

Nano Banana Pro — หรือที่รู้จักอย่างเป็นทางการว่า Gemini 3 Pro Image — คือโมเดลสร้างและแก้ไขภาพระดับสตูดิโอตัวใหม่ของ Google/DeepMind ที่ผสานการให้เหตุผลแบบมัลติโหมดขั้นสูง การเรนเดอร์ข้อความในภาพที่คมชัด การผสานหลายภาพเข้าด้วยกัน และการควบคุมงานสร้างสรรค์ระดับสตูดิโอ
Nano Banana Pro คืออะไร และทำไมคุณควรสนใจ?
Nano Banana Pro คือโมเดลสร้างภาพและแก้ไขภาพรุ่นใหม่ล่าสุดของ Google — รุ่น “Gemini 3 Pro Image” — ที่ออกแบบมาเพื่อสร้างภาพและข้อความบนภาพที่มีความคมชัดสูง เข้าใจบริบท และมีคุณภาพระดับสตูดิโอได้สูงสุดถึง 4K เป็นรุ่นต่อจากโมเดล Nano Banana รุ่นก่อนหน้า (Gemini 2.5 Flash Image / “Nano Banana”) โดยมีการให้เหตุผลที่ดีขึ้น การทำ Search grounding (ข้อเท็จจริงจากโลกจริง) การเรนเดอร์ข้อความที่แข็งแกร่งขึ้น และการควบคุมการแก้ไขเฉพาะจุดที่ทรงพลังยิ่งขึ้น โมเดลนี้พร้อมใช้งานภายในแอป Gemini สำหรับผู้ใช้แบบโต้ตอบ และสามารถเข้าถึง Nano Banana Pro ผ่าน Gemini API มาตรฐานได้ โดยคุณเลือกตัวระบุโมเดลที่เฉพาะเจาะจง (gemini-3-pro-image-preview หรือรุ่นเสถียรที่มาแทนในภายหลัง) สำหรับการเข้าถึงแบบโปรแกรมได้
เหตุผลที่สิ่งนี้สำคัญ: Nano Banana Pro ไม่ได้ถูกสร้างมาแค่เพื่อทำภาพสวย ๆ แต่เพื่อ ทำให้ข้อมูลมองเห็นได้ — อินโฟกราฟิก ภาพสรุปที่ขับเคลื่อนด้วยข้อมูล (สภาพอากาศ กีฬา) โปสเตอร์ที่มีข้อความจำนวนมาก ม็อกอัปสินค้า และการผสานหลายภาพเข้าด้วยกัน (รองรับภาพนำเข้าได้สูงสุด 14 ภาพ และคงความสม่ำเสมอของตัวละครได้สูงสุด 5 คน) สำหรับนักออกแบบ ทีมผลิตภัณฑ์ และนักพัฒนา การผสมผสานระหว่างความแม่นยำ ข้อความบนภาพ และการเข้าถึงแบบโปรแกรมได้ เปิดเวิร์กโฟลว์การผลิตที่ก่อนหน้านี้ทำให้เป็นอัตโนมัติได้ยาก
ฟังก์ชันใดบ้างที่เปิดให้ใช้ผ่าน API?
