

ณ วันที่ December 15, 2025 ข้อเท็จจริงสาธารณะชี้ว่า Google’s Gemini 3 Pro (preview) และ OpenAI’s GPT-5.2 ต่างก็ขยายขอบเขตใหม่ในด้านการให้เหตุผล มัลติโหมด และงานบริบทยาว — แต่เลือกวิถีวิศวกรรมต่างกัน (Gemini → sparse MoE + บริบทขนาดใหญ่; GPT-5.2 → ดีไซน์แบบ dense/“routing”, การอัดย่อ และโหมด reasoning ระดับ x-high) จึงมีการแลกเปลี่ยนระหว่าง ชัยชนะสูงสุดบนเบนช์มาร์ก กับ ความคาดการณ์ได้ของวิศวกรรม เครื่องมือ และระบบนิเวศ ว่าแบบไหน “ดีกว่า” ขึ้นอยู่กับความต้องการหลักของคุณ: แอปเชิงตัวแทนแบบมัลติโหมดที่ต้องการบริบทสุดขั้ว เอนเอียงไปทาง Gemini 3 Pro; เครื่องมือสำหรับนักพัฒนาระดับองค์กรที่เสถียร ต้นทุนคาดการณ์ได้ และการเข้าถึง API ทันที เหมาะกับ GPT-5.2
What is GPT-5.2 and what are its main features?
GPT-5.2 คือรุ่นเปิดตัววันที่ 11 ธันวาคม 2025 ในตระกูล GPT-5 (มีรุ่นย่อย: Instant, Thinking, Pro) วางตำแหน่งเป็นโมเดลที่ทรงพลังที่สุดของบริษัทสำหรับ “งานความรู้แบบมืออาชีพ” — ปรับแต่งเพื่อสเปรดชีต งานพรีเซนเทชัน การให้เหตุผลบริบทยาว การเรียกใช้เครื่องมือ การสร้างโค้ด และงานด้านภาพ OpenAI เปิดให้ผู้ใช้ ChatGPT แบบชำระเงินและผ่าน OpenAI API (Responses API / Chat Completions) ภายใต้ชื่อโมเดล เช่น gpt-5.2, gpt-5.2-chat-latest, และ gpt-5.2-pro.
Model variants and intended use
- gpt-5.2 / GPT-5.2 (Thinking) — เหมาะที่สุดสำหรับการให้เหตุผลซับซ้อนหลายขั้นตอน (ตัวแปร “Thinking” เริ่มต้นที่ใช้ใน Responses API)
- gpt-5.2-chat-latest / Instant — หน่วงต่ำสำหรับงานผู้ช่วยและแชตประจำวัน
- gpt-5.2-pro / Pro — ความเที่ยงตรง/ความน่าเชื่อถือสูงสุดสำหรับปัญหายาก (ใช้คอมพิวต์เพิ่ม รองรับ
reasoning_effort: "xhigh")
Key technical features (user-facing)
- การมองเห็นและมัลติโหมดที่ดีขึ้น — การให้เหตุผลเชิงพื้นที่บนภาพดีขึ้น และความเข้าใจวิดีโอที่ดีขึ้นเมื่อใช้ร่วมกับเครื่องมือโค้ด (เครื่องมือ Python) พร้อมรองรับเครื่องมือสไตล์ code-interpreter สำหรับรันสคริปต์
- การกำหนดระดับความพยายามในการให้เหตุผลได้ (
reasoning_effort: none|minimal|low|medium|high|xhigh) เพื่อแลกเปลี่ยนเวลาหน่วง/ค่าใช้จ่ายกับความลึกxhighเป็นของใหม่ใน GPT-5.2 (และรองรับบน Pro) - การจัดการบริบทยาวที่ดีขึ้น และความสามารถในการอัดย่อ เพื่อให้เหตุผลข้ามหลายแสนโทเคน (OpenAI รายงานตัวชี้วัด MRCRv2/บริบทยาวที่แข็งแกร่ง)
- การเรียกใช้เครื่องมือและเวิร์กโฟลว์เชิงตัวแทนขั้นสูง — การประสานงานหลายเทิร์นที่แกร่งขึ้น จัดระเบียบเครื่องมือได้ดีขึ้นในสถาปัตยกรรม “mega-agent เดียว” (OpenAI เน้นผล Tau2-bench ด้านเครื่องมือ)
What is Gemini 3 Pro Preview?
