

xAI เปิดตัวอย่างเงียบๆ กร็อก 4.1 (17–18 พฤศจิกายน 2025) — การอัปเกรดที่เน้นไปที่ Grok 4 ที่ให้ความสำคัญกับ สติปัญญาทางอารมณ์ การแสดงออกเชิงสร้างสรรค์ และอาการประสาทหลอนที่ลดลง โดยยังคงรักษาเหตุผลอันเฉียบคมของ Grok รุ่นก่อนๆ ไว้ มาพร้อมสองโหมด (คิด / ไม่คิด) เปิดตัวอย่างเงียบๆ ในช่วงต้นเดือนพฤศจิกายน แสดงผลคะแนนนำบนกระดานผู้นำสูงสุดบน LMArena และดาวน์โหลดได้ทาง grok.com แอป Grok และ API
Grok 4.1 คืออะไร?
Grok 4.1 คือ Grok 4 ที่เน้นการผลิตแบบค่อยเป็นค่อยไป ถือเป็นรุ่นต่อยอดจาก Grok 4 ซึ่งประกอบด้วยสมาชิกในตระกูลเดียวกันที่พัฒนาบนรากฐานการเรียนรู้แบบเสริมแรงขนาดใหญ่เดียวกัน แต่ได้รับการปรับแต่งและฝึกฝนใหม่ด้วยการปรับปรุงหลังการฝึกอบรมอย่างหนักหน่วง โดยมุ่งเน้นที่รูปแบบ บุคลิกภาพ ความสอดคล้อง และความน่าเชื่อถือในโลกแห่งความเป็นจริง Grok 4.1 ถูกวางตำแหน่งให้เป็นก้าวไปข้างหน้าที่ “ใช้งานได้จริง” และ “ชาญฉลาดขึ้น” ในแบบทดสอบความชอบส่วนบุคคลแบบปิดตา มีความฉลาดทางอารมณ์มากขึ้น เขียนเชิงสร้างสรรค์ได้ดีขึ้น และมีแนวโน้มน้อยลงที่จะเกิด “ภาพหลอน” ที่มั่นใจแต่ผิดพลาด ซึ่งเป็นปัญหาที่มักเกิดขึ้นกับผู้สำเร็จการศึกษาระดับปริญญาโทสาขานิติศาสตร์ (LLM) ระดับสูงรุ่นก่อนๆ
Grok 4.1 บรรลุการเปลี่ยนแปลงเชิงคุณภาพในสี่มิติต่อไปนี้:
- ความคิดสร้างสรรค์: แสดงให้เห็นถึงรูปแบบภาษาที่แข็งแกร่งและจินตนาการในการเขียน การเล่าเรื่อง และบริบททางสังคม
- สติปัญญาทางอารมณ์: จดจำน้ำเสียงและการเปลี่ยนแปลงทางอารมณ์ ตอบสนองด้วยตรรกะทางอารมณ์ที่คล้ายกับมนุษย์มากขึ้น และสร้างการตอบสนองที่สบายใจและเข้าใจ
- ความสอดคล้องของบุคลิกภาพ: รักษาโทนเสียงและบุคลิกภาพให้สม่ำเสมอในบทสนทนาที่ยาวนาน ไม่แสดงพฤติกรรมที่ไม่สม่ำเสมอของรุ่นก่อนหน้าอีกต่อไป
- ความร่วมมือ: รักษาความสอดคล้องและการรับรู้เป้าหมายในการสนทนาหลายรอบหรือการทำงานร่วมกันในงาน
xAI สรุปลักษณะเฉพาะของมันไว้ในประโยคเดียวว่า “มันมีการรับรู้มากกว่า เห็นอกเห็นใจมากกว่า และมีความสอดคล้องกับบุคคลมากขึ้น”
Grok 4.1 ทำงานอย่างไรภายใต้ประทุน?
