

GLM-5 เป็นแบบจำลองฐานแบบ open-weight รุ่นใหม่ของ Zhipu AI ที่เน้นเอเจนต์เป็นศูนย์กลาง พัฒนาสำหรับการเขียนโค้ดระยะยาวและเอเจนต์หลายขั้นตอน มีให้ใช้งานผ่าน API แบบโฮสต์หลายช่องทาง (รวมถึง CometAPI และ provider endpoints) และในรูปแบบเผยแพร่งานวิจัยพร้อมโค้ดและน้ำหนักโมเดล; คุณสามารถผสานรวมได้ด้วยการเรียก REST ที่เข้ากันได้กับ OpenAI มาตรฐาน, การสตรีมมิง, และ SDK
GLM-5 จาก Z.ai คืออะไร?
GLM-5 เป็นแบบจำลองฐานเรือธงรุ่นที่ห้าของ Z.ai ออกแบบเพื่อ agentic engineering: การวางแผนระยะยาว การใช้เครื่องมือหลายขั้นตอน และการออกแบบโค้ด/ระบบขนาดใหญ่ เผยแพร่สาธารณะในเดือนกุมภาพันธ์ 2026 GLM-5 เป็นแบบจำลอง Mixture-of-Experts (MoE) ที่มีพารามิเตอร์รวมประมาณ ~744 พันล้าน และชุดพารามิเตอร์ที่ใช้งานอยู่ในช่วง 40B ต่อการคำนวณ forward แต่ละครั้ง; สถาปัตยกรรมและแนวทางการฝึกให้ความสำคัญกับความสอดคล้องของบริบทยาว การเรียกใช้เครื่องมือ และการอนุมานที่คุ้มต้นทุนสำหรับงานระดับโปรดักชัน ทางเลือกด้านการออกแบบเหล่านี้ทำให้ GLM-5 สามารถดำเนินเวิร์กโฟลว์แบบ agentic ที่ยาวขึ้น (เช่น browse → plan → write/test code → iterate) โดยยังคงรักษาบริบทไว้แม้กับอินพุตที่ยาวมาก
ไฮไลท์ทางเทคนิคที่สำคัญ:
- สถาปัตยกรรม MoE ที่พารามิเตอร์รวมประมาณ ~744B / พารามิเตอร์ที่ใช้งาน ~40B; การพรีเทรนแบบสเกลใหญ่ (รายงาน ~28.5T tokens) เพื่อลดช่องว่างกับโมเดลปิดระดับแนวหน้า
- รองรับบริบทยาวและการปรับแต่งประสิทธิภาพ (deep sparse attention, DSA) เพื่อลดต้นทุนการใช้งานเทียบกับการสเกลแบบ dense ตรงไปตรงมา
- มีฟีเจอร์แบบ agentic ในตัว: การเรียกใช้เครื่องมือ/ฟังก์ชัน การรองรับเซสชันแบบมีสถานะ และเอาต์พุตแบบบูรณาการ (สามารถสร้างไฟล์
.docx,.xlsx,.pdfเป็นส่วนหนึ่งของเวิร์กโฟลว์เอเจนต์ใน UI ของผู้ให้บริการ) - มีน้ำหนักแบบเปิดให้ใช้ (เผยแพร่น้ำหนักไปยัง model hubs) และตัวเลือกการเข้าถึงแบบโฮสต์ (API ของผู้ให้บริการ, inference microservices)
ข้อดีหลักของ GLM-5 คืออะไร?
