GPT-4o API เสียง: แบบครบวงจร /chat/completions ส่วนขยายจุดสิ้นสุดที่ยอมรับอินพุตเสียง (และข้อความ) ที่เข้ารหัส Opus และส่งคืนคำพูดหรือคำบรรยายที่สังเคราะห์ด้วยพารามิเตอร์ที่กำหนดค่าได้ (รุ่น =gpt-4o-audio-preview-<date>, speed, temperature) สำหรับการโต้ตอบด้วยเสียงแบบแบตช์และแบบสตรีม
ข้อมูลพื้นฐานของ GPT-4o Audio
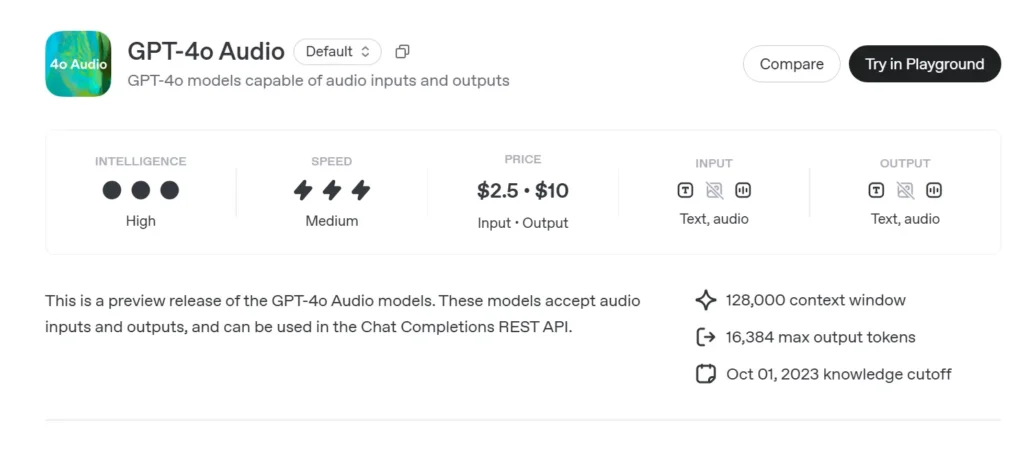
ตัวอย่างเสียง GPT-4o (gpt-4o-audio-preview-2025-06-03) คือ OpenAI ใหม่ล่าสุด แบบจำลองภาษาขนาดใหญ่ที่เน้นการพูด ทำให้มีให้ใช้ได้ผ่านมาตรฐาน API การเสร็จสิ้นการแชท แทนที่จะเป็นช่องสัญญาณเรียลไทม์ที่มีค่าความหน่วงต่ำเป็นพิเศษ ซึ่งสร้างขึ้นบนพื้นฐาน "omni" เดียวกับ GPT-4o โดยตัวแปรนี้เชี่ยวชาญในด้าน อินพุตและเอาท์พุตเสียงพูดที่มีความเที่ยงตรงสูง สำหรับการสนทนาแบบผลัดตา การสร้างเนื้อหา เครื่องมือการเข้าถึง และเวิร์กโฟลว์แบบเอเจนต์ที่ไม่ต้องการการจับเวลาเป็นมิลลิวินาที โดยสืบทอดจุดแข็งด้านการใช้เหตุผลในข้อความทั้งหมดของโมเดลคลาส GPT-4 ในขณะที่เพิ่ม การพูดต่อเสียงจากต้นทางถึงปลายทาง (S2S) ท่อส่งน้ำ, กำหนดได้ เรียกฟังก์ชันและใหม่ speed พารามิเตอร์ เพื่อการควบคุมอัตราเสียง
ชุดคุณสมบัติหลักของ GPT-4o Audio
• การประมวลผลคำพูดเป็นคำพูดแบบรวม – เสียงจะถูกแปลงโดยตรงเป็นโทเค็นที่อุดมไปด้วยความหมาย พิจารณาและสังเคราะห์ใหม่โดยไม่ใช้บริการ STT/TTS ภายนอก ส่งผลให้ ความสม่ำเสมอของโทนเสียง ท่วงทำนอง และการคงไว้ซึ่งบริบท.
• การปรับปรุงการปฏิบัติตามคำแนะนำ – ส่งมอบจูนจูนเดือนมิถุนายน 2025 +19 หน้าผ่าน 1 ในงานคำสั่งเสียงเทียบกับค่าพื้นฐาน GPT-2024o ในเดือนพฤษภาคม 4 โดยลดอาการประสาทหลอนในโดเมนต่างๆ เช่น การสนับสนุนลูกค้าและการร่างเนื้อหา
• การเรียกเครื่องมือที่มีเสถียรภาพ – ผลลัพธ์ของแบบจำลอง JSON ที่มีโครงสร้าง ซึ่งสอดคล้องกับรูปแบบการเรียกใช้ฟังก์ชัน OpenAI ช่วยให้สามารถเรียกใช้ API แบ็กเอนด์ (การค้นหา การจอง การชำระเงิน) ได้ ความแม่นยำของการโต้แย้งมากกว่า 95%.