ความสามารถของ API ที่เปิดให้นักพัฒนาใช้งานโดยทั่วไป ได้แก่:
- การสร้างภาพจากข้อความ (Text → Image) (แบบขั้นตอนเดียวหรือแบบหลายขั้นตอนด้วยโฟลว์การจัดองค์ประกอบ “thinking”)
- การแก้ไขภาพ (มาสก์เฉพาะจุด, inpainting, การปรับสไตล์)
- การผสานหลายภาพ (รวมภาพอ้างอิงเข้าด้วยกัน)
- การควบคุมคำขอขั้นสูง: ความละเอียด, อัตราส่วนภาพ, ขั้นตอน post-processing และร่องรอย “composition thought” สำหรับการดีบัก/ตรวจสอบได้ในโหมด preview
นวัตกรรมหลักและฟังก์ชันของ Nano Banana Pro
การให้เหตุผลด้านเนื้อหาที่ชาญฉลาดยิ่งขึ้น
ใช้สแตกการให้เหตุผลของ Gemini 3 Pro เพื่อตีความคำสั่งด้านภาพที่ซับซ้อนหลายขั้นตอน (เช่น “สร้างอินโฟกราฟิก 5 ขั้นตอนจากชุดข้อมูลนี้และเพิ่มคำบรรยายสองภาษา”) API เปิดให้ใช้กลไก “Thinking” ที่สามารถสร้างการทดสอบการจัดองค์ประกอบชั่วคราวเพื่อปรับแต่งผลลัพธ์สุดท้าย
เหตุผลที่สำคัญ: แทนที่จะประมวลผลครั้งเดียวจาก prompt → pixel โมเดลจะทำกระบวนการ “thinking” ภายในเพื่อปรับแต่งการจัดองค์ประกอบ และสามารถเรียกใช้เครื่องมือภายนอกได้ (เช่น Google Search) เพื่อยึดโยงกับข้อเท็จจริง (เช่น ป้ายกำกับแผนภาพที่ถูกต้อง หรือป้ายข้อความที่ถูกต้องตามโลแคล) สิ่งนี้ทำให้ภาพไม่เพียงสวยขึ้น แต่ยังถูกต้องในเชิงความหมายมากขึ้นสำหรับงานอย่างอินโฟกราฟิก แผนภาพ หรือม็อกอัปสินค้า
วิธีทำให้ได้ผล: “Thinking” ของ Nano Banana Pro คือการผ่านกระบวนการให้เหตุผล/จัดองค์ประกอบภายในแบบควบคุมได้ ซึ่งโมเดลจะสร้างภาพขั้นกลางและร่องรอยการให้เหตุผลก่อนสร้างภาพสุดท้าย API เปิดเผยว่าโมเดลอาจสร้างเฟรมชั่วคราวได้สูงสุดสองเฟรม และภาพสุดท้ายคือขั้นตอนสุดท้ายของลำดับนั้น ในงาน production สิ่งนี้ช่วยเรื่องการจัดองค์ประกอบ การวางข้อความ และการตัดสินใจด้านเลย์เอาต์
การเรนเดอร์ข้อความที่แม่นยำยิ่งขึ้น
ปรับปรุงการแสดงข้อความในภาพให้ชัดเจน อ่านออก และตรงตามภาษาอย่างมีนัยสำคัญ (เมนู โปสเตอร์ แผนภาพ) Nano Banana Pro ยกระดับการเรนเดอร์ข้อความในภาพไปอีกขั้น:
- ข้อความในภาพชัดเจน อ่านง่าย และสะกดถูกต้อง
- รองรับการสร้างหลายภาษา (รวมถึงภาษาจีน ญี่ปุ่น เกาหลี อาหรับ ฯลฯ)