Gemini 3 Pro Preview คือโมเดล Generative AI ขั้นสูงสุดของ Google ที่เปิดตัวเป็นส่วนหนึ่งของตระกูล Gemini 3 ในเดือนพฤศจิกายน 2025 โมเดลนี้เน้น ความเข้าใจเชิงมัลติโหมด — รองรับการทำความเข้าใจและสังเคราะห์ข้อความ รูปภาพ วิดีโอ และเสียง — และมีหน้าต่างบริบทขนาดใหญ่ (~1 ล้านโทเคน) สำหรับจัดการเอกสารหรือฐานโค้ดขนาดมหึมาในคำขอเดียว
Google วางตำแหน่ง Gemini 3 Pro ว่าเป็นระดับแนวหน้าด้าน ความลึกและความละเอียดอ่อนของการให้เหตุผล และเป็นแกนกลางให้กับเครื่องมือสำหรับนักพัฒนาและองค์กรหลายตัว รวมถึง Google AI Studio, Vertex AI และแพลตฟอร์มพัฒนาเชิงตัวแทน อย่าง Google Antigravity
ปัจจุบัน Gemini 3 Pro อยู่ในสถานะ preview — หมายถึงฟังก์ชันและการเข้าถึงยังคงขยาย แต่โมเดลทำคะแนนสูงอยู่แล้วทั้งด้านตรรกะ ความเข้าใจมัลติโหมด และเวิร์กโฟลว์เชิงตัวแทน
Key technical & product features
- Context window: Gemini 3 Pro Preview รองรับ อินพุต 1,000,000 โทเคน (และเอาต์พุตสูงสุด 64k โทเคน) ซึ่งเป็นข้อได้เปรียบเชิงปฏิบัติชัดเจนสำหรับการย่อยเอกสารยาวมาก หนังสือ หรือถอดเสียงวิดีโอในคำขอเดียว
- API features: พารามิเตอร์
thinking_level(low/high) เพื่อแลกความหน่วงกับความลึกการให้เหตุผล; การตั้งค่าmedia_resolutionเพื่อควบคุมความเที่ยงตรงมัลติโหมดและการใช้โทเคน; รองรับการยึดโยงกับการค้นหา บริบทไฟล์/URL การรันโค้ด และการเรียกฟังก์ชัน มีลายเซ็นความคิดและการแคชบริบทช่วยคงสถานะข้ามหลายการเรียก - Deep Think mode / higher reasoning: ตัวเลือก “Deep Think” เพิ่มรอบการให้เหตุผลพิเศษเพื่อดันคะแนนบนโจทย์ยาก Google เผย Deep Think เป็นเส้นทางสมรรถนะสูงแยกต่างหากสำหรับปัญหาซับซ้อน
- Multimodal native support: อินพุตข้อความ ภาพ เสียง และวิดีโอ พร้อมการยึดโยงกับการค้นหาและผลิตภัณฑ์แน่นแฟ้น (เน้นคะแนน Video-MMMU และเบนช์มาร์กมัลติโหมดอื่น ๆ)
Quick preview — GPT-5.2 vs Gemini 3 Pro
ตารางเปรียบเทียบแบบย่อด้วยข้อเท็จจริงสำคัญ (มีอ้างอิงแหล่งที่มา)
| ประเด็น | GPT-5.2 (OpenAI) | Gemini 3 Pro (Google / DeepMind) |
|---|---|---|
| ผู้พัฒนา / การวางตำแหน่ง | OpenAI — เรือธงอัปเกรด GPT-5.x โฟกัสงานความรู้มืออาชีพ การเขียนโค้ด และเวิร์กโฟลว์เชิงตัวแทน | Google DeepMind / Google AI — เรือธงตระกูล Gemini เน้นการให้เหตุผลมัลติโหมดบริบทยาวพิเศษและการผนวกเครื่องมือ |