Grok 4.1 เข้าใจได้ดีที่สุดว่าเป็นโครงสร้างหลักที่ได้รับการฝึกอบรมไว้ล่วงหน้าแบบเดียวกับที่ใช้ในตระกูล Grok 4 บวกกับไปป์ไลน์หลังการฝึกอบรมแบบหลายชั้นที่เน้นที่ การสร้างแบบจำลองรางวัล การจัดแนวสไตล์ และการประเมินตัวแทน.
ขั้นตอนการฝึกและการจัดแนวมีอะไรบ้าง?
Grok 4.1 ทำงานบนระบบท่อส่งหลายขั้นตอนแบบฉบับของ LLM แนวหน้าสมัยใหม่ โดยได้รับการปรับให้เข้ากับการเปลี่ยนแปลงสำคัญสองประการสำหรับ 4.1:
- ก่อนการฝึกอบรม + ระหว่างการฝึกอบรม: การฝึกอบรมเบื้องต้นเกี่ยวกับข้อมูลเว็บขนาดใหญ่ + การฝึกอบรมระดับกลางที่มุ่งเป้าหมายเพื่อเพิ่มพูนความรู้เกี่ยวกับโดเมนและความสามารถแบบมัลติโหมด
- การปรับแต่งอย่างละเอียดภายใต้การดูแล (SFT): การสาธิตพฤติกรรมที่ต้องการของมนุษย์ (การตอบกลับ กลยุทธ์การปฏิเสธ)
- การสร้างแบบจำลองรางวัล (การประยุกต์ใช้ใหม่): xAI ฝึกฝนโมเดลรางวัลไม่เพียงแต่ตามฉลากความชอบของมนุษย์เท่านั้น แต่ยังใช้ แบบจำลองการใช้เหตุผลเชิงตัวแทนแนวชายแดน ในฐานะผู้ให้คะแนนรางวัล — ช่วยให้ผู้ประเมินที่มีความสามารถสูงซึ่งใช้แบบจำลองสามารถให้คะแนนผลลัพธ์ของผู้สมัครได้อย่างมีประสิทธิภาพในระดับขนาดใหญ่ ซึ่งช่วยให้สามารถเพิ่มประสิทธิภาพคุณลักษณะที่ไม่สามารถตรวจสอบได้ เช่น สไตล์ ความสอดคล้องของบุคลิกภาพ ความเห็นอกเห็นใจ และความช่วยเหลือ โดยไม่จำเป็นต้องทุ่มงบประมาณในการติดฉลากโดยมนุษย์จำนวนมากจนเป็นไปไม่ได้
- การเพิ่มประสิทธิภาพนโยบาย (RLHF / RL จากรางวัลแบบจำลอง): การเพิ่มประสิทธิภาพนโยบายมาตรฐานโดยใช้สัญญาณรางวัลที่เรียนรู้เพื่อสร้างนโยบายที่นำไปใช้งาน (โมเดลที่ผู้บริโภคโต้ตอบด้วย)
แนวทางการสร้างแบบจำลองรางวัลมีอะไรใหม่?
ใน RLHF แบบดั้งเดิม คุณจะรวบรวมป้ายกำกับความชอบของมนุษย์ (A/B) ฝึกแบบจำลองรางวัลเพื่อคาดการณ์ป้ายกำกับเหล่านั้น แล้วจึงปรับแต่งแบบจำลองพื้นฐานด้วย RL (หรือการสุ่มตัวอย่างแบบปฏิเสธ) เทียบกับรางวัลที่เรียนรู้แล้ว แต่ xAI เน้นย้ำถึงนวัตกรรมเชิงปฏิบัติสองประการ:
- รูปแบบการให้รางวัลตัวแทน: แทนที่จะใช้ผู้ตัดสินที่เป็นมนุษย์ล้วนๆ xAI ได้ใช้แบบจำลองการให้เหตุผลแบบ "ตัวแทน" ที่มีประสิทธิภาพเป็นตัวให้คะแนน เพื่อประเมินคุณสมบัติที่ละเอียดอ่อนกว่า (น้ำเสียง ความแตกต่างทางอารมณ์ และความคิดสร้างสรรค์) ผู้ให้คะแนนสามารถเปรียบเทียบแบบคู่กันหลายพันครั้งได้อย่างรวดเร็ว ช่วยให้วิศวกรสามารถทำซ้ำได้เร็วขึ้น นี่คือกลไกสำหรับการพัฒนาที่สำคัญในด้านรูปแบบและสติปัญญาทางอารมณ์
- การจัดตำแหน่งหลังการฝึกอบรมสำหรับสัญญาณที่ไม่สามารถตรวจสอบได้: สำหรับคุณลักษณะที่คุณไม่สามารถวัดด้วยตัวชี้วัดแบบกำหนดได้ (เช่น "ความอบอุ่น" หรือ "บุคลิกภาพที่สอดคล้องกัน") พวกเขาได้นำวัตถุประสงค์รางวัลเฉพาะทางและหลักสูตรการปรับขนาดมาใช้เพื่อให้แบบจำลองเรียนรู้ สไตล์ ของผลลัพธ์โดยไม่ต้องเสียสละความถูกต้องของข้อเท็จจริงหลัก
“การคิด” กับ “การไม่คิด” ทำงานทางเทคนิคอย่างไร?
