

OpenAI เผยแพร่ผลการวิจัยตัวอย่าง การป้องกัน gpt-ossตระกูลโมเดลอนุมานน้ำหนักเปิดที่ออกแบบมาเพื่อให้ผู้พัฒนาบังคับใช้ ของตัวเอง นโยบายความปลอดภัยในช่วงเวลาอนุมาน แทนที่จะส่งตัวจำแนกแบบคงที่หรือกลไกควบคุมแบบกล่องดำ โมเดลใหม่นี้ได้รับการปรับแต่งให้เหมาะสม เหตุผลจากนโยบายที่นักพัฒนาจัดทำ, ปล่อยห่วงโซ่ความคิด (CoT) เพื่ออธิบายเหตุผลของพวกเขา และผลิตผลลัพธ์การจำแนกประเภทที่มีโครงสร้าง gpt-oss-safeguard ซึ่งประกาศไว้เป็นตัวอย่างงานวิจัย นำเสนอในรูปแบบคู่ของแบบจำลองการให้เหตุผล—gpt-oss-safeguard-120b และ gpt-oss-safeguard-20b—ปรับแต่งจากตระกูล gpt-oss และได้รับการออกแบบมาโดยเฉพาะเพื่อดำเนินการจำแนกประเภทความปลอดภัยและบังคับใช้ตามนโยบายในระหว่างการอนุมาน
gpt-oss-safeguard คืออะไร?
gpt-oss-safeguard เป็นโมเดลการให้เหตุผลแบบข้อความอย่างเดียวที่มีน้ำหนักเปิดคู่หนึ่งที่ได้รับการฝึกอบรมภายหลังจากตระกูล gpt-oss ตีความนโยบายที่เขียนด้วยภาษาธรรมชาติและระบุข้อความตามนโยบายนั้น. จุดเด่นคือนโยบายดังกล่าว ให้ไว้ ณ เวลาอนุมาน (นโยบายเป็นอินพุต) ไม่ได้รวมอยู่ในน้ำหนักตัวจำแนกแบบคงที่ แบบจำลองเหล่านี้ได้รับการออกแบบมาสำหรับงานจำแนกประเภทความปลอดภัยเป็นหลัก เช่น การควบคุมนโยบายหลายรายการ การจำแนกเนื้อหาภายใต้กฎระเบียบหลายฉบับ หรือการตรวจสอบการปฏิบัติตามนโยบาย
ทำไมเรื่องนี้
ระบบการกลั่นกรองแบบดั้งเดิมมักอาศัย (ก) ชุดกฎคงที่ที่แมปกับตัวจำแนกประเภทที่ฝึกฝนจากตัวอย่างที่มีป้ายกำกับ หรือ (ข) ฮิวริสติกส์/นิพจน์ทั่วไปสำหรับการตรวจจับคีย์เวิร์ด gpt-oss-safeguard พยายามเปลี่ยนแปลงกระบวนทัศน์: แทนที่จะฝึกอบรมตัวจำแนกประเภทใหม่ทุกครั้งที่มีการเปลี่ยนแปลงนโยบาย คุณจะระบุข้อความนโยบาย (เช่น นโยบายการใช้งานที่ยอมรับได้ของบริษัทคุณ ข้อกำหนดในการให้บริการของแพลตฟอร์ม หรือแนวปฏิบัติของหน่วยงานกำกับดูแล) และให้แบบจำลองให้เหตุผลว่าเนื้อหาชิ้นหนึ่งละเมิดนโยบายนั้นหรือไม่ วิธีนี้รับประกันความคล่องตัว (การเปลี่ยนแปลงนโยบายโดยไม่ต้องฝึกอบรมใหม่) และความสามารถในการตีความ (แบบจำลองจะแสดงลำดับเหตุผลของมันออกมา)
นี่คือปรัชญาหลักของเรา นั่นคือ “แทนที่การท่องจำด้วยเหตุผล และการเดาด้วยคำอธิบาย”
สิ่งนี้แสดงถึงขั้นตอนใหม่ในการรักษาความปลอดภัยเนื้อหา โดยเปลี่ยนจาก "การเรียนรู้กฎอย่างเฉยๆ" ไปเป็น "การทำความเข้าใจกฎอย่างกระตือรือร้น"
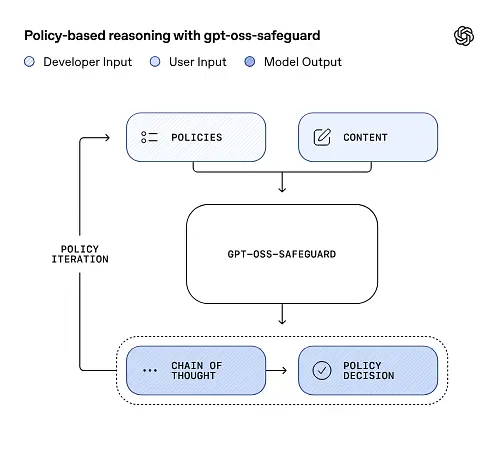
gpt-oss-safeguard สามารถอ่านนโยบายความปลอดภัยที่กำหนดโดยนักพัฒนาได้โดยตรงและปฏิบัติตามนโยบายเหล่านั้นเพื่อตัดสินในระหว่างการอนุมาน
gpt-oss-safeguard ทำงานอย่างไร?