| รุ่นหลัก | Instant, Thinking, Pro (และ Auto ที่สลับระหว่างกันได้) Pro เพิ่มระดับ reasoning สูงขึ้น | ตระกูล Gemini 3 รวมถึง Gemini 3 Pro และโหมด Deep-Think; โฟกัสมัลติโหมด/เชิงตัวแทน |
| หน้าต่างบริบท (อินพุต / เอาต์พุต) | ~400,000 โทเคนความจุอินพุตรวม; เอาต์พุต/โทเคนสำหรับ reasoning ได้สูงสุด 128,000 (ออกแบบมาสำหรับเอกสาร/ฐานโค้ดยาวมาก) | อินพุตได้สูงสุด ~1,000,000 โทเคน (1M) พร้อมเอาต์พุตสูงสุด 64K โทเคน |
| จุดแข็ง/โฟกัสหลัก | การให้เหตุผลบริบทยาว การเรียกใช้เครื่องมือเชิงตัวแทน การเขียนโค้ด งานสำนักงานเชิงโครงสร้าง (สเปรดชีต พรีเซนเทชัน); อัปเดตความปลอดภัย/การ์ดระบบเน้นความเชื่อถือได้ | ความเข้าใจมัลติโหมดขนาดใหญ่ การให้เหตุผล + การจัดองค์ประกอบภาพ บริบทขนาดใหญ่พิเศษ + โหมด “Deep Think” การให้เหตุผล เข้ากับระบบนิเวศ Google ได้แน่น |
| ความสามารถมัลติโหมดและภาพ | การมองเห็นและการยึดโยงมัลติโหมดดีขึ้น ปรับจูนเพื่อการใช้เครื่องมือและวิเคราะห์เอกสาร | การสร้างภาพความเที่ยงตรงสูง + การให้เหตุผลช่วยการจัดองค์ประกอบภาพ การแก้ไขภาพจากอ้างอิงหลายภาพ และการเรนเดอร์ข้อความอ่านชัด |
| เวลาหน่วง / การโต้ตอบ | ผู้พัฒนาระบุว่ามีการอนุมานเร็วขึ้นและตอบสนองพรอมพ์ไวขึ้น (หน่วงต่ำกว่า GPT-5.x ก่อนหน้า); มีหลายระดับบริการ (Instant / Thinking / Pro) | Google ระบุการเสิร์ฟที่ปรับให้เหมาะสม (“Flash”/serving) และความเร็วโต้ตอบใกล้เคียงในหลายโฟลว์; โหมด Deep Think แลกเวลาหน่วงกับความลึกในการให้เหตุผล |
| คุณลักษณะเด่น / ตัวแยกความแตกต่าง | ระดับความพยายามในการให้เหตุผล (medium/high/xhigh) การเรียกใช้เครื่องมือดีขึ้น การสร้างโค้ดคุณภาพสูง ประหยัดโทเคนสำหรับเวิร์กโฟลว์องค์กร | บริบท 1M โทเคน การรับมัลติโหมดแบบเนทีฟที่แข็งแกร่ง (วิดีโอ/เสียง) โหมด “Deep Think” และการผนวกผลิตภัณฑ์ Google (Docs/Drive/NotebookLM) อย่างแน่นแฟ้น |
| กรณีใช้งานที่เหมาะสม (สั้น) | วิเคราะห์เอกสารยาว เวิร์กโฟลว์เชิงตัวแทน โปรเจกต์โค้ดซับซ้อน ระบบอัตโนมัติในองค์กร (สเปรดชีต/รายงาน) | โปรเจกต์มัลติโหมดขนาดใหญ่มาก เวิร์กโฟลว์เชิงตัวแทนแบบระยะยาวที่ต้องใช้บริบท 1M โทเคน ไปป์ไลน์ภาพขั้นสูง + การให้เหตุผล |
How do GPT-5.2 and Gemini 3 Pro compare architecturally?