- Grok 4.1 การคิด (ชื่อรหัส
quasarflux) — เปิดเผยขั้นตอนการให้เหตุผลอย่างชัดเจน (โทเค็นการคิด) ก่อนที่จะสร้างคำตอบสุดท้าย ปรับให้เหมาะสมสำหรับงานที่ซับซ้อนและ Elo ที่สูงขึ้นใน LMArena โทเค็นเพิ่มเติมนี้ใช้เวลาในการอนุมาน แต่ช่วยในการทำงานให้เหตุผลหลายขั้นตอน การดีบัก และการอธิบาย - Grok 4.1 ไม่คิด (ชื่อรหัส
tensor) ข้ามโทเค็นตัวกลางที่ชัดเจนเพื่อให้ได้การตอบสนองขั้นสุดท้ายเพียงครั้งเดียวและทันที วิธีนี้ช่วยลดความหน่วงและต้นทุนโทเค็น ในขณะที่ยังคงได้รับประโยชน์จากน้ำหนักนโยบายที่ปรับแต่งอย่างเท่าเดิม โหมดที่ไม่ต้องคิดได้รับการปรับแต่งให้มีความหน่วงต่ำมากแต่ยังคงมีประสิทธิภาพสูง
การเพิ่มประสิทธิภาพการจัดตำแหน่งของความรู้สึกและรูปแบบ
นอกเหนือจากสัญญาณ "ความจริง" ง่ายๆ แล้ว Grok 4.1 ยังรวมถึงการปรับปรุงการจัดวางตำแหน่งที่ตรงเป้าหมายสำหรับความรู้สึก น้ำเสียง และสไตล์ความสัมพันธ์ระหว่างบุคคล ซึ่งหมายความว่ากระบวนการฝึกอบรมประกอบด้วยองค์ประกอบการให้รางวัลหรือการสูญเสียที่ลงโทษน้ำเสียงที่ไม่ตรงกันอย่างชัดเจน (เช่น การห้วนๆ โดยไม่จำเป็นเมื่อเห็นอกเห็นใจอย่างเหมาะสม) และให้รางวัลการตอบสนองที่ตรงกับสไตล์หรือโปรไฟล์ความรู้สึกที่ต้องการ ใน Grok 4.1 AI ได้นำเสนอวัตถุประสงค์ในการปรับปรุงตำแหน่ง "การจัดวางตำแหน่งบุคลิกภาพ" เป็นครั้งแรก
มีวัตถุประสงค์เพื่อช่วยให้แบบจำลองรักษาอัตลักษณ์ที่สอดคล้องและมั่นคง เมื่อเทียบกับ Grok 4 แล้ว 4.1 ได้เพิ่มสิ่งต่อไปนี้ลงในวัตถุประสงค์การฝึกอบรม:
- รางวัลเชิงบวกสำหรับมิติการแสดงออกทางอารมณ์ (รางวัลการจัดแนวอารมณ์)
- ตัวชี้วัดความสอดคล้องของบุคลิกภาพ
Grok 4.1 ได้รับการประเมินอย่างไร และมีประสิทธิภาพเป็นอย่างไร?