การใช้เหตุผลเชิงนโยบายเป็นอินพุต
ในเวลาอนุมาน คุณให้สองสิ่ง: ข้อความนโยบาย และ เนื้อหาของผู้สมัคร จะต้องติดป้ายกำกับ โมเดลจะถือว่านโยบายเป็นคำสั่งหลัก จากนั้นจึงดำเนินการหาเหตุผลแบบทีละขั้นตอนเพื่อพิจารณาว่าเนื้อหานั้นได้รับอนุญาต ไม่อนุญาต หรือต้องมีขั้นตอนการควบคุมเพิ่มเติม ในการอนุมาน โมเดล:
- สร้างผลลัพธ์ที่มีโครงสร้างซึ่งรวมถึงข้อสรุป (ฉลาก หมวดหมู่ ความเชื่อมั่น) และการติดตามการใช้เหตุผลที่อ่านได้โดยมนุษย์เพื่ออธิบายว่าเหตุใดจึงได้ข้อสรุปดังกล่าว
- รับนโยบายและเนื้อหาที่จะจัดประเภท
- เหตุผลภายในผ่านข้อกำหนดของนโยบายโดยใช้ขั้นตอนแบบลำดับความคิด และ
ตัวอย่างเช่น:
Policy: Content that encourages violence, hate speech, pornography, or fraud is not allowed.
Content: This text describes a fighting game.
มันจะตอบกลับ:
Classification: Safe
Reasoning: The content only describes the game mechanics and does not encourage real violence.
ห่วงโซ่แห่งความคิด (CoT) และผลลัพธ์ที่มีโครงสร้าง
gpt-oss-safeguard สามารถส่งการติดตาม CoT แบบเต็มซึ่งเป็นส่วนหนึ่งของการอนุมานแต่ละครั้ง CoT ได้รับการออกแบบมาให้ตรวจสอบได้ ทีมปฏิบัติตามข้อกำหนดสามารถอ่านสาเหตุที่แบบจำลองได้ข้อสรุป และวิศวกรสามารถใช้การติดตามเพื่อวินิจฉัยความคลุมเครือของนโยบายหรือโหมดความล้มเหลวของแบบจำลอง แบบจำลองนี้ยังรองรับ ผลลัพธ์ที่มีโครงสร้าง—ตัวอย่างเช่น JSON ที่มีคำตัดสิน ส่วนนโยบายที่ละเมิด คะแนนความรุนแรง และแนวทางแก้ไขที่แนะนำ — ทำให้สามารถรวมเข้าในกระบวนการควบคุมดูแลได้โดยตรง
ระดับ “ความพยายามในการใช้เหตุผล” ที่ปรับได้
เพื่อสร้างสมดุลระหว่างเวลาแฝง ต้นทุน และความละเอียดถี่ถ้วน โมเดลเหล่านี้จึงรองรับความพยายามในการใช้เหตุผลที่กำหนดค่าได้: ต่ำ / กลาง / สูงความพยายามที่สูงขึ้นจะเพิ่มความลึกของห่วงโซ่ความคิด และโดยทั่วไปแล้วจะให้ผลลัพธ์การอนุมานที่แข็งแกร่งขึ้น แต่ช้ากว่าและมีค่าใช้จ่ายสูงกว่า วิธีนี้ช่วยให้นักพัฒนาสามารถแบ่งระดับเวิร์กโหลดได้ โดยใช้ความพยายามต่ำสำหรับเนื้อหาทั่วไป และใช้ความพยายามสูงสำหรับกรณีพิเศษหรือเนื้อหาที่มีความเสี่ยงสูง
โครงสร้างโมเดลเป็นอย่างไร และมีเวอร์ชันใดบ้าง?