- อนุญาตให้ผู้ใช้เขียนย่อหน้ายาวหรือข้อความบรรยายหลายบรรทัดลงในภาพได้โดยตรง
- รองรับการแปลและการปรับให้เข้ากับท้องถิ่นโดยอัตโนมัติ
เหตุผลที่สำคัญ: โดยทั่วไปโมเดลภาพมักมีปัญหาในการเรนเดอร์ข้อความให้อ่านได้และจัดวางได้ดี Nano Banana Pro ถูกปรับให้เหมาะกับการเรนเดอร์ข้อความและการแปลท้องถิ่นอย่างเชื่อถือได้โดยเฉพาะ (เช่น การแปลพร้อมคงเลย์เอาต์ไว้) ซึ่งปลดล็อกกรณีใช้งานเชิงสร้างสรรค์จริง เช่น โปสเตอร์ บรรจุภัณฑ์ หรือโฆษณาหลายภาษา
วิธีทำให้ได้ผล: การปรับปรุงด้านการเรนเดอร์ข้อความมาจากสถาปัตยกรรมมัลติโหมดพื้นฐานและการฝึกด้วยชุดข้อมูลที่เน้นตัวอย่างข้อความในภาพ ร่วมกับชุดประเมินผลเฉพาะทาง (การประเมินโดยมนุษย์และ regression sets) โมเดลเรียนรู้ที่จะจัดแนวรูปร่างของ glyph ฟอนต์ และข้อจำกัดด้านเลย์เอาต์ เพื่อสร้างข้อความที่อ่านได้และแปลตามท้องถิ่นภายในภาพ — แม้ว่าข้อความขนาดเล็กและย่อหน้าที่หนาแน่นมากยังคงมีโอกาสผิดพลาดได้
ความสม่ำเสมอของภาพและความคมชัดที่แข็งแกร่งขึ้น
การควบคุมระดับสตูดิโอ (แสง โฟกัส มุมกล้อง การเกรดสี) และการจัดองค์ประกอบจากหลายภาพ (รองรับภาพอ้างอิงสูงสุด 14 ภาพ พร้อมข้อยืดหยุ่นพิเศษสำหรับตัวแบบมนุษย์หลายคน) ช่วยรักษาความสม่ำเสมอของตัวละคร (คงบุคคล/ตัวละครเดิมไว้ตลอดการแก้ไข) และอัตลักษณ์ของแบรนด์ในสินทรัพย์ที่สร้างขึ้นหลายชิ้น โมเดลรองรับเอาต์พุตแบบเนทีฟที่ 1K/2K/4K
เหตุผลที่สำคัญ: เวิร์กโฟลว์ด้านการตลาดและบันเทิงต้องการตัวละครที่คงเส้นคงวาข้ามช็อตและการแก้ไขต่าง ๆ โมเดลสามารถรักษาความคล้ายได้สูงสุด ห้าคน และผสมภาพอ้างอิงได้สูงสุด 14 ภาพไว้ในองค์ประกอบเดียว พร้อมสร้างจาก Sketch → 3D Render ได้ สิ่งนี้มีประโยชน์สำหรับงานโฆษณา บรรจุภัณฑ์ หรือการเล่าเรื่องหลายช็อต
วิธีทำให้ได้ผล: อินพุตของโมเดลรับหลายภาพพร้อมการกำหนดบทบาทอย่างชัดเจน (เช่น “Image A: pose”, “Image B: face reference”, “Image C: background texture”) สถาปัตยกรรมจะทำ conditioning การสร้างจากภาพเหล่านั้น เพื่อคงอัตลักษณ์/ท่าทาง/สไตล์ ขณะใช้การแปลงต่าง ๆ (แสง กล้อง)
เกณฑ์วัดประสิทธิภาพของ Nano Banana Pro