• speed พารามิเตอร์ (0.25–4×) – นักพัฒนาสามารถปรับเปลี่ยนการเล่นเสียงพูดสำหรับการเรียนรู้แบบช้า การบรรยายแบบปกติ หรือโหมด “สแกนเสียง” อย่างรวดเร็ว ไม่มี การสังเคราะห์ข้อความใหม่ภายนอก
• การรับรู้การขัดจังหวะ – แม้จะไม่ได้ขับเคลื่อนโดยความล่าช้าเท่ากับเวอร์ชันเรียลไทม์ แต่การแสดงตัวอย่างก็รองรับ การสตรีมแบบบางส่วน:โทเค็นจะถูกปล่อยออกมาทันทีที่มีการคำนวณ ช่วยให้ผู้ใช้สามารถขัดจังหวะได้ก่อนหากจำเป็น
สถาปัตยกรรมทางเทคนิคของ GPT-4o
• หม้อแปลงไฟฟ้าแบบชั้นเดียว – เช่นเดียวกับอนุพันธ์ GPT-4o ทั้งหมด ตัวอย่างเสียงจะใช้ ตัวเข้ารหัส-ตัวถอดรหัสแบบรวม โดยที่ข้อความและโทเค็นเสียงจะผ่านบล็อกความสนใจที่เหมือนกัน ส่งเสริมการลงหลักปักฐานแบบข้ามโหมด
• การสร้างโทเค็นเสียงแบบลำดับชั้น – PCM ดิบ 16 kHz → แพทช์ log-mel → รหัสอะคูสติกหยาบ → โทเค็นความหมายการบีบอัดหลายขั้นตอนนี้ทำได้ ลดแบนด์วิดท์ลง 40–50× ในขณะที่ยังรักษาความแตกต่างไว้ ทำให้สามารถคลิปวิดีโอได้หลายนาทีต่อหน้าต่างบริบท
• น้ำหนักเชิงปริมาณ NF4 – การอนุมานได้รับการเสิร์ฟที่ 4 บิตปกติ-ลอยตัว ความแม่นยำในการตัดหน่วยความจำ GPU ลงครึ่งหนึ่งเมื่อเทียบกับ fp16 และการรักษาไว้ 70+ สตรีมมิ่ง RTF (ปัจจัยเรียลไทม์) บนโหนด A100-80 GB
• การสตรีมความสนใจและการแคช KV – การฝังแบบหมุนหน้าต่างเลื่อนช่วยรักษาบริบทไว้ตลอดระยะเวลาการพูดประมาณ 30 วินาทีในขณะที่ยังคง โอ(ล) การใช้หน่วยความจำ เหมาะสำหรับบรรณาธิการพอดแคสต์หรือเครื่องมือช่วยเหลือการอ่าน
การกำหนดเวอร์ชันและการตั้งชื่อ — ตัวอย่างเพลงพร้อมรุ่นที่มีการประทับวันที่
| ตัวบ่งชี้ | ช่อง | จุดมุ่งหมาย | วันที่ออกข่าว | Stability |
|---|---|---|---|---|
| gpt-4o-ตัวอย่างเสียง-2025-06-03 | API การเสร็จสิ้นการแชท | การโต้ตอบเสียงแบบผลัดตา งานตัวแทน | 03 มิถุนายน 2025 | ดูตัวอย่าง (ขอคำติชมเป็นกำลังใจ) |
องค์ประกอบหลักในชื่อ:
- GPT-4o – ครอบครัวมัลติโหมด Omni
- เสียง – ปรับให้เหมาะสมสำหรับกรณีการใช้งานการพูด
- ภาพตัวอย่าง – สัญญา API อาจมีการพัฒนา แต่ยังไม่ใช่ GA
- 2025-06-03 – ภาพรวมการฝึกอบรมและการปรับใช้สำหรับการทำซ้ำ
วิธีการเรียกใช้ GPT-4o Audio API จาก CometAPI
GPT-4o Audio API การกำหนดราคา API ใน CometAPI:
- อินพุตโทเค็น: $2 / M โทเค็น
- โทเค็นเอาต์พุต: $8 / M โทเค็น
ขั้นตอนที่ต้องดำเนินการ
- เข้าสู่ระบบเพื่อ โคเมตาปิดอทคอม. หากคุณยังไม่ได้เป็นผู้ใช้ของเรา กรุณาลงทะเบียนก่อน
- รับรหัส API ของข้อมูลรับรองการเข้าถึงของอินเทอร์เฟซ คลิก "เพิ่มโทเค็น" ที่โทเค็น API ในศูนย์ส่วนบุคคล รับรหัสโทเค็น: sk-xxxxx และส่ง
- รับ url ของเว็บไซต์นี้: https://api.cometapi.com/
วิธีการใช้งาน
- เลือก“
gpt-4o-audio-preview-2025-06-03” จุดสิ้นสุดในการส่งคำขอและกำหนดเนื้อหาคำขอ วิธีการร้องขอและเนื้อหาคำขอได้รับจากเอกสาร API ของเว็บไซต์ของเรา เว็บไซต์ของเรายังจัดเตรียมการทดสอบ Apifox ไว้เพื่อความสะดวกของคุณอีกด้วย - แทนที่ ด้วยคีย์ CometAPI จริงจากบัญชีของคุณ
- แทรกคำถามหรือคำขอของคุณลงในช่องเนื้อหา—นี่คือสิ่งที่โมเดลจะตอบสนอง
- ประมวลผลการตอบสนองของ API เพื่อรับคำตอบที่สร้างขึ้น
สำหรับข้อมูลการเข้าถึงโมเดลใน Comet API โปรดดู เอกสาร API.