Core architecture
- Benchmarks / real-work evals: GPT-5.2 Thinking ทำได้ 70.9% ชนะ/เสมอ บน GDPval (การประเมินงานความรู้ 44 อาชีพ) และก้าวกระโดดบนเบนช์มาร์กวิศวกรรมและคณิตเมื่อเทียบรุ่น GPT-5 ก่อนหน้า ดีขึ้นมากในโค้ดดิ้ง (SWE-Bench Pro) และคำถาม-คำตอบสายวิทยาศาสตร์เชิงลึก (GPQA Diamond)
- Tooling & agents: รองรับการเรียกใช้เครื่องมือ การรัน Python และเวิร์กโฟลว์เชิงตัวแทน (ค้นหาเอกสาร วิเคราะห์ไฟล์ เอเจนต์ด้านข้อมูล) อย่างแข็งแกร่ง เร็วกว่า 11 เท่า / ต้นทุน <1% เทียบผู้เชี่ยวชาญมนุษย์สำหรับบางงาน GDPval (ตัวชี้วัดมูลค่าเศรษฐกิจที่เป็นไปได้, 70.9% เทียบ ~38.8% ก่อนหน้า) และเห็นการพัฒนาที่จับต้องได้ในงานสร้างแบบจำลองสเปรดชีต (เช่น +9.3% บนงานวิเคราะห์การเงินระดับจูเนียร์เทียบ GPT-5.1)
- Gemini 3 Pro: สถาปัตยกรรม Transformer แบบ Sparse Mixture-of-Experts (MoE) โมเดลจะเปิดใช้งานผู้เชี่ยวชาญเพียงบางส่วนต่อโทเคน ทำให้มีความจุพารามิเตอร์รวมมหาศาล โดยคอมพิวต์ต่อโทเคนเติบโตช้ากว่าเชิงเส้น เอกสารโมเดลระบุว่า Sparse MoE เป็นปัจจัยหลักของโปรไฟล์สมรรถนะที่ดีขึ้น จึงผลักดันความจุโมเดลให้สูงมากได้โดยไม่เพิ่มต้นทุนอนุมานเชิงเส้น
- GPT-5.2 (OpenAI): ยังคงใช้สถาปัตยกรรมแบบ Transformer พร้อมกลยุทธ์การกำหนดเส้นทาง/การอัดย่อในตระกูล GPT-5 (ตัว “router” กระตุ้นโหมดต่าง ๆ — Instant vs Thinking — และบริษัทบันทึกเทคนิคการอัดย่อและการจัดการโทเคนสำหรับบริบทยาว) GPT-5.2 เน้นการฝึก/ประเมินเพื่อ “คิดก่อนตอบ” และการอัดย่อสำหรับงานระยะยาว แทนการประกาศใช้ sparse-MoE ขนาดใหญ่แบบคลาสสิก
Implications of the architectures
- การแลกเปลี่ยนเวลาหน่วงและต้นทุน: โมเดล MoE อย่าง Gemini 3 Pro สามารถให้ สมรรถนะต่อโทเคนสูงสุด ขณะคุมต้นทุนอนุมานให้ต่ำในหลายงาน เพราะรันผู้เชี่ยวชาญเพียงบางส่วน แต่เพิ่มความซับซ้อนด้านการเสิร์ฟและการจัดคิว (สมดุลผู้เชี่ยวชาญ cold-start, IO) แนวทางของ GPT-5.2 (dense/route พร้อมอัดย่อ) เอื้อต่อเวลาหน่วงที่คาดการณ์ได้และเสถียรภาพสำหรับนักพัฒนา — โดยเฉพาะเมื่อผนวกกับเครื่องมือ OpenAI เช่น Responses, Realtime, Assistants และ Batch
- การสเกลบริบทยาว: ความสามารถอินพุต 1M โทเคนของ Gemini ทำให้ป้อนเอกสารยาวมากและสตรีมมัลติโหมดได้โดยเนทีฟ GPT-5.2 ที่มีบริบทผสม ~400k (อินพุต+เอาต์พุต) ก็ยังมโหฬารและครอบคลุมความต้องการองค์กรส่วนใหญ่ แต่เล็กกว่า 1M ของ Gemini สำหรับคลังข้อมูลใหญ่มากหรือถอดเสียงวิดีโอหลายชั่วโมง สเปกของ Gemini ให้ข้อได้เปรียบชัดเจน
Tooling, agents, and multimodal plumbing
- OpenAI: การผสานลึกสำหรับการเรียกใช้เครื่องมือ การรัน Python โหมด reasoning แบบ Pro และระบบนิเวศเอเจนต์แบบชำระเงิน (ChatGPT Agents / การผสานเครื่องมือองค์กร) โฟกัสเวิร์กโฟลว์เน้นโค้ดและการสร้างสเปรดชีต/สไลด์เป็นผลลัพธ์หลัก
- Google / Gemini: มีการยึดโยงกับ Google Search (ฟีเจอร์เสียเงินแบบเลือกใช้) การรันโค้ด บริบท URL และไฟล์ และตัวเลือกความละเอียดสื่อเพื่อแลกโทเคนกับความคมชัด API มี
thinking_levelและตัวเลือกอื่น ๆ เพื่อปรับสมดุลต้นทุน/หน่วง/คุณภาพ
How do the benchmark numbers compare
Context windows and token handling
- Gemini 3 Pro Preview: อินพุต 1,000,000 โทเคน / เอาต์พุต 64k โทเคน (การ์ดโมเดล Pro preview) วันที่ตัดความรู้: January 2025 (Google)
- GPT-5.2: OpenAI แสดงสมรรถนะบริบทยาวที่แข็งแกร่ง (คะแนน MRCRv2 ข้ามงาน needle 4k–256k หลายเซ็ตติ้งอยู่ในช่วง >85–95%) และใช้การอัดย่อ; ตัวอย่างสาธารณะชี้ถึงความเสถียรแม้บริบทใหญ่มาก แต่ OpenAI ระบุหน้าต่างบริบทตามรุ่นย่อย (และเน้นการอัดย่อมากกว่าการประกาศตัวเลข 1M เดียว) สำหรับการใช้ API ชื่อโมเดลคือ
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-pro.