การวางแผนแบบ agentic และความจำระยะยาว
สถาปัตยกรรมและการปรับจูนของ GLM-5 ให้ความสำคัญกับการให้เหตุผลหลายขั้นตอนที่สม่ำเสมอและความจำข้ามเวิร์กโฟลว์ ซึ่งเป็นประโยชน์สำหรับ:
- เอเจนต์อัตโนมัติ (CI pipelines, task orchestrators),
- การสร้างโค้ดหรือรีแฟกเตอร์หลายไฟล์ขนาดใหญ่, และ
- งานด้านเอกสารอัจฉริยะที่ต้องเก็บประวัติขนาดใหญ่
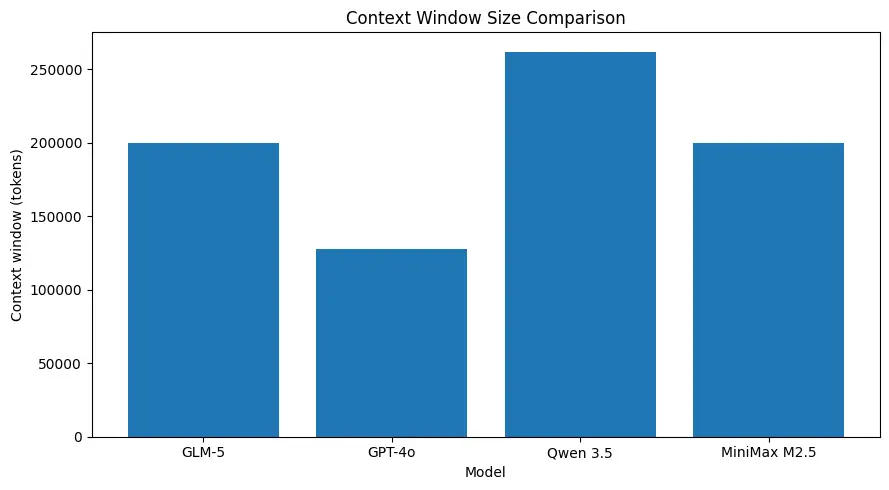
หน้าต่างบริบทขนาดใหญ่
GLM-5 รองรับบริบทที่มีขนาดใหญ่มาก (ราว ~200k tokens ตามสเปคที่เผยแพร่) ทำให้คุณสามารถเก็บเนื้อหาของเซสชันไว้ในคำขอเดียวมากขึ้น และลดความจำเป็นในการตัดแบ่งอย่างหนักหรือใช้หน่วยความจำภายนอกสำหรับหลายกรณีใช้งาน (ดูตารางเปรียบเทียบด้านล่าง)
ประสิทธิภาพการเขียนโค้ดที่แข็งแกร่งสำหรับงานระดับระบบ
GLM-5 รายงานประสิทธิภาพชั้นนำในโอเพนซอร์สบนชุดวัดวิศวกรรมซอฟต์แวร์ (SWE-bench และชุดทดสอบโค้ด+เอเจนต์ที่ใช้งานจริง) บน SWE-bench-Verified รายงานประมาณ ~77.8%; บนการทดสอบเอเจนต์แบบโค้ด/เทอร์มินัล (Terminal-Bench 2.0) คะแนนอยู่ช่วงกลาง 50—สะท้อนความสามารถเชิงปฏิบัติในการเขียนโค้ดที่เข้าใกล้โมเดลเชิงพาณิชย์ระดับแนวหน้า เมตริกเหล่านี้หมายความว่า GLM-5 เหมาะกับงานอย่างการสร้างโค้ด รีแฟกเตอร์อัตโนมัติ การให้เหตุผลข้ามหลายไฟล์ และผู้ช่วย CI/CD
การแลกเปลี่ยนระหว่างต้นทุน/ประสิทธิภาพ
เนื่องจาก GLM-5 ใช้ MoE และนวัตกรรม attention แบบ “sparse” จึงมุ่งลดต้นทุนการอนุมานต่อหน่วยความสามารถเมื่อเทียบกับการสเกลแบบ dense ด้วยแรงหนุน CometAPI มีระดับราคาที่แข่งขันได้ ทำให้ GLM-5 น่าสนใจสำหรับเวิร์กโหลดเอเจนต์ที่มีปริมาณงานสูง
ฉันจะใช้ API ของ GLM-5 ผ่าน CometAPI ได้อย่างไร?
คำตอบสั้น ๆ: ปฏิบัติกับ CometAPI เสมือนเป็นเกตเวย์ที่เข้ากันได้กับ OpenAI — ตั้งค่า base URL และ API key เลือกโมเดล glm-5 แล้วเรียก endpoint chat/completions CometAPI มีผิว REST แบบ OpenAI (เช่น endpoints /v1/chat/completions) พร้อม SDK และโปรเจ็กต์ตัวอย่างที่ทำให้การย้ายงานง่ายมาก
ด้านล่างคือคู่มือเชิงปฏิบัติสำหรับงานโปรดักชัน: การยืนยันตัวตน, การเรียกแชตพื้นฐาน, สตรีมมิง, การเรียกฟังก์ชัน/เครื่องมือ, และการจัดการต้นทุน/การตอบกลับ
ขั้นตอนพื้นฐานในการเข้าถึง GLM-5 ผ่าน CometAPI ได้แก่:
- ลงทะเบียนบน CometAPI และรับ API key.