ครอบครัวต้นแบบและสายตระกูล
gpt-oss-safeguard คือ หลังการฝึกอบรม ตัวแปรของ OpenAI รุ่นก่อนๆ จีพีที-ออส รุ่นเปิด ปัจจุบันตระกูล Safeguard มีสองขนาดที่วางจำหน่าย:
- gpt-oss-safeguard-120b — โมเดลพารามิเตอร์ 120 พันล้านที่ออกแบบมาสำหรับงานการใช้เหตุผลที่มีความแม่นยำสูงซึ่งยังคงทำงานบน GPU 80GB ตัวเดียวในรันไทม์ที่ได้รับการปรับให้เหมาะสม
- gpt-oss-safeguard-20b — โมเดลพารามิเตอร์ 20 พันล้านตัวที่ปรับให้เหมาะสมสำหรับการอนุมานต้นทุนต่ำและสภาพแวดล้อมแบบ edge หรือภายในองค์กร (สามารถทำงานบนอุปกรณ์ VRAM ขนาด 16GB ได้ในบางการกำหนดค่า)
หมายเหตุสถาปัตยกรรมและคุณลักษณะของรันไทม์ (สิ่งที่คาดหวัง)
- พารามิเตอร์ที่ใช้งานต่อโทเค็น: สถาปัตยกรรม gpt-oss ที่เป็นพื้นฐานใช้เทคนิคที่ลดจำนวนพารามิเตอร์ที่เปิดใช้งานต่อโทเค็น (การผสมผสานระหว่างการออกแบบสไตล์ความสนใจหนาแน่นและเบาบาง / ส่วนผสมของผู้เชี่ยวชาญใน gpt-oss หลัก)
- ในทางปฏิบัติ คลาส 120B จะพอดีกับตัวเร่งความเร็วขนาดใหญ่ตัวเดียว ส่วนคลาส 20B ได้รับการออกแบบมาให้ทำงานบนการตั้งค่า VRAM ขนาด 16GB ในรันไทม์ที่ได้รับการปรับให้เหมาะสม
แบบจำลองการป้องกันคือ ไม่ได้รับการฝึกอบรมด้วยข้อมูลทางชีวภาพหรือความปลอดภัยทางไซเบอร์เพิ่มเติมและการวิเคราะห์สถานการณ์การใช้งานในทางที่ผิดที่เลวร้ายที่สุดที่ดำเนินการสำหรับรุ่น gpt-oss นั้น ใช้กับตัวแปรการป้องกันได้คร่าวๆ แบบจำลองเหล่านี้มีไว้สำหรับการจำแนกประเภทมากกว่าการสร้างเนื้อหาสำหรับผู้ใช้ปลายทาง
วัตถุประสงค์ของ gpt-oss-safeguard คืออะไร
เป้าหมาย
- ความยืดหยุ่นของนโยบาย: ปล่อยให้ผู้พัฒนากำหนดนโยบายใดๆ ในภาษาธรรมชาติและให้โมเดลใช้โดยไม่ต้องมีการรวบรวมป้ายกำกับแบบกำหนดเอง
- อธิบายได้: เปิดเผยเหตุผลเพื่อให้สามารถตรวจสอบการตัดสินใจและกำหนดนโยบายซ้ำได้
- อินเทอร์เน็ต: จัดให้มีทางเลือกน้ำหนักแบบเปิดเพื่อให้องค์กรสามารถรันการใช้เหตุผลด้านความปลอดภัยภายในเครื่องและตรวจสอบส่วนประกอบภายในของโมเดลได้
การเปรียบเทียบกับตัวจำแนกแบบคลาสสิก
ข้อดีเมื่อเทียบกับตัวจำแนกแบบดั้งเดิม