Reasoning and agentic benchmarks
- OpenAI (คัดมา): Tau2-bench Telecom 98.7% (GPT-5.2 Thinking) ได้กำไรเด่นในงานใช้เครื่องมือหลายขั้นและงานเชิงตัวแทน (OpenAI เน้นการยุบระบบหลายเอเจนต์เป็น “mega-agent” เดียว) GPQA Diamond และ ARC-AGI ดีขึ้นแบบก้าวกระโดดเทียบ GPT-5.1
- Google (คัดมา): Gemini 3 Pro: LMArena 1501 Elo, MMMU-Pro 81%, Video-MMMU 87.6%, คะแนน GPQA และ Humanity’s Last Exam สูง; Google ยังสาธิตการวางแผนระยะยาวที่แข็งแรงผ่านตัวอย่างเชิงตัวแทน
Tooling & agents:
GPT-5.2: รองรับการเรียกใช้เครื่องมือ การรัน Python และเวิร์กโฟลว์เชิงตัวแทน (ค้นหาเอกสาร วิเคราะห์ไฟล์ เอเจนต์วิทยาการข้อมูล) อย่างแข็งแกร่ง เร็วกว่า 11 เท่า / ต้นทุน <1% เทียบผู้เชี่ยวชาญมนุษย์สำหรับบางงาน GDPval (ตัวชี้วัดมูลค่าเศรษฐกิจที่เป็นไปได้ , 70.9% เทียบ ~38.8% ก่อนหน้า) และเห็นกำไรชัดเจนในงานสร้างแบบจำลองสเปรดชีต (เช่น +9.3% บนงานธนาคารลงทุนระดับจูเนียร์เทียบ GPT-5.1)
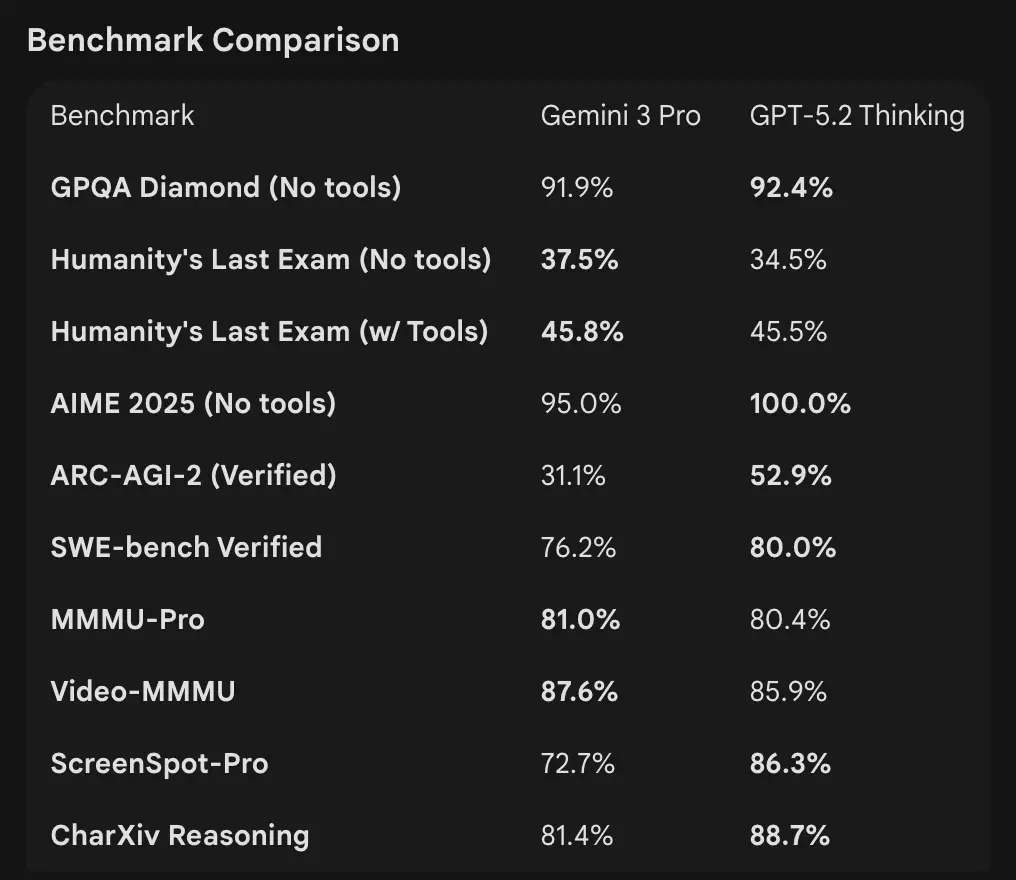
Interpretation: เบนช์มาร์กเสริมกัน — OpenAI เน้นเบนช์มาร์ก งานความรู้โลกจริง (GDPval) แสดงว่า GPT-5.2 เด่นในงานผลิตจริงอย่างสเปรดชีต สไลด์ และลำดับงานเชิงตัวแทนยาว ส่วน Google เน้น ลีดเดอร์บอร์ดการให้เหตุผลดิบ และหน้าต่างบริบทขนาดใหญ่มากในคำขอเดียว อะไรสำคัญกว่าขึ้นอยู่กับเวิร์กโหลด: ไปป์ไลน์องค์กรเชิงตัวแทนกับเอกสารยาวเอียงไปทางสมรรถนะ GDPval ของ GPT-5.2; การย่อยบริบทดิบมหาศาล (เช่น คลังวิดีโอทั้งก้อน/หนังสือเต็มเล่มในพาสเดียว) เอียงไปทางหน้าต่างอินพุต 1M ของ Gemini