สำหรับข้อมูลราคาโมเดลใน Comet API โปรดดู https://api.cometapi.com/pricing.
เวิร์กโฟลว์ API — การแชทเสร็จสิ้นด้วยส่วนเสียงและฟังก์ชัน
- รูปแบบการป้อนข้อมูล -
audio/*MIME หรือbase64ชิ้นส่วน WAV ฝังอยู่ในmessages[].content. - ตัวเลือกการส่งออก -
•mode: "text"→ ข้อความล้วนสำหรับการสร้างคำบรรยาย
•mode: "audio"→ ส่งคืน a ที่พริ้ว โหลด Opus หรือ µ-law พร้อมค่าประทับเวลา - การเรียกใช้ฟังก์ชัน - เพิ่ม
functions:โครงร่าง; แบบจำลองที่ปล่อยออกมาrole: "function"โดยมีอาร์กิวเมนต์ JSON นักพัฒนาสามารถดำเนินการเรียกเครื่องมือและส่งผลลัพธ์กลับมาได้ตามต้องการ - ควบคุมอัตรา - ตั้งค่า
voice.speed=1.25เพื่อเร่งการเล่น ช่วงที่ปลอดภัย 0.25–4.0 - ข้อจำกัดโทเค็น/เสียง – บริบท 128 k (~คำพูด 4 นาที) เมื่อเปิดตัว โทเค็นเสียง 4096 รายการ / โทเค็นข้อความ 8192 รายการ อันไหนก็ได้ก่อน
ตัวอย่างโค้ดและการรวม API
pythonimport openai
openai.api_key = "YOUR_API_KEY"
# Single-step audio completion (batch)
with open("prompt.wav", "rb") as audio:
response = openai.ChatCompletion.create(
model="gpt-4o-audio-preview-2025-06-03",
messages=[
{"role": "system", "content": "You are a helpful voice assistant."},
{"role": "user", "content": "audio", "audio": audio}
],
temperature=0.3,
speed=1.2 # 20% faster playback
)
print(response.choices.message)
- ไฮไลท์:
- แบบ:
"gpt-4o-audio-preview-2025-06-03" - เสียง คีย์เข้า ผู้ใช้งาน ข้อความที่จะส่งสตรีมไบนารี
- ความเร็ว: การควบคุม อัตราเสียง ระหว่างช้า (0.5) และเร็ว (2.0)
- อุณหภูมิ: ยอดคงเหลือ ความคิดสร้างสรรค์ เมื่อเทียบกับ ความมั่นคง
ตัวบ่งชี้ทางเทคนิค — ความหน่วง คุณภาพ ความแม่นยำ
| เมตริก | ตัวอย่างเสียง | GPT-4o (ข้อความเท่านั้น) | สันดอน |
|---|---|---|---|
| ความล่าช้าของโทเค็นแรก (1 ช็อต) | 1.2 s เฉลี่ย | 0.35 s | +0.85 วิ |
| MOS (ความเป็นธรรมชาติของคำพูด 5 คะแนน) | 4.43 | - | - |
| การปฏิบัติตามคำสั่ง (เสียง) | 92% | 73% | +19 หน้า |
| ความแม่นยำของการเรียกฟังก์ชันอาร์กิวเมนต์ | 95.8% | 87% | +8.8 หน้า |
| อัตราข้อผิดพลาดของคำ (Implicit STT) | 5.2% | N / A | - |
| หน่วยความจำ GPU / สตรีม (A100-80GB) | 7.1 GB | 14GB (fp16) ความจุ | −49% |
เกณฑ์มาตรฐานดำเนินการผ่านการสตรีม Chat Completions ขนาดชุด = 1
ดูเพิ่มเติม GPT-4o API แบบเรียลไทม์