Nano Banana Pro (Gemini 3 Pro Image) “โดดเด่นในเกณฑ์วัด AI แบบ Text→Image” และแสดงให้เห็นถึงการให้เหตุผลและการยึดโยงกับบริบทที่ดีขึ้นเมื่อเทียบกับ Nano Banana รุ่นก่อนหน้า โดยเน้นความคมชัดที่สูงขึ้นและการเรนเดอร์ข้อความที่ดีขึ้นเมื่อเทียบกับรุ่นก่อน
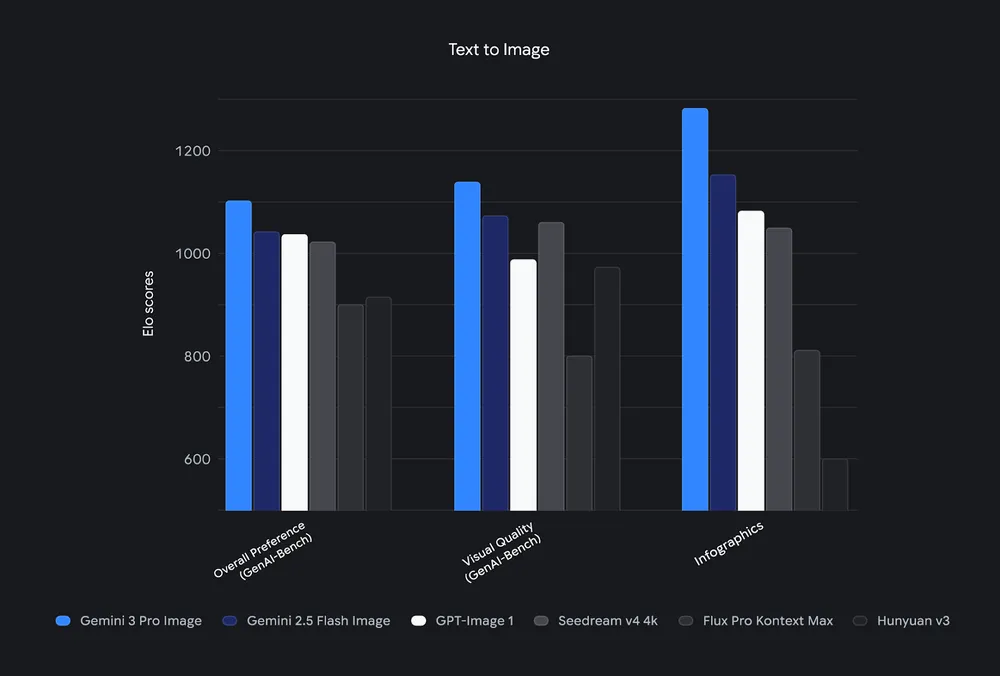
แนวทางด้านประสิทธิภาพเชิงปฏิบัติ
คาดการณ์ได้ว่า เวลาแฝง และต้นทุนสำหรับการเรนเดอร์คุณภาพสูงระดับ 2K/4K จะสูงกว่า 1K หรือโมเดล “Flash” ที่ปรับให้เหมาะกับความเร็ว หาก throughput/latency มีความสำคัญ ให้ใช้รุ่น flash (เช่น Gemini 2.5 Flash / Nano Banana) สำหรับงานปริมาณมาก; ใช้ Nano Banana Pro / gemini-3-pro-image สำหรับงานที่ต้องการคุณภาพสูงและการให้เหตุผลที่ซับซ้อน
นักพัฒนาจะเข้าถึง Nano Banana Pro ได้อย่างไร?
ควรเลือก endpoint และโมเดลใด
ตัวระบุโมเดล (preview / pro): gemini-3-pro-image-preview (preview) — ใช้ตัวนี้เมื่อคุณต้องการความสามารถของ Nano Banana Pro สำหรับงานที่เร็วกว่าและต้นทุนต่ำกว่า gemini-2.5-flash-image (Nano Banana) ยังคงพร้อมใช้งาน
ช่องทางที่ใช้ได้
- Gemini API (generativelanguage endpoint): คุณสามารถใช้คีย์ CometAPI เพื่อเข้าถึง xx ได้ CometAPI นำเสนอ API เดียวกันในราคาที่คุ้มกว่าบนเว็บไซต์ทางการ ใช้การเรียก Direct HTTP / SDK ไปที่
generateContentสำหรับการสร้างภาพ (ตัวอย่างด้านล่าง) - Google AI Studio: อินเทอร์เฟซเว็บสำหรับทดลองอย่างรวดเร็วและรีมิกซ์แอปเดโม
- Vertex AI (enterprise): throughput แบบ provisioned, ตัวเลือกด้านบิลลิง (pay-as-you-go / enterprise tiers) และตัวกรองความปลอดภัยสำหรับงาน production ขนาดใหญ่ ใช้ Vertex เมื่อต้องการผสานเข้ากับ pipeline ขนาดใหญ่หรืองาน batch rendering
ระดับฟรีมีข้อจำกัดด้านการใช้งาน; หากเกินขีดจำกัดจะกลับไปใช้ Nano Banana ระดับ Plus/Pro/Ultra ให้ขีดจำกัดที่สูงกว่าและเอาต์พุตแบบไม่มีลายน้ำ แต่ Ultra สามารถใช้ในเครื่องมือวิดีโอ Flow และ Antigravity IDE ในโหมด 4K ได้
ฉันจะสร้างภาพด้วย Nano Banana Pro ได้อย่างไร (ทีละขั้นตอน)?