How do multimodal capabilities compare?
Inputs & outputs
- Gemini 3 Pro Preview: รองรับอินพุต ข้อความ ภาพ วิดีโอ เสียง PDF และเอาต์พุตเป็นข้อความ; Google มีตัวควบคุม
media_resolutionแบบละเอียดและพารามิเตอร์thinking_levelเพื่อปรับสมดุลต้นทุนต่อความเที่ยงตรงสำหรับงานมัลติโหมด เอาต์พุตสูงสุด 64k โทเคน; อินพุตได้ถึง 1M โทเคน - GPT-5.2: รองรับเวิร์กโฟลว์วิชวลและมัลติโหมดที่หลากหลาย; OpenAI เน้นการให้เหตุผลเชิงพื้นที่ที่ดีขึ้น (การประมาณขอบเขตองค์ประกอบภาพ) ความเข้าใจวิดีโอ (คะแนน Video MMMU) และวิชวลที่ขับเคลื่อนด้วยเครื่องมือ (การใช้เครื่องมือ Python บนงานวิชวลช่วยเพิ่มคะแนน) GPT-5.2 เน้นว่างานภาพ+โค้ดซับซ้อนดีขึ้นมากเมื่อเปิดการสนับสนุนเครื่องมือโค้ด (รัน Python)
Practical differences
ความละเอียดละเอียดอ่อน vs. ความกว้าง: Gemini เปิดชุดตัวปรับมัลติโหมด (media_resolution, thinking_level) ให้ปรับสมดุลรายสื่อได้ ส่วน GPT-5.2 เน้นการใช้เครื่องมือแบบบูรณาการ (รัน Python ในลูป) เพื่อผสานวิชวล โค้ด และการแปลงข้อมูล หากเคสของคุณหนักไปทางวิเคราะห์วิดีโอ+ภาพพร้อมบริบทยาวมาก สเปก 1M บริบทของ Gemini น่าสนใจ; หากเวิร์กโฟลว์ต้องรันโค้ดในลูป (แปลงข้อมูล สร้างสเปรดชีต) เครื่องมือโค้ดและมิตรภาพต่อเอเจนต์ของ GPT-5.2 อาจสะดวกกว่า
What about API access, SDKs and pricing?