- หา model id ที่ถูกต้องของ GLM-5 ในแคตตาล็อกของ CometAPI (
"glm-5"แล้วแต่รายการ). - ส่งคำขอ POST แบบยืนยันตัวตนไปยัง endpoint chat/completions ของ CometAPI (สไตล์ OpenAI).
รายละเอียดพื้นฐาน (รูปแบบของ CometAPI): แพลตฟอร์มรองรับเส้นทางแบบ OpenAI เช่น https://api.cometapi.com/v1/chat/completions, การยืนยันตัวตนแบบ Bearer, พารามิเตอร์ model, ข้อความ system/user, สตรีมมิง และมีทั้งตัวอย่าง curl/python ในเอกสาร
ตัวอย่าง: Python (requests) เรียกแชตแบบบล็อกกับ GLM-5 อย่างรวดเร็ว
# Python requests example (blocking)import osimport requestsimport jsonCOMET_KEY = os.getenv("COMETAPI_KEY") # store your key securelyURL = "https://api.cometapi.com/v1/chat/completions"payload = { "model": "zhipuai/glm-5", # CometAPI model identifier for GLM-5 "messages": [ {"role": "system", "content": "You are a helpful devops assistant."}, {"role": "user", "content": "Create a bash script to backup /etc daily and keep 30 days."} ], "max_tokens": 800, "temperature": 0.0}headers = { "Authorization": f"Bearer {COMET_KEY}", "Content-Type": "application/json"}resp = requests.post(URL, headers=headers, json=payload, timeout=60)resp.raise_for_status()data = resp.json()print(data["choices"][0]["message"]["content"])
ตัวอย่าง: curl
curl -X POST "https://api.cometapi.com/v1/chat/completions" \ -H "Authorization: Bearer $COMETAPI_KEY" \ -H "Content-Type: application/json" \ -d '{ "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Summarize the following architecture doc..." }], "max_tokens": 600 }'
การตอบกลับแบบสตรีมมิง (รูปแบบเชิงปฏิบัติ)
CometAPI รองรับการสตรีมมิงสไตล์ OpenAI (SSE / แบบ chunked) วิธีง่ายที่สุดใน Python คือระบุ "stream": true และวนอ่านข้อมูลการตอบกลับเมื่อมาถึง สิ่งนี้สำคัญเมื่อคุณต้องการเอาต์พุตบางส่วนแบบหน่วงต่ำ (สร้างผู้ช่วยนักพัฒนาแบบเรียลไทม์, UI แบบสตรีม)