- ไม่มีการฝึกอบรมใหม่สำหรับการเปลี่ยนแปลงนโยบาย: หากนโยบายการดูแลของคุณมีการเปลี่ยนแปลง โปรดอัปเดตเอกสารนโยบายแทนที่จะรวบรวมป้ายกำกับและฝึกอบรมตัวจำแนกใหม่
- การให้เหตุผลที่สมบูรณ์ยิ่งขึ้น: ผลลัพธ์ของ CoT สามารถเปิดเผยปฏิสัมพันธ์นโยบายที่ละเอียดอ่อนและให้เหตุผลเชิงบรรยายที่เป็นประโยชน์ต่อผู้ตรวจสอบมนุษย์
- การปรับแต่ง: โมเดลเดียวสามารถใช้หลักเกณฑ์ที่แตกต่างกันหลายข้อได้พร้อมๆ กันในระหว่างการอนุมาน
ข้อเสียเทียบกับตัวจำแนกแบบดั้งเดิม
- เพดานประสิทธิภาพสำหรับบางงาน: บันทึกการประเมินของ OpenAI ระบุว่า ตัวจำแนกคุณภาพสูงที่ฝึกฝนจากตัวอย่างที่มีป้ายกำกับนับหมื่นตัวสามารถทำงานได้ดีกว่า gpt-oss-safeguard สำหรับงานจำแนกประเภทเฉพาะทาง เมื่อเป้าหมายคือความแม่นยำในการจำแนกประเภทแบบดิบ และคุณมีข้อมูลที่มีป้ายกำกับแล้ว การใช้ตัวจำแนกประเภทเฉพาะที่ฝึกฝนการแจกแจงนั้นอาจมีประสิทธิภาพดีกว่า
- ความหน่วงและต้นทุน: การใช้เหตุผลด้วย CoT ต้องใช้การประมวลผลจำนวนมากและช้ากว่าตัวจำแนกประเภทน้ำหนักเบา ซึ่งอาจทำให้ท่อส่งข้อมูลที่เน้นการป้องกันล้วนๆ มีราคาแพงเมื่อใช้งานในระดับขนาดใหญ่
โดยสรุป: gpt-oss-safeguard ใช้ได้ดีที่สุดเมื่อ ความคล่องตัวของนโยบายและความสามารถในการตรวจสอบ มีความสำคัญหรือเมื่อข้อมูลที่มีป้ายกำกับมีไม่เพียงพอ และเป็นส่วนประกอบเสริมในระบบไฮบริด ไม่จำเป็นต้องใช้แทนตัวจำแนกประเภทที่ปรับให้เหมาะสมกับมาตราส่วน
gpt-oss-safeguard มีประสิทธิภาพอย่างไรในการประเมินของ OpenAI
OpenAI เผยแพร่ผลลัพธ์พื้นฐานในรายงานทางเทคนิค 10 หน้า ซึ่งสรุปการประเมินภายในและภายนอก ประเด็นสำคัญ (เมตริกที่เลือกและเมตริกรับน้ำหนัก):
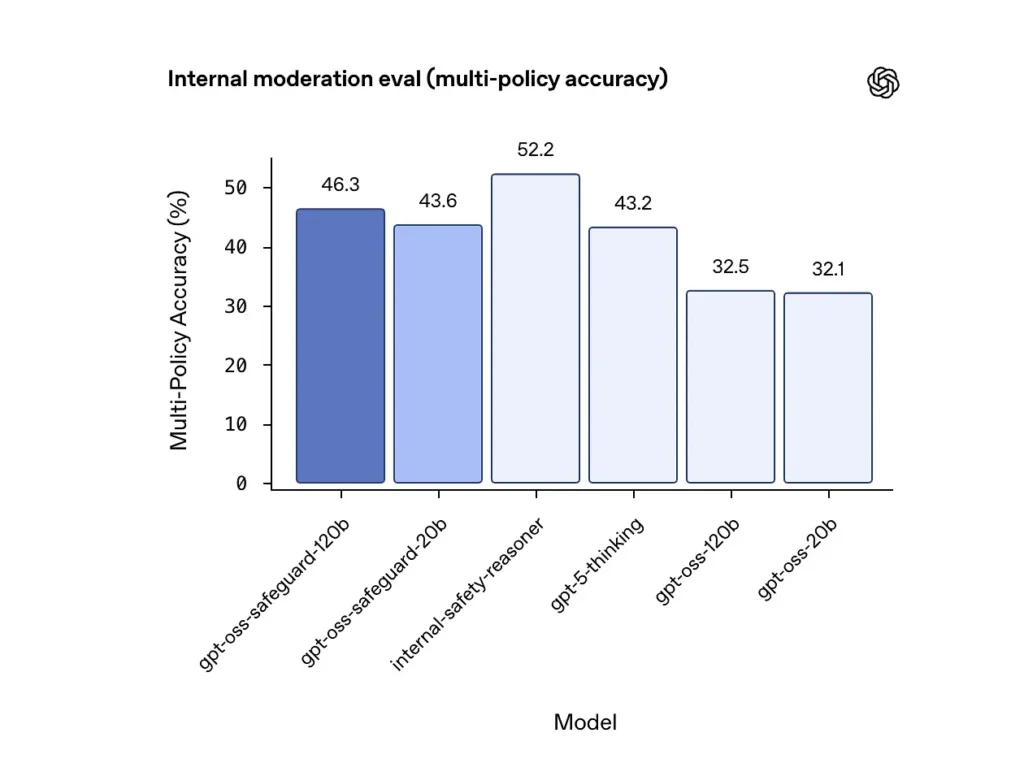
ความแม่นยำของนโยบายหลายฉบับ (การประเมินภายใน)
OpenAI ประเมินความแม่นยำของนโยบายหลายข้อโดยให้แบบจำลอง หลาย นโยบายพร้อมกันและนับคำทำนายว่าถูกต้องเฉพาะในกรณีที่ตรงกับป้ายสีทองเท่านั้น ทั้งหมด นโยบาย ผลลัพธ์:
- gpt-oss-safeguard-120b: 46.3% ความแม่นยำของนโยบายหลายฉบับ
- gpt-oss-safeguard-20b: 43.6%
- สำหรับการเปรียบเทียบ: gpt-5-ความคิด: 43.2%; จีพีที-ออส-120บี: 32.5%; จีพีที-ออส-20บี: 32.1%