การทดสอบความชอบของมนุษย์แบบตาบอดแสดงให้เห็นอะไร?
ในระหว่างการเปิดตัวแบบเงียบ Grok 4.1 ได้รับความนิยมถึง 64.78% เมื่อเทียบกับโมเดลการผลิตแบบเดิมในปริมาณการใช้งานสด ซึ่งเป็นสัญญาณการชื่นชอบของมนุษย์ที่ชัดเจน ซึ่งบ่งชี้ถึงผลลัพธ์การสนทนาที่ดีกว่าในธรรมชาติ
Grok 4.1 อยู่ในอันดับต้น ๆ ของกระดานผู้นำหรือไม่?
xAI รายงานว่า Grok 4.1 คิด โหมดนั่งอยู่ที่ อันดับ 1 บน Text Arena ของ LMArena, มีรายงาน Elo ของ 1483และโหมดที่ไม่ต้องใช้เหตุผล (รวดเร็ว) อยู่ในอันดับ 2 ด้วย 1465 Elo — มีอันดับบนกระดานผู้นำสาธารณะที่แข็งแกร่งทั้งในด้านความแม่นยำและการนำเสนอ (การควบคุมสไตล์มีบทบาท)
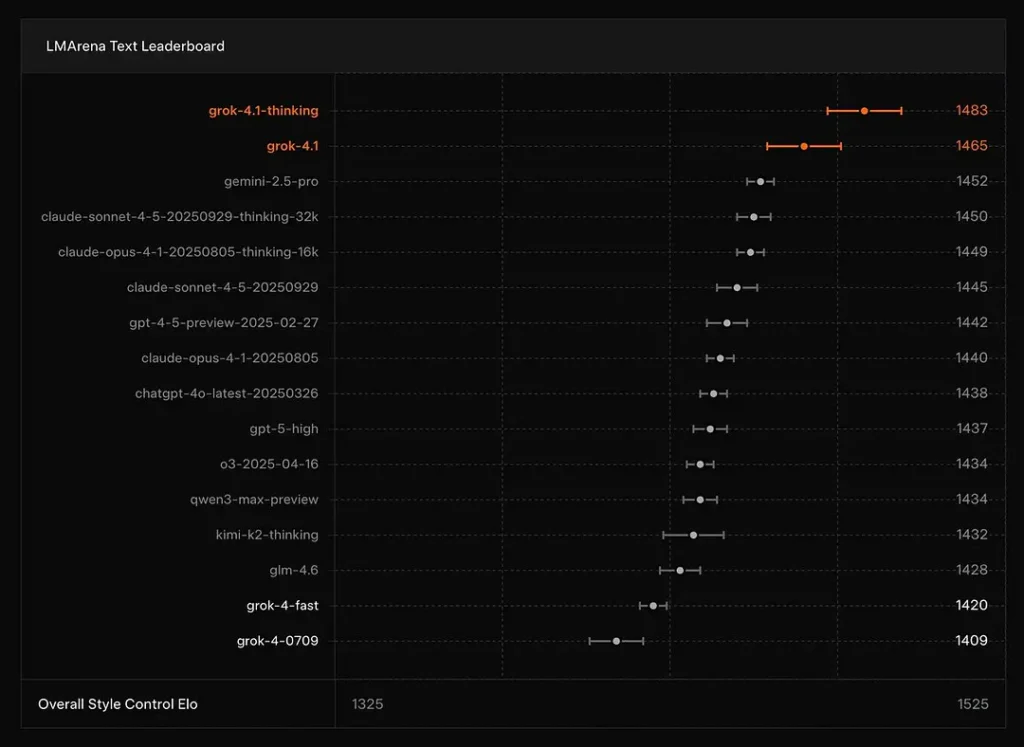
บทสรุป: Grok 4.1 เหนือกว่าโมเดลซีรีส์ GPT-4.5 และ Claude หลักในด้านการทำความเข้าใจข้อความ การสร้าง และคุณภาพโดยรวม เป็นรองเพียงเวอร์ชัน GPT-5 Advanced Preview เท่านั้น
ความฉลาดทางอารมณ์
xAI ได้ทดสอบ EQ-Bench3 ซึ่งเป็นการทดสอบเฉพาะทางสำหรับสติปัญญาทางอารมณ์ ครอบคลุมสถานการณ์สมมติที่ท้าทาย 45 สถานการณ์ และรายงานว่า Grok 4.1 แสดงให้เห็นถึงความก้าวหน้าอย่างมากในด้านความเห็นอกเห็นใจ จังหวะ และความเข้าใจระหว่างบุคคล Grok 4.1 ได้คะแนนสูงสุดในการทำความเข้าใจบริบทของความเศร้า ความเห็นอกเห็นใจ และความสะดวกสบาย

การเขียนเชิงสร้างสรรค์ — จริงหรือว่ามันต้องใช้จินตนาการมากกว่า?