# Streaming (requests)import requests, osurl = "https://api.cometapi.com/v1/chat/completions"headers = {"Authorization": f"Bearer {os.environ['COMETAPI_KEY']}"}payload = { "model": "zhipuai/glm-5", "messages": [{"role":"user","content":"Write a test scaffold for the following function..."}], "stream": True, "temperature": 0.1}with requests.post(url, headers=headers, json=payload, stream=True) as r: r.raise_for_status() for chunk in r.iter_lines(decode_unicode=True): if chunk: # Each line is a JSON chunk (OpenAI-compatible). Parse carefully. print(chunk)
อ้างอิง: เอกสารการสตรีมมิงสไตล์ OpenAI และความเข้ากันได้ของ CometAPI
การเรียกใช้งานฟังก์ชัน/เครื่องมือ (วิธีเรียกเครื่องมือภายนอก)
GLM-5 รองรับรูปแบบการเรียกฟังก์ชันหรือเครื่องมือที่เข้ากันได้กับแนวทางของ OpenAI/ผู้รวมบริการ (เกตเวย์จะส่งผ่านคำเรียกฟังก์ชันแบบมีโครงสร้างในผลลัพธ์ของโมเดล) ตัวอย่างการใช้งาน: ขอให้ GLM-5 เรียกเครื่องมือโลคัล “run_tests”; โมเดลจะส่งคำสั่งแบบมีโครงสร้างซึ่งคุณสามารถแปลงและดำเนินการได้
# Example request fragment (pseudo-JSON){ "model": "zhipuai/glm-5", "messages": [ {"role":"system","content":"You can call the 'run_tests' tool to run unit tests."}, {"role":"user","content":"Run tests for repo X and summarize failures."} ], "functions": [ {"name":"run_tests","description":"Run pytest in the repo root","parameters": {"type":"object", "properties":{"path":{"type":"string"}}}} ], "function_call": "auto"}
เมื่อโมเดลส่ง function_call กลับมา ให้ดำเนินการเครื่องมือบนฝั่งเซิร์ฟเวอร์ แล้วส่งผลลัพธ์เครื่องมือกลับเป็นข้อความที่มีบทบาทเป็น "tool" และดำเนินการสนทนาต่อ รูปแบบนี้ช่วยให้เรียกใช้เครื่องมือได้อย่างปลอดภัยและรักษาสถานะของเอเจนต์ ดูเอกสารและตัวอย่างของ CometAPI สำหรับตัวช่วย SDK ที่เป็นรูปธรรม
พารามิเตอร์และการปรับจูนเชิงปฏิบัติ
function_call: ใช้เพื่อเปิดการเรียกใช้เครื่องมือแบบมีโครงสร้างและโฟลว์การทำงานที่ปลอดภัยกว่า
temperature: 0–0.3 สำหรับเอาต์พุตระดับระบบที่กำหนดแน่นอน (โค้ด, โครงสร้างพื้นฐาน) สูงขึ้นสำหรับการระดมไอเดีย
max_tokens: ตั้งค่าตามความยาวเอาต์พุตที่คาดไว้; GLM-5 รองรับเอาต์พุตที่ยาวมากเมื่อโฮสต์อยู่ (ข้อจำกัดผู้ให้บริการแตกต่างกัน)
top_p / nucleus sampling: มีประโยชน์ในการจำกัดหางความน่าจะเป็นที่ต่ำ
stream: true สำหรับ UI แบบโต้ตอบ