ชุดข้อมูล “เหตุผลด้านความปลอดภัย” ภายในของ OpenAI ได้คะแนน 52.2% ในการทดสอบเดียวกัน ตัวเลขเหล่านี้แสดงให้เห็นว่าโมเดลการป้องกันมีประสิทธิภาพเหนือกว่าโมเดลฐาน gpt-oss อย่างมากในงานที่มีนโยบายหลายฉบับ และยังสูงกว่าค่าพื้นฐานการคิดแบบ gpt-5 ที่ใหญ่กว่าในเมตริกแบบหลายนโยบายภายในอีกด้วย
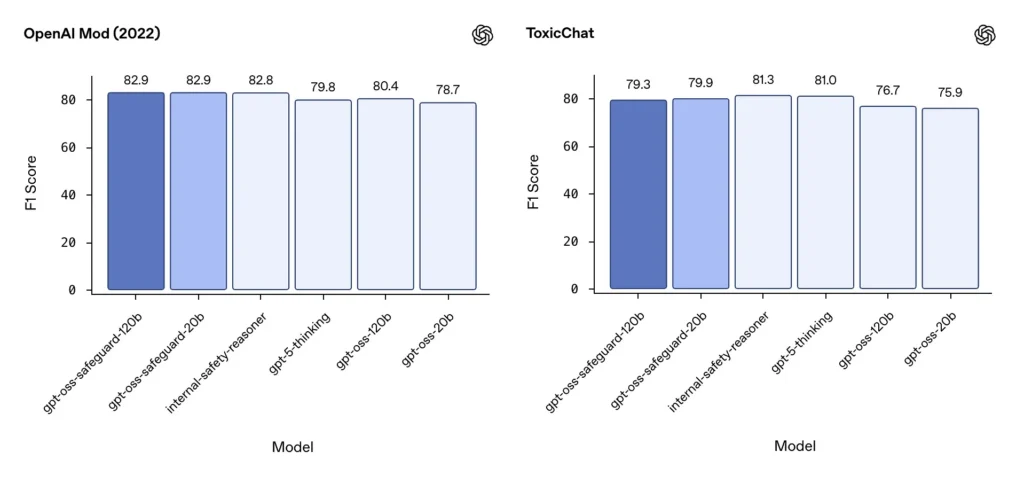
การควบคุมดูแล F1 (เกณฑ์มาตรฐานภายนอก)
จากชุดข้อมูลการควบคุมดูแลปี 2022 ของ OpenAI และเกณฑ์มาตรฐาน ToxicChat สาธารณะ โมเดล gpt-oss-safeguard สามารถทำคะแนน F1 ได้มั่นคง:
- ม็อด OpenAI (2022) F1: gpt-oss-safeguard-120b = 82.9%, gpt-oss-safeguard-20b = 82.9%
- พิษแชท F1: gpt-oss-safeguard-120b = 79.3%, gpt-oss-safeguard-20b = 79.9%
คะแนนเหล่านี้ทำให้ gpt-oss-safeguard อยู่ใกล้เคียงหรือตามหลังระบบภายใน OpenAI เฉพาะทางเล็กน้อยในเกณฑ์มาตรฐานบางรายการ และโดยทั่วไปแล้วจะอยู่เหนือระบบ gpt-oss ที่ไม่ได้ปรับแต่งมากนัก
ข้อจำกัดที่สังเกตได้
OpenAI ระบุข้อจำกัดในทางปฏิบัติสองประการ:
- ตัวจำแนกประเภทที่ฝึกอบรมบนชุดข้อมูลที่มีป้ายกำกับเฉพาะงานขนาดใหญ่ยังคงมีประสิทธิภาพเหนือกว่าโมเดลการป้องกัน เมื่อความแม่นยำในการจำแนกเป็นเป้าหมายเพียงอย่างเดียว
- ต้นทุนการคำนวณและความหน่วง: การใช้เหตุผลแบบ CoT จะเพิ่มเวลาในการอนุมานและการใช้การคำนวณ ซึ่งทำให้การปรับขนาดให้เข้ากับปริมาณการรับส่งข้อมูลในระดับแพลตฟอร์มมีความซับซ้อน เว้นแต่จะจับคู่กับตัวจำแนกประเภทและไปป์ไลน์แบบอะซิงโครนัส
ความเท่าเทียมกันในหลายภาษา
gpt-oss-safeguard ทำงานได้เท่าเทียมกับโมเดล gpt-oss ที่เป็นพื้นฐานในหลายภาษาในการทดสอบสไตล์ MMMLU ซึ่งบ่งชี้ว่าตัวแปรการป้องกันที่ปรับแต่งอย่างละเอียดยังคงความสามารถในการใช้เหตุผลแบบกว้าง
ทีมงานสามารถเข้าถึงและใช้งาน gpt-oss-safeguard ได้อย่างไร
OpenAI ระบุน้ำหนักภายใต้ Apache 2.0 และเชื่อมโยงโมเดลสำหรับการดาวน์โหลด (Hugging Face) เนื่องจาก gpt-oss-safeguard เป็นโมเดลน้ำหนักแบบเปิด การปรับใช้แบบโลคัลและแบบจัดการด้วยตนเอง (แนะนำสำหรับความเป็นส่วนตัวและการปรับแต่ง)
- ดาวน์โหลดแบบจำลองน้ำหนัก (จาก OpenAI / Hugging Face) และโฮสต์ไว้บนเซิร์ฟเวอร์หรือ VM บนคลาวด์ของคุณเอง Apache 2.0 อนุญาตให้ปรับเปลี่ยนและใช้งานเชิงพาณิชย์ได้