1) สูตรใช้งานแบบโต้ตอบอย่างรวดเร็วเพื่อใช้ Gemini app
- เปิด Gemini → Tools → Create images
- เลือก Thinking (Nano Banana Pro) เป็นโมเดล
- ป้อน prompt: อธิบายตัวแบบ การกระทำ อารมณ์ แสง มุมกล้อง อัตราส่วนภาพ และข้อความใด ๆ ที่ต้องการให้ปรากฏบนภาพ ตัวอย่าง:
“Create a 4K poster of a robotics workshop: a diverse team around a table, blueprint overlay, bold headline ‘Robots in Action’ in sans serif, warm tungsten light, shallow depth of field, cinematic 16:9.” - (ไม่บังคับ) อัปโหลดภาพได้สูงสุด 14 ภาพเพื่อผสานหรือใช้เป็นภาพอ้างอิง ใช้เครื่องมือเลือก/มาสก์เพื่อแก้ไขเฉพาะบริเวณ
- สร้างภาพ ปรับแก้ด้วยภาษาธรรมชาติ (เช่น “make the headline blue and aligned top-center; increase contrast on the blueprint”) จากนั้นส่งออก
2) ใช้ HTTP เพื่อส่งไปยัง Gemini image endpoint
คุณต้องเข้าสู่ระบบ CometAPI เพื่อรับคีย์
# save your API key to $CometAPI_API_KEY securely before running
curl -s -X POST \
"https://api.cometapi.com/v1beta/models/gemini-3-pro-image-preview:generateContent" \
-H "x-goog-api-key: $CometAPI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"contents": [{
"role": "user",
"parts": [{
"text": "Photorealistic 4K image of a yellow banana floating over Earth, studio lighting, cinematic composition. Add bold text overlay: \"Nano Banana Pro\" in top right corner."
}]
}],
"generationConfig": {
"imageConfig": {
"resolution": "4096x4096",
"aspectRatio": "1:1"
}
}
}' \
| jq -r '.candidates.content.parts[] | select(.inlineData) | .inlineData.data' \
| base64 --decode > nano_banana_pro_4k.png
ตัวอย่างนี้จะเขียน payload ภาพแบบ base64 ลงในไฟล์ PNG พารามิเตอร์ generationConfig.imageConfig.resolution ใช้สำหรับขอเอาต์พุตระดับ 4K (มีให้ใช้ในโมเดล 3 Pro Image)
3) เรียกใช้ generateContent โดยตรงผ่าน SDK สำหรับการสร้างภาพ
ต้องติดตั้ง Google SDK และรับการยืนยันตัวตนของ Google ตัวอย่าง Python (ข้อความ + ภาพอ้างอิง + grounding):
# pip install google-genai pillow
from google import genai
from PIL import Image
import base64
client = genai.Client() # reads credentials from env / config per SDK docs
# Read a reference image and set inline_data
with open("ref1.png", "rb") as f:
ref1_b64 = base64.b64encode(f.read()).decode("utf-8")
prompt_parts = [
{"text": "Create a styled product ad for a yellow banana-based energy bar. Use studio lighting, shallow DOF. Include a product label with the brand name 'Nano Bar'."},
{"inline_data": {"mime_type": "image/png", "data": ref1_b64}}
]
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=,
generation_config={
"imageConfig": {"resolution":"4096x4096", "aspectRatio":"4:3"},
# tools can be provided to ground facts, e.g. "google_search"
"tools":
}
)
for part in response.candidates.content.parts:
if part.inline_data:
image = part.as_image()
image.save("product_ad.png")
ตัวอย่างนี้แสดงการอัปโหลดภาพอ้างอิงแบบ inline และการร้องขอองค์ประกอบระดับ 4K พร้อมเปิดใช้ google_search เป็นเครื่องมือ Python SDK จะจัดการรายละเอียด REST ระดับล่างให้
การผสานหลายภาพและความสม่ำเสมอของตัวละคร
หากต้องการสร้างภาพคอมโพสิตที่คงบุคคลเดิมไว้ข้ามฉาก ให้ส่ง inline_data หลายรายการ (เลือกจากชุดภาพของคุณ) และระบุคำสั่งเชิงสร้างสรรค์ว่าโมเดลควร “preserve identity across outputs”
ตัวอย่างใช้งานสั้น ๆ — prompt จริงและโฟลว์ที่คาดหวัง
Prompt:
"Generate a 2K infographic: 'Q4 Sales by Region 2025' — stacked bar chart with North America 35%, EMEA 28%, APAC 25%, LATAM 12%. Include title top-center, caption with source bottom-right, clean sans-serif labels, neutral palette, vector look, 16:9."