GLM-5 เทียบกับ Claude Opus ของ Anthropic และโมเดลแนวหน้าตัวอื่นอย่างไร
คำตอบสั้น ๆ: GLM-5 ลดช่องว่างกับโมเดลปิดระดับแนวหน้าในบेंชมาร์กด้าน agentic และการเขียนโค้ด พร้อมทั้งเสนอการปรับใช้แบบ open-weights และมักมีต้นทุนต่อโทเค็นที่ดีกว่าเมื่อโฮสต์โดยผู้รวมบริการ รายละเอียดสำคัญ: บนบेंชมาร์กการโค้ดแบบสัมบูรณ์บางรายการ (SWE-bench, สายพันธุ์ของ Terminal-Bench) Claude Opus ของ Anthropic (4.5/4.6) ยังนำอยู่เล็กน้อยในหลายกระดานจัดอันดับที่เผยแพร่ — แต่ GLM-5 แข่งขันได้สูงและเหนือกว่าหลายโมเดลโอเพนอื่น ๆ
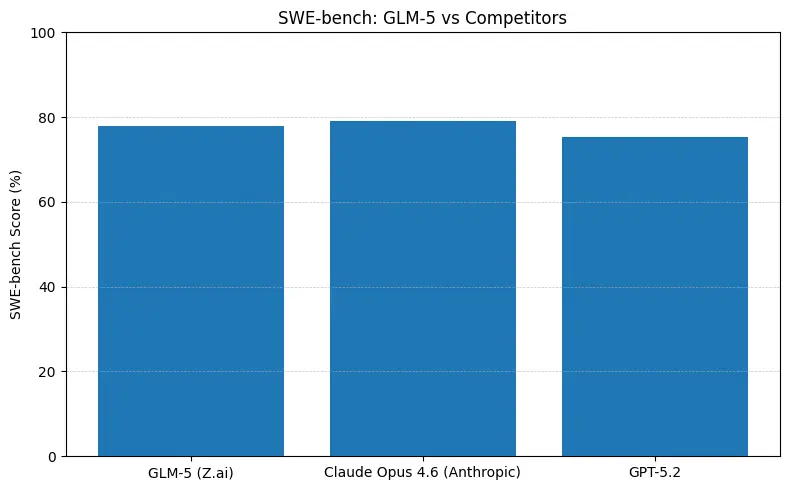
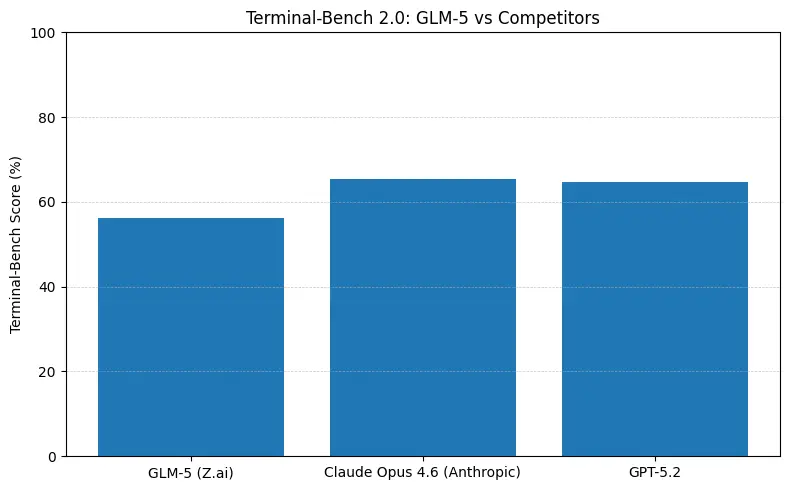
ตัวเลขเหล่านี้หมายถึงอะไรในทางปฏิบัติ
- SWE-bench (~ความถูกต้องของโค้ด / วิศวกรรม): Claude Opus นำเล็กน้อย (≈79% เทียบกับ GLM-5 ≈77.8%) บนกระดานจัดอันดับที่เผยแพร่; สำหรับงานจริงจำนวนมาก ช่องว่างนี้หมายถึงการแก้ไขด้วยมือที่น้อยลง แต่ไม่จำเป็นต้องเปลี่ยนสถาปัตยกรรมสำหรับการสร้างต้นแบบหรือเวิร์กโฟลว์เอเจนต์แบบสเกล
- Terminal-Bench (งานเอเจนต์แบบบรรทัดคำสั่ง): Opus 4.6 นำอยู่ (≈65.4% เทียบกับ GLM-5 ≈56.2%) — หากคุณต้องการระบบอัตโนมัติบนเทอร์มินัลที่แข็งแรงและความเชื่อถือได้สูงสุดกับงานเชลล์ที่อยู่นอกการกระจาย Opus มักดีกว่าเล็กน้อย
- Agentic และระยะยาว: GLM-5 ทำได้ดีมากบนการจำลองธุรกิจระยะยาว (Vending-Bench 2 ยอดคงเหลือ $4,432 ที่รายงาน) และแสดงความสอดคล้องในการวางแผนที่แข็งแรงสำหรับเวิร์กโฟลว์หลายขั้นตอน หากผลิตภัณฑ์ของคุณเป็นเอเจนต์ที่ทำงานยาว (การเงิน, ปฏิบัติการ) GLM-5 แข็งแกร่ง
ฉันจะออกแบบพรอมป์และระบบเพื่อให้ได้ผลลัพธ์ GLM-5 ที่เชื่อถือได้อย่างไร?
ข้อความระบบและข้อกำหนดที่ชัดเจน
กำหนดบทบาทและข้อกำหนดที่เข้มงวดให้ GLM-5 โดยเฉพาะสำหรับงานโค้ดหรือการเรียกเครื่องมือ ตัวอย่าง:
{"role":"system","content":"You are GLM-5, an expert engineer. Return concise, tested Python code that follows PEP8 and includes unit tests."}
ขอให้มีชุดทดสอบและเหตุผลสั้น ๆ สำหรับการเปลี่ยนแปลงที่ไม่เล็กน้อยทุกครั้ง
แยกงานซับซ้อนออกเป็นขั้นตอน
แทนที่จะ “เขียนผลิตภัณฑ์ทั้งชุด” ให้ขอ:
- โครงร่างการออกแบบ,
- ข้อกำหนดอินเทอร์เฟซ,
- การทำให้ใช้งานได้จริงและชุดทดสอบ,
- สคริปต์การผสานรวมสุดท้าย.