Grok 4.1 ได้รับการประเมินแล้ว การเขียนเชิงสร้างสรรค์ v3 (32 คำสั่งใน 3 รอบการวนซ้ำพร้อมเกณฑ์การให้คะแนน + Elo) xAI ระบุว่ารูปแบบการเขียน ความสม่ำเสมอของเสียง และความคิดสร้างสรรค์ในการเล่าเรื่องของเวอร์ชัน 4.1 เพิ่มขึ้นอย่างมาก ทำให้เวอร์ชันนี้อยู่ในอันดับต้นๆ ของตารางคะแนนด้านความคิดสร้างสรรค์ล่าสุด (มีตัวอย่างคำสั่งรวมอยู่ในเวอร์ชันนี้) รายงานอิสระสะท้อนถึงผลการวิจัยเหล่านี้: ผู้ตรวจสอบเห็นถึง "เสียงที่โดดเด่น" มากขึ้นอย่างเห็นได้ชัดและความสอดคล้องของเนื้อหาแบบยาวที่ดีขึ้น ในด้านคุณภาพการเขียน Grok 4.1 เป็นรองเพียงรุ่นซีรีส์ GPT-5 และเหนือกว่าผลิตภัณฑ์ทั้งหมดของ Claude, Gemini และ Kimi

ลดอาการประสาทหลอน / ความซื่อสัตย์
xAI อ้างว่าอัตราการประสาทหลอนลดลงอย่างเห็นได้ชัด โดยรายงาน (ในประกาศและโพสต์โซเชียล) ว่า Grok 4.1 คือ ~มีโอกาสเกิดภาพหลอนน้อยลง 3 เท่า เมื่อเทียบกับโมเดล Grok รุ่นก่อนๆ โดยอ้างอิงการวิเคราะห์ปริมาณการผลิตและการประเมินแบบ FActScore (เช่น ชุดคำถามเกี่ยวกับชีวประวัติ ยิ่งน้อยยิ่งดี) โดยเฉพาะอย่างยิ่งใน "โหมดไม่ใช้เหตุผล" ซึ่งมีเครื่องมือค้นหาภายนอก ความสอดคล้องของข้อเท็จจริงจะมีเสถียรภาพมากขึ้น

เหตุใด Grok 4.1 จึง "บดขยี้" โมเดลอื่นๆ — นั่นเป็นการพูดเกินจริงใช่หรือไม่?