- Runtime:ใช้รันไทม์อนุมานมาตรฐานที่รองรับโมเดลทรานส์ฟอร์เมอร์ขนาดใหญ่ (ONNX Runtime, Triton หรือรันไทม์ของผู้จำหน่ายที่ได้รับการปรับให้เหมาะสม) รันไทม์ของชุมชน เช่น Ollama และ LM Studio กำลังเพิ่มการรองรับสำหรับตระกูล gpt-oss แล้ว
- ฮาร์ดแวร์:โดยทั่วไปแล้ว 120B จำเป็นต้องใช้ GPU ที่มีหน่วยความจำสูง (เช่น A100/H100 ขนาด 80GB หรือการแบ่งส่วนข้อมูลแบบหลาย GPU) ในขณะที่ 20B สามารถใช้งานได้ในราคาที่ถูกกว่าและมีตัวเลือกที่ได้รับการปรับแต่งให้เหมาะสมกับการตั้งค่า VRAM ขนาด 16GB วางแผนความจุสำหรับปริมาณงานสูงสุดและต้นทุนการประเมินแบบหลายนโยบาย
รันไทม์ที่ได้รับการจัดการและโดยบุคคลที่สาม
หากการใช้งานฮาร์ดแวร์ของคุณเองไม่สะดวก โคเมทเอพีไอ กำลังเพิ่มการรองรับโมเดล gpt-oss อย่างรวดเร็ว แพลตฟอร์มเหล่านี้อาจช่วยให้ปรับขนาดได้ง่ายขึ้น แต่กลับต้องกลับมาพิจารณาถึงความเสี่ยงจากการเปิดเผยข้อมูลของบุคคลที่สามอีกครั้ง ควรประเมินความเป็นส่วนตัว SLA และการควบคุมการเข้าถึงก่อนเลือกใช้รันไทม์ที่มีการจัดการ
กลยุทธ์การควบคุมที่มีประสิทธิภาพด้วย gpt-oss-safeguard
1) ใช้กระบวนการแบบผสมผสาน (การคัดแยก → เหตุผล → ตัดสิน)
- ชั้นการคัดแยก: ตัวจำแนกประเภท (หรือกฎ) ขนาดเล็กและรวดเร็วจะกรองกรณีเล็กๆ น้อยๆ ออกไป ซึ่งจะช่วยลดภาระของโมเดลการป้องกันที่มีราคาแพง
- ชั้นการป้องกัน: เรียกใช้ gpt-oss-safeguard สำหรับการตรวจสอบที่คลุมเครือ ความเสี่ยงสูง หรือหลายนโยบายที่ความแตกต่างของนโยบายมีความสำคัญ
- การตัดสินของมนุษย์: ยกระดับกรณีขอบและการอุทธรณ์ โดยจัดเก็บ CoT ไว้เป็นหลักฐานเพื่อความโปร่งใส การออกแบบแบบไฮบริดนี้สร้างสมดุลระหว่างปริมาณงานและความแม่นยำ
2) วิศวกรรมนโยบาย (ไม่ใช่วิศวกรรมเร่งด่วน)
- ปฏิบัติต่อนโยบายเหมือนกับเป็นสิ่งประดิษฐ์ของซอฟต์แวร์: กำหนดเวอร์ชัน ทดสอบกับชุดข้อมูล และรักษาให้ชัดเจนและมีลำดับชั้น
- เขียนนโยบายพร้อมตัวอย่างและตัวอย่างที่โต้แย้ง หากเป็นไปได้ ให้ระบุคำแนะนำที่คลุมเครือ (เช่น “หากเจตนาของผู้ใช้เป็นการสำรวจและในอดีตอย่างชัดเจน ให้ระบุเป็น X หากเจตนาเป็นการดำเนินการจริงและแบบเรียลไทม์ ให้ระบุเป็น Y”)