Pipeline ที่คาดหวัง: app → prompt template + ข้อมูล CSV → แทนที่ placeholder ใน prompt → เรียก API ด้วย image_size=2048x1152 → รับ base64 PNG → บันทึก asset + provenance metadata → หากจำเป็นอาจซ้อนฟอนต์ที่แม่นยำด้วย compositor เพิ่มเติม
ฉันควรออกแบบ production pipeline และจัดการเรื่องความปลอดภัย / provenance อย่างไร?
สถาปัตยกรรม production ที่แนะนำ
- Prompt + draft pass (โมเดลเร็ว): ใช้
gemini-2.5-flash-image(Nano Banana) เพื่อสร้างตัวเลือกจำนวนมากที่ความละเอียดต่ำในต้นทุนที่ประหยัด - การคัดเลือกและปรับแต่ง: เลือก candidate ที่ดีที่สุด ปรับแต่ง prompt และใช้ inpainting/การแก้ไขด้วยมาสก์เพื่อความแม่นยำ
- การเรนเดอร์สุดท้ายความคมชัดสูง: เรียก
gemini-3-pro-image-preview(Nano Banana Pro) สำหรับเรนเดอร์สุดท้ายระดับ 2K/4K และ postprocessing (upsampling, color grade) - Provenance และ metadata: จัดเก็บ prompt, เวอร์ชันโมเดล, timestamp และข้อมูล SynthID ในระบบเก็บ metadata ของ asset — โมเดลจะติดลายน้ำ SynthID และสามารถย้อนรอยเอาต์พุตกลับมาเพื่อการปฏิบัติตามข้อกำหนดและการตรวจสอบเนื้อหาได้
ความปลอดภัย สิทธิ์ และการกลั่นกรอง
- ลิขสิทธิ์และการเคลียร์สิทธิ์: อย่าอัปโหลดหรือสร้างเนื้อหาที่ละเมิดสิทธิ์ ใช้การยืนยันจากผู้ใช้อย่างชัดเจนสำหรับภาพหรือ prompt ที่ผู้ใช้ส่งเข้ามาซึ่งอาจสร้างภาพเหมือนของบุคคลที่จดจำได้ ต้องปฏิบัติตามนโยบายการใช้งานต้องห้ามของ Google และตัวกรองความปลอดภัยของโมเดล
- การกรองและการตรวจสอบอัตโนมัติ: นำภาพที่สร้างแล้วเข้าสู่ pipeline กลั่นกรองเนื้อหาภายใน (NSFW, สัญลักษณ์ความเกลียดชัง, การตรวจจับเนื้อหาทางการเมือง/ที่มีผลผูกพัน) ก่อนใช้งานต่อหรือแสดงผลสู่สาธารณะ
ฉันจะทำ image editing (inpainting), การผสานหลายภาพ และการเรนเดอร์ข้อความได้อย่างไร?
Nano Banana Pro รองรับเวิร์กโฟลว์การแก้ไขแบบมัลติโหมด: ระบุภาพนำเข้าหนึ่งภาพหรือหลายภาพพร้อมคำสั่งข้อความที่อธิบายการแก้ไข (ลบวัตถุ เปลี่ยนท้องฟ้า เพิ่มข้อความ) API รับภาพ + ข้อความในคำขอเดียวกัน; โมเดลสามารถสร้างข้อความและภาพสลับกันในผลลัพธ์ได้ รูปแบบตัวอย่างรวมถึงการแก้ไขด้วยมาสก์และการผสมหลายภาพ (style transfer / composition) โปรดดูเอกสารสำหรับ contents arrays ที่รวม text blobs และ binary images เข้าด้วยกัน
ตัวอย่าง: แก้ไข (Python pseudo-