ใช้ค่า temperature ต่ำสำหรับโค้ดที่กำหนดแน่นอน
เมื่อขอโค้ด ให้ตั้ง temperature = 0–0.2 และตั้ง max_tokens ให้อยู่ในขอบเขตบนที่ปลอดภัย สำหรับงานเขียนเชิงสร้างสรรค์หรือระดมความคิดด้านการออกแบบ ให้เพิ่มค่า temperature
แนวปฏิบัติที่ดีที่สุดเมื่อผสานรวม GLM-5 (ผ่าน CometAPI หรือโฮสต์โดยตรง)
การออกแบบพรอมป์และพรอมป์ระบบ
- ใช้คำแนะนำ system ที่ชัดเจนเพื่อกำหนดบทบาทของเอเจนต์, นโยบายการเข้าถึงเครื่องมือ, และข้อจำกัดด้านความปลอดภัย ตัวอย่าง: “คุณเป็นสถาปนิกระบบ: เสนอการเปลี่ยนแปลงเฉพาะเมื่อชุดทดสอบผ่านในเครื่อง; ระบุคำสั่ง CLI ที่ต้องรันอย่างแม่นยำ”
- สำหรับงานโค้ด ให้บริบทของคลังซอร์ส (รายชื่อไฟล์, โค้ดสำคัญบางส่วน) และแนบผลลัพธ์ชุดทดสอบหากมี การจัดการบริบทยาวของ GLM-5 ช่วยได้ — แต่ควรใส่บริบทที่จำเป็นก่อน (บทบาท, งาน) แล้วตามด้วยสิ่งประกอบสนับสนุน
การจัดการเซสชันและสถานะ
- ใช้ session ID สำหรับการสนทนาเอเจนต์ระยะยาว และเก็บ “ความทรงจำ” ของขั้นตอนก่อนหน้าแบบย่อ (สรุป) เพื่อป้องกันบริบทบวม CometAPI และเกตเวย์ที่คล้ายกันมีตัวช่วยเซสชัน/สถานะ — แต่การย่อสถานะในระดับแอปพลิเคชันเป็นสิ่งจำเป็นสำหรับเอเจนต์ที่ทำงานยาว
เครื่องมือและการเรียกฟังก์ชัน (ความปลอดภัย + ความเชื่อถือได้)
- เปิดเผยชุดเครื่องมือที่จำกัดและตรวจสอบได้ ห้ามให้รันคำสั่งเชลล์ตามอำเภอใจโดยไม่มีการกำกับดูแลของมนุษย์ ใช้นิยามฟังก์ชันแบบมีโครงสร้างและตรวจสอบอาร์กิวเมนต์ฝั่งเซิร์ฟเวอร์
- บันทึกการเรียกเครื่องมือและการตอบกลับของโมเดลเสมอเพื่อการติดตามและดีบักหลังเหตุการณ์
การควบคุมต้นทุนและการจัดกลุ่มคำขอ
- สำหรับเอเจนต์ปริมาณสูง ให้ส่งงานเบื้องหลังไปยังรุ่นโมเดลที่ถูกกว่าเมื่อการแลกคุณภาพยอมรับได้ (CometAPI ให้สลับโมเดลด้วยชื่อ) จัดกลุ่มคำขอที่คล้ายกันและลด
max_tokensเท่าที่ทำได้ ติดตามสัดส่วนโทเค็นระหว่างอินพุตกับเอาต์พุต — เอาต์พุตโทเค็นมักมีราคาสูงกว่า
การออกแบบด้านความหน่วงและอัตราส่งผ่าน
- ใช้สตรีมมิงสำหรับเซสชันแบบโต้ตอบ สำหรับงานเอเจนต์เบื้องหลัง ให้ใช้รันไทม์แบบอะซิงค์, คิวของเวิร์กเกอร์, และตัวจำกัดอัตรา หากคุณโฮสต์เอง (open weights) ปรับแต่งโทโพโลยีของตัวเร่งให้เหมาะกับสถาปัตยกรรม MoE — ตัวเลือก FPGA / Ascend / ซิลิคอนเฉพาะทางอาจให้ข้อได้เปรียบด้านต้นทุน
หมายเหตุปิดท้าย
GLM-5 เป็นก้าวที่ใช้งานได้จริงในแบบ open-weight สู่ agentic engineering: หน้าต่างบริบทขนาดใหญ่ ความสามารถในการวางแผน และประสิทธิภาพโค้ดที่แข็งแกร่งทำให้เหมาะกับเครื่องมือสำหรับนักพัฒนา การจัดการเอเจนต์ และระบบอัตโนมัติระดับระบบ ใช้ CometAPI เพื่อผสานรวมอย่างรวดเร็วหรือใช้ cloud model garden สำหรับการโฮสต์แบบจัดการ; ตรวจสอบความถูกต้องกับเวิร์กโหลดของคุณและติดตั้งเครื่องมือกำกับอย่างเต็มที่เพื่อควบคุมต้นทุนและการหลงประเด็น
นักพัฒนาสามารถเข้าถึง GLM-5 ผ่าน CometAPI ได้แล้ว ตอนเริ่มต้น สำรวจความสามารถของโมเดลใน Playground และดู คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนการเข้าถึง โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับ API key แล้ว CometAPI เสนอราคาที่ต่ำกว่าราคาทางการมากเพื่อช่วยให้คุณผสานรวม
พร้อมใช้งานแล้วหรือยัง?→ ลงทะเบียน M2.5 วันนี้ !
หากคุณต้องการเคล็ดลับ คู่มือ และข่าวสารด้าน AI เพิ่มเติม ติดตามเราได้บน VK, X และ Discord!