“Crushes” นั้นเป็นแนวคิดทางการตลาด แต่มีข้ออ้างที่เป็นรูปธรรมอยู่เบื้องหลังข้ออ้างดังกล่าว:
- ลีดเดอร์บอร์ด: Grok 4.1 ครองตำแหน่งสูงสุดบนกระดานผู้นำ LMArena สาธารณะสำหรับการสร้างข้อความ (1483 Elo สำหรับโหมดคิด) และการแสดงที่แข็งแกร่งในด้านความคิดสร้างสรรค์และ EQ-bench ตามการเปิดตัวของ xAI สิ่งเหล่านี้เป็นตัวชี้วัดการแข่งขันแบบเปรียบเทียบกันซึ่งใช้กันทั่วทั้งชุมชน
- ความชอบด้านปริมาณการเข้าชมจริงชนะ: xAI รายงานความพึงพอใจของมนุษย์ที่ชนะในการเปรียบเทียบแบบปิดตา (ความพึงพอใจ ~65% เมื่อเทียบกับรุ่นก่อนหน้า) จากการเปิดตัวแบบเงียบๆ บนทราฟฟิกสด ซึ่งสะท้อนถึงการพัฒนาของผู้ใช้จริง ไม่ใช่แค่เกณฑ์มาตรฐานบนกระดาษ
- ความสามารถใหม่ในทางปฏิบัติ: การรวมกันของตัวให้คะแนนแบบจำลอง RL บนสัญญาณที่ไม่สามารถตรวจสอบได้ และตัวกรองอินพุตที่เข้มงวดยิ่งขึ้น ถือเป็นขั้นตอนทางวิศวกรรมเชิงปฏิบัติที่ช่วยปรับปรุงประสบการณ์ของผู้ใช้โดยตรงในงานสนทนา งานแสดงความเห็นอกเห็นใจ และงานสร้างสรรค์ ซึ่งโดยทั่วไปแล้ว คู่แข่งมักจะทำผลงานได้ต่ำกว่า
ดังนั้น แม้ว่าคำว่า "หลงใหล" จะเป็นวิธีที่น่าสนใจในการพูดว่า "เป็นผู้นำในการประเมินสาธารณะและภายในหลายรายการ" แต่ตัวชี้วัดสาธารณะพื้นฐานที่ xAI เผยแพร่กลับสรุปว่า
วิธีการเข้าถึง Grok 4.1
การเข้าถึงผู้บริโภค/แอป
xAI ได้เปิดให้เข้าถึง Grok 4.1 ได้เป็นระยะๆ ในโหมด "อัตโนมัติ" ฟรีหรือเป็นหน้าต่างโปรโมต แต่ยังมีระดับพรีเมียม (SuperGrok, SuperGrok Heavy) และการเข้าถึง API พร้อมโควตาที่สูงกว่าและยังคงมีให้บริการในรูปแบบที่ต้องชำระเงิน
Grok 4.1 พร้อมใช้งานสำหรับผู้ใช้ทุกคน on grok.com, **เอ็กซ์ (ชื่อเดิม ทวิตเตอร์)**และแอป Grok สำหรับ iOS และ Android เปิดตัวทันทีในโหมดอัตโนมัติ พร้อมเลือกได้อย่างชัดเจนว่าเป็น "Grok 4.1" ในตัวเลือกโมเดล
การเข้าถึง API และแผนสำหรับนักพัฒนา
จุดสิ้นสุด Grok 4.1 พร้อมใช้งานผ่าน xAI API ณ วันที่เผยแพร่บทความนี้ ยังไม่มีการเผยแพร่ GPT 4.1 API อย่างเป็นทางการ
โคเมทเอพีไอ สัญญาว่าจะติดตามการเปลี่ยนแปลงของโมเดลล่าสุดรวมทั้ง Grok4.1 API ภาษาไทยซึ่งจะเปิดตัวพร้อมกับการเปิดตัวอย่างเป็นทางการ โปรดตั้งตารอและติดตาม CometAPI ต่อไป ระหว่างรอ คุณสามารถติดตามรุ่นอื่นๆ ของ Grok ได้ เช่น Grok-code-fast-1 และ กร็อก 4สำรวจความสามารถต่างๆ ได้ใน Playground และดูคู่มือ API สำหรับคำแนะนำโดยละเอียดในการโทร ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว
เคล็ดลับการใช้งาน Grok 4.1 ในระบบการผลิต
วิธีลดความเสี่ยงของอาการประสาทหลอน
- เปิดใช้งานการค้นหาสด หรือเครื่องมือที่ผ่านการตรวจสอบสำหรับการสอบถามข้อมูล
- ให้ขั้นตอนการตรวจสอบ: ขอให้โมเดลส่งคืนแหล่งที่มาและหลักฐานสำหรับการอ้างข้อเท็จจริง ใช้
responseเมตาดาต้าเพื่อตรวจสอบการอ้างอิง (ถ้ามี) - ดำเนินการตรวจสอบแบบกำหนดแน่นอน (การตรวจสอบข้อเท็จจริง LLM, ผู้ตรวจสอบข้อมูลที่มีโครงสร้าง) เป็นขั้นตอนหลังการประมวลผลสำหรับผลลัพธ์ที่มีความสำคัญสูง
วิธีการควบคุมโทนและสไตล์
- ใช้คำเตือนระบบที่ชัดเจนเพื่อแก้ไขเสียง ("คุณเป็นทางการและเห็นอกเห็นใจ")
- ใช้คำแนะนำที่ได้รับการดูแลและเทมเพลตท้องถิ่นขนาดเล็กเพื่อให้เสียงมีความสอดคล้องกันในทุกแอปพลิเคชัน
- เมื่อใช้ได้แล้ว ให้ใช้ประโยชน์จากตัวเลือกการควบคุมสไตล์ของ xAI และปุ่มบังคับเลี้ยวแบบให้รางวัล
คำตัดสินสุดท้าย: Grok 4.1 เป็นการเปลี่ยนแปลงครั้งใหญ่หรือไม่?
Grok 4.1 คือ ไม่ สถาปัตยกรรมใหม่เอี่ยม แต่เป็นสถาปัตยกรรมที่ซับซ้อนและพิถีพิถัน หลังการฝึกอบรม / การจัดแนว การเปิดตัวที่เน้นไปที่สิ่งที่มนุษย์สนใจจริงๆ ในแชท: บุคลิกภาพ สติปัญญาทางอารมณ์ ความคิดสร้างสรรค์ และข้อผิดพลาดเชิงข้อเท็จจริงน้อยลง. ประโยชน์ที่วัดได้บนกระดานผู้นำ การตั้งค่าปริมาณการใช้งานจริงขนาดใหญ่ และเครื่องมือด้านความปลอดภัยที่ได้รับการปรับปรุง สำหรับแอปพลิเคชันที่ต้องอาศัยการสนทนาคุณภาพสูง การทำงานร่วมกันอย่างสร้างสรรค์ หรือการช่วยเหลือที่คำนึงถึงโทนเสียง Grok 4.1 ถือเป็นก้าวสำคัญ และจากผลการทดสอบประสิทธิภาพหลายรายการในชุมชน ถือเป็นตัวที่มีประสิทธิภาพสูงสุด ณ เวลาที่เปิดตัว
CometAPI คือแพลตฟอร์มรวม API เชิงพาณิชย์ที่ช่วยให้นักพัฒนาสามารถเข้าถึง REST แบบรวมศูนย์สไตล์ OpenAI เข้าถึงโมเดล AI หลายร้อยโมเดลจากหลากหลายผู้ให้บริการ ไม่ว่าจะเป็น LLM แบบข้อความ โปรแกรมสร้างภาพ/วิดีโอ การฝัง และอื่นๆ ผ่านอินเทอร์เฟซเดียวที่สอดคล้องกัน แทนที่จะต้องเชื่อมต่อ SDK แยกต่างหากหรือจุดสิ้นสุดเฉพาะสำหรับ OpenAI, Anthropic, Google, Meta หรือผู้ให้บริการโมเดลเฉพาะทางขนาดเล็ก CometAPI ช่วยให้คุณเรียกใช้โมเดลต่างๆ ได้โดยการเปลี่ยนสตริงโมเดลและพารามิเตอร์เพียงไม่กี่ตัว
พร้อมที่จะลองหรือยัง?→ ลงทะเบียน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม โปรดติดตามเราที่ VK, X และ ไม่ลงรอยกัน!