3) กำหนดค่าความพยายามในการใช้เหตุผลแบบไดนามิก
- ใช้ ความพยายามต่ำ สำหรับการแปรรูปจำนวนมากและ ความพยายามสูง สำหรับเนื้อหาที่ถูกทำเครื่องหมาย การอุทธรณ์ หรือเนื้อหาที่มีผลกระทบสูง (กฎหมาย การแพทย์ การเงิน)
- ปรับแต่งเกณฑ์ด้วยคำติชมจากการตรวจสอบโดยมนุษย์เพื่อค้นหาจุดที่เหมาะสมระหว่างต้นทุนและคุณภาพ
4) ตรวจสอบ CoT และสังเกตการใช้เหตุผลแบบประสาทหลอน
CoT มีค่า แต่ก็อาจก่อให้เกิดภาพหลอนได้ ร่องรอยคือเหตุผลที่สร้างจากแบบจำลอง ไม่ใช่ความจริงพื้นฐาน การตรวจสอบ CoT จะแสดงผลลัพธ์ออกมาอย่างสม่ำเสมอ เครื่องมือที่ใช้ตรวจสอบคือการอ้างอิงภาพหลอนหรือการให้เหตุผลที่ไม่ตรงกัน OpenAI บันทึกห่วงโซ่ความคิดภาพหลอนว่าเป็นความท้าทายที่สังเกตได้ และเสนอแนะกลยุทธ์บรรเทาผลกระทบ
5) สร้างชุดข้อมูลจากการทำงานของระบบ
การตัดสินใจของแบบจำลองบันทึกและการแก้ไขโดยมนุษย์เพื่อสร้างชุดข้อมูลที่มีป้ายกำกับ ซึ่งสามารถปรับปรุงตัวจำแนกประเภทแบบแบ่งแยก หรือแจ้งการเขียนนโยบายใหม่ เมื่อเวลาผ่านไป ชุดข้อมูลที่มีป้ายกำกับขนาดเล็กแต่คุณภาพสูง บวกกับตัวจำแนกประเภทที่มีประสิทธิภาพ มักจะลดการพึ่งพาการอนุมาน CoT เต็มรูปแบบสำหรับเนื้อหาแบบรูทีน
6) ตรวจสอบการคำนวณและต้นทุน ใช้การไหลแบบอะซิงโครนัส
สำหรับแอปพลิเคชันที่ตอบสนองความต้องการของผู้บริโภคที่ต้องการความหน่วงต่ำ ควรพิจารณาการตรวจสอบความปลอดภัยแบบอะซิงโครนัสด้วย UX แบบอนุรักษ์นิยมระยะสั้น (เช่น ซ่อนเนื้อหาไว้ชั่วคราวเพื่อรอการตรวจสอบ) แทนที่จะดำเนินการ CoT แบบใช้ความพยายามสูงแบบซิงโครนัส OpenAI ระบุว่า Safety Reasoner ใช้โฟลว์แบบอะซิงโครนัสภายในเพื่อจัดการความหน่วงสำหรับบริการที่ใช้งานจริง
7) พิจารณาความเป็นส่วนตัวและตำแหน่งการใช้งาน
เนื่องจากน้ำหนักเปิดอยู่ คุณจึงสามารถรันการอนุมานภายในสถานที่ทั้งหมดได้เพื่อให้เป็นไปตามการกำกับดูแลข้อมูลที่เข้มงวดหรือลดการเปิดเผยต่อ API ของบุคคลที่สาม ซึ่งมีประโยชน์สำหรับอุตสาหกรรมที่มีการควบคุม
สรุป:
gpt-oss-safeguard เป็นเครื่องมือที่ใช้งานได้จริง โปร่งใส และยืดหยุ่นสำหรับ การใช้เหตุผลด้านความปลอดภัยตามนโยบาย. มันเปล่งประกายเมื่อคุณต้องการ การตัดสินใจที่ตรวจสอบได้ซึ่งเชื่อมโยงกับนโยบายที่ชัดเจนเมื่อนโยบายของคุณเปลี่ยนแปลงบ่อยครั้ง หรือเมื่อคุณต้องการตรวจสอบความปลอดภัยภายในสถานที่ ไม่ กระสุนเงินที่จะมาแทนที่ตัวจำแนกเฉพาะทางที่มีปริมาณมากโดยอัตโนมัติ การประเมินของ OpenAI เองแสดงให้เห็นว่าตัวจำแนกเฉพาะทางที่ฝึกฝนบนคอร์ปัสขนาดใหญ่ที่มีป้ายกำกับ สามารถทำผลงานได้ดีกว่าโมเดลเหล่านี้ในด้านความแม่นยำดิบสำหรับงานที่จำกัด ให้ถือว่า gpt-oss-safeguard เป็นองค์ประกอบเชิงกลยุทธ์: กลไกการให้เหตุผลเชิงอธิบายที่เป็นหัวใจสำคัญของสถาปัตยกรรมความปลอดภัยแบบหลายชั้น (การคัดกรองอย่างรวดเร็ว → การใช้เหตุผลเชิงอธิบาย → การกำกับดูแลโดยมนุษย์)
เริ่มต้นใช้งาน
CometAPI เป็นแพลตฟอร์ม API แบบรวมที่รวบรวมโมเดล AI มากกว่า 500 โมเดลจากผู้ให้บริการชั้นนำ เช่น ซีรีส์ GPT ของ OpenAI, Gemini ของ Google, Claude ของ Anthropic, Midjourney, Suno และอื่นๆ ไว้ในอินเทอร์เฟซเดียวที่เป็นมิตรกับนักพัฒนา ด้วยการนำเสนอการตรวจสอบสิทธิ์ การจัดรูปแบบคำขอ และการจัดการการตอบสนองที่สอดคล้องกัน CometAPI จึงทำให้การรวมความสามารถของ AI เข้ากับแอปพลิเคชันของคุณง่ายขึ้นอย่างมาก ไม่ว่าคุณจะกำลังสร้างแชทบ็อต เครื่องกำเนิดภาพ นักแต่งเพลง หรือไพพ์ไลน์การวิเคราะห์ที่ขับเคลื่อนด้วยข้อมูล CometAPI ช่วยให้คุณทำซ้ำได้เร็วขึ้น ควบคุมต้นทุน และไม่ขึ้นอยู่กับผู้จำหน่าย ทั้งหมดนี้ในขณะที่ใช้ประโยชน์จากความก้าวหน้าล่าสุดในระบบนิเวศ AI
การรวม gpt-oss-safeguard ล่าสุดจะปรากฏบน CometAPI เร็วๆ นี้ โปรดติดตาม! ในขณะที่เรากำลังสรุปการอัปโหลดโมเดล gpt-oss-safeguard นักพัฒนาสามารถเข้าถึงได้ API GPT-OSS-20B และ API GPT-OSS-120B ผ่านทาง CometAPI รุ่นใหม่ล่าสุด ได้รับการอัปเดตอยู่เสมอจากเว็บไซต์อย่างเป็นทางการ เริ่มต้นด้วยการสำรวจความสามารถของโมเดลใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว โคเมทเอพีไอ เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยคุณบูรณาการ
พร้อมไปหรือยัง?→ ลงทะเบียน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม โปรดติดตามเราที่ VK, X และ ไม่ลงรอยกัน!