OpenAI GPT-5.2 (API & pricing)
- API:
gpt-5.2,gpt-5.2-chat-latest,gpt-5.2-proผ่าน Responses API / Chat Completions มี SDK ที่มั่นคง (Python/JS) คู่มือ cookbook และระบบนิเวศที่สุกงอม - Pricing (public): $1.75 / 1M input tokens และ $14 / 1M output tokens; ส่วนลดแคช (90% สำหรับอินพุตที่แคช) ลดต้นทุนจริงสำหรับข้อมูลซ้ำ OpenAI เน้นประสิทธิภาพโทเคน (ราคาต่อโทเคนสูงกว่าแต่ใช้โทเคนน้อยลงเพื่อให้ได้คุณภาพเป้าหมาย)
Gemini 3 Pro Preview (API & pricing)
- API:
gemini-3-pro-previewผ่าน Google GenAI SDK และ Vertex AI/GenerativeLanguage endpoints มีพารามิเตอร์ใหม่ (thinking_level,media_resolution) และการผนวกกับ Google groundings และเครื่องมือต่าง ๆ - Pricing (public preview): โดยประมาณ $2 / 1M input tokens และ $12 / 1M output tokens สำหรับระดับ preview ต่ำกว่า 200k โทเคน; อาจมีค่าใช้จ่ายเพิ่มเติมสำหรับ Search grounding, Maps หรือบริการ Google อื่น ๆ (การคิดเงิน Search grounding เริ่ม 5 ม.ค. 2026)
Use GPT-5.2 and Gemini 3 Via CometAPI
CometAPI คือเกตเวย์/ตัวรวม API: จุดปลาย REST สไตล์ OpenAI เดียวที่ให้คุณเข้าถึง โมเดลนับร้อย จากหลายผู้ขาย (LLMs, โมเดลภาพ/วิดีโอ โมเดลเวกเตอร์ฝัง ฯลฯ) โดยไม่ต้องอินทิเกรต SDK หลายเจ้า CometAPI อนุญาตให้เรียกเอ็นด์พอยต์รูปแบบคุ้นเคย (chat/completions/embeddings/images) พร้อมสลับโมเดลหรือผู้ขายเบื้องหลังได้
นักพัฒนาสามารถใช้โมเดลเรือธงจากสองบริษัทพร้อมกันผ่าน CometAPI โดยไม่ต้องสลับผู้ขาย และราคาผ่าน API มักถูกกว่า ปกติลดราว 20%
Example: quick API snippets (copy-paste to try)
ด้านล่างคือตัวอย่างขั้นต่ำที่คุณรันได้ สะท้อน quickstart ของผู้ขาย (OpenAI Responses API + Google GenAI client) แทนค่า $OPENAI_API_KEY / $GEMINI_API_KEY ด้วยคีย์ของคุณ
GPT-5.2 — Python (OpenAI Responses API, reasoning set to xhigh for deep problems)
# Python (requires openai SDK that supports responses API)from openai import OpenAIclient = OpenAI(api_key="YOUR_OPENAI_API_KEY")resp = client.responses.create( model="gpt-5.2-pro", # gpt-5.2 or gpt-5.2-pro input="Summarize this 50k token company report and output a 10-slide presentation outline with speaker notes.", reasoning={"effort": "xhigh"}, # deeper reasoning max_output_tokens=4000)print(resp.output_text) # or inspect resp to get structured outputs / tokens
Notes: reasoning.effort ให้คุณแลกต้นทุนกับความลึก ใช้ gpt-5.2-chat-latest สำหรับสไตล์ผู้ช่วยแชต เอกสาร OpenAI มีตัวอย่าง responses.create.
