lite
การประมวลผลข้อมูลจำนวนมาก (RAG, ไปป์ไลน์การแปลง)
การนำเข้าเอกสารขนาดใหญ่: การดึงเอนทิตี แท็กข้อมูลเมตา การจัดหมวดหมู่ และงานแปลเหนือเอกสารนับล้าน — Gemini 3.1 Flash-Lite ลดต้นทุนการอนุมานพร้อมให้ความแม่นยำที่ยอมรับได้สำหรับเอาต์พุตเชิงแม่แบบหรือขับเคลื่อนด้วยกฎ
งานสไตล์เอดจ์หรือประมวลผลเบื้องหลัง
เวิร์กโหลดที่ประมวลผลเทเลเมทรีหรือข้อมูลไม่มีโครงสร้างอย่างต่อเนื่อง (เช่น ไปป์ไลน์การจัดหมวดหมู่เพื่อกลั่นกรองเนื้อหา การสร้างรายงานอัตโนมัติ) เหมาะอย่างยิ่ง เพราะ Gemini 3.1 Flash-Lite ลดต้นทุนต่อหน่วยได้
เครื่องมือสำหรับนักพัฒนาและการเติมโค้ดแบบแบตช์
สำหรับฟีเจอร์อย่างโครงร่างหลายไฟล์ การลินต์โค้ดขนาดใหญ่ และการสร้างเทมเพลตในสเกล Gemini 3.1 Flash-Lite ช่วยลดเวลาแฝงและต้นทุนสำหรับเครื่องมือประสบการณ์นักพัฒนา ที่ไม่จำเป็นต้องใช้ความลึกในการให้เหตุผลสูงสุด
การเปรียบเทียบ Gemini 3.1 Flash-Lite กับโมเดล Gemini อื่นและคู่แข่ง
ภายในตระกูล Gemini
- Gemini 3.1 Pro: ความสามารถสูงสุดในงานให้เหตุผลซับซ้อนและการวางแผนหลายขั้นตอน; ต้นทุนต่อโทเค็นสูงกว่าและช้ากว่าอย่างมีนัย แต่ดีกว่าสำหรับงานที่ต้องการความละเอียดลึกซึ้ง
- Gemini 3.1 Flash (non-Lite): เล็งสมดุลระหว่างอัตราส่งผ่านดิบกับความสามารถ — ขณะที่ Flash-Lite ปรับให้เหมาะกับอัตราส่งผ่านลงไปในสแตกการคำนวณมากยิ่งขึ้น
เทียบกับโมเดล “เร็ว” จากคู่แข่ง
Gemini 3.1 Flash-Lite ทำได้ดีกว่าหรือทัดเทียบบางโมเดลแบบ fast/mini หลายตัวในเมตริกด้านอัตราส่งผ่านและคุณภาพ — แม้ว่า นักวิเคราะห์อิสระเตือนว่าการเปรียบเทียบแบบดวลตรงจะไวต่อวิธีประเมินและการเลือกชุดข้อมูล คาดหวังว่า Gemini 3.1 Flash-Lite จะมีความสามารถแข่งขันสูงด้านอัตราส่งผ่านและต้นทุน ขณะยังคงอยู่แถวกลางๆ ในเมตริกการให้เหตุผลระดับสูงสุด
บทสรุป — ตำแหน่งของ Flash-Lite ในสแตก AI
Gemini 3.1 Flash-Lite เป็นข้อเสนอที่ออกแบบมาอย่างจงใจ: สมาชิกของตระกูล Gemini 3 ที่เน้นประสิทธิภาพและอัตราส่งผ่าน ให้ทีมสามารถแลกการคำนวณต่อเคสบางส่วนเพื่อแลกกับการปรับปรุงอย่างมากในด้านเวลาแฝงและต้นทุน สำหรับธุรกิจและนักพัฒนาที่สร้างไปป์ไลน์ปริมาณสูง — การแปล การประมวลผลแบบแบตช์ UI แบบสตรีมมิง และงานเอเจนต์ความซับซ้อนปานกลาง — Flash-Lite เป็นเอนจินฐานที่สมเหตุสมผล สำหรับองค์กรที่ต้องการความซื่อสัตย์ด้านการให้เหตุผลสูงสุด รุ่น Pro ยังคงเป็นตัวเลือกที่เหมาะสม
หากเวิร์กโหลดของคุณถูกครอบงำด้วยการอนุมานสั้นๆ ซ้ำได้จำนวนมาก หรือคุณต้องการเอาต์พุตแบบสตรีมมิงอย่างรวดเร็วในสเกลใหญ่ Flash-Lite คุ้มค่าที่จะทดลอง หากเวิร์กโหลดของคุณยึดโยงกับการให้เหตุผลแบบหลายฮอปที่ลึก ให้วางแผนแบบไฮบริด: ส่งทราฟฟิกที่เน้นอัตราส่งผ่านไปยัง Flash-Lite และยกระดับเคสที่ซับซ้อน มูลค่าสูงไปยังโมเดล Pro
นักพัฒนาสามารถเข้าถึง Gemini 3.1 Flash Lite ผ่าน CometAPI ได้แล้ว เริ่มต้นด้วยการสำรวจความสามารถของโมเดลใน Playground และดู คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับคีย์ API แล้ว CometAPI เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมาก เพื่อช่วยให้คุณผนวกรวมได้
Ready to Go?→ Sign up fo Gemini 3.1 Flash lite today !
หากคุณต้องการเคล็ดลับ คู่มือ และข่าวสารเกี่ยวกับ AI เพิ่มเติม ติดตามเราได้บน VK, X และ Discord!