GPT-5.2 — curl (simple)
curl https://api.openai.com/v1/responses \ -H "Authorization: Bearer $OPENAI_API_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "gpt-5.2", "input": "Write a Python function that converts a PDF with tables into a normalized CSV with typed columns.", "reasoning": {"effort":"high"} }'
(ตรวจสอบ JSON สำหรับ output_text หรือผลลัพธ์แบบมีโครงสร้าง)
Gemini 3 Pro Preview — Python (Google GenAI client)
# Python (google genai client) — example from Google docsfrom google import genaiclient = genai.Client(api_key="YOUR_GEMINI_API_KEY")response = client.models.generate_content( model="gemini-3-pro-preview", contents="Find the race condition in this multi-threaded C++ snippet: <paste code here>", config={ "thinkingConfig": {"thinking_level": "high"} })print(response.text)
Notes: thinking_level คุมการไตร่ตรองภายในของโมเดล; media_resolution ตั้งค่าได้สำหรับภาพ/วิดีโอ เอกสารของ Google มีตัวอย่าง REST และ JS
Gemini 3 Pro — curl (REST)
curl "https://generativelanguage.googleapis.com/v1beta/models/gemini-3-pro-preview:generateContent" \ -H "x-goog-api-key: $GEMINI_API_KEY" \ -H "Content-Type: application/json" \ -X POST \ -d '{ "contents": [{ "parts": [{"text": "Explain the race condition in this C++ code: ..."}] }], "generationConfig": {"thinkingConfig": {"thinkingLevel": "high"}} }'
เอกสารของ Google มีตัวอย่างมัลติโหมด (ข้อมูลภาพแบบ inline, media_resolution)
Which model is “better” — practical guidance
ไม่มี “ผู้ชนะ” เดียวที่เหมาะกับทุกกรณี; ให้เลือกตาม กรณีใช้งาน และ ข้อจำกัด ของคุณ ด้านล่างคือตารางตัดสินใจสั้น ๆ
Choose GPT-5.2 if:
- คุณต้องการ การผสานแน่นกับเครื่องมือรันโค้ด (ecosystem เครื่องมือ/ล่ามโค้ดของ OpenAI) สำหรับไปป์ไลน์ข้อมูลแบบโปรแกรม สร้างสเปรดชีต หรือเวิร์กโฟลว์โค้ดเชิงตัวแทน OpenAI เน้นการปรับปรุงเครื่องมือ Python และ mega-agent เชิงตัวแทน
- คุณให้ความสำคัญกับ ประสิทธิภาพโทเคน ตามที่ผู้ขายระบุ และอยากได้ราคาต่อโทเคนของ OpenAI ที่คาดการณ์ได้พร้อมส่วนลดก้อนใหญ่สำหรับอินพุตที่แคช (ช่วยเวิร์กโฟลว์แบตช์/โปรดักชัน)
- คุณต้องการระบบนิเวศของ OpenAI (การผนวกผลิตภัณฑ์ ChatGPT พันธมิตร Azure/Microsoft และเครื่องมือรอบ Responses API และ Codex)
Choose Gemini 3 Pro if:
- คุณต้องการ อินพุตมัลติโหมดสุดขั้ว (วิดีโอ + ภาพ + เสียง + pdfs) และอยากใช้โมเดลตัวเดียวที่รองรับทั้งหมดแบบเนทีฟด้วยหน้าต่างอินพุต 1,000,000 โทเคน Google ทำการตลาดชัดเจนสำหรับวิดีโอยาว ไปป์ไลน์เอกสาร+วิดีโอขนาดใหญ่ และเคสโหมด Search/AI แบบโต้ตอบ
- คุณกำลังพัฒนาบน Google Cloud / Vertex AI และอยากได้การผสานแน่นกับการยึดโยงการค้นหา การจัดสรรบน Vertex และ GenAI client APIs จะได้ประโยชน์จากการผนวกผลิตภัณฑ์ Google (Search AI Mode, AI Studio, Antigravity agent tooling)
Conclusion: Which Is Better in 2026?
ในการเปรียบเทียบ GPT-5.2 vs. Gemini 3 Pro Preview คำตอบคือ ขึ้นอยู่กับบริบท:
- GPT-5.2 นำในงานความรู้มืออาชีพ ความลึกเชิงวิเคราะห์ และเวิร์กโฟลว์เชิงโครงสร้าง
- Gemini 3 Pro Preview เด่นในการทำความเข้าใจมัลติโหมด ระบบนิเวศที่ผนวกรวม และงานบริบทยาวมาก
ไม่มีโมเดลไหน “ดีกว่า” แบบสากล — จุดแข็งของทั้งคู่ตอบโจทย์ความต้องการโลกจริงที่ต่างกัน ผู้เลือกใช้อย่างชาญฉลาดควรจับคู่โมเดลกับเคสงานเฉพาะ งบประมาณ และระบบนิเวศที่สอดคล้อง
สิ่งที่ชัดเจนในปี 2026 คือ พรมแดน AI ก้าวหน้าไปไกล และทั้ง GPT-5.2 และ Gemini 3 Pro กำลังผลักขีดความสามารถของระบบอัจฉริยะในภาคองค์กรและไกลยิ่งกว่า
หากอยากลองทันที สำรวจความสามารถของ GPT-5.2 และ Gemini 3 Pro บน CometAPI ใน Playground และอ่านคู่มือ API สำหรับคำแนะนำละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบว่าคุณได้ล็อกอิน CometAPI และรับ API key แล้ว CometAPI มีราคาต่ำกว่าราคาทางการมากเพื่อช่วยคุณอินทิเกรต
Ready to Go?→ ทดลองใช้ฟรีของ GPT-5.2 และ Gemini 3 Pro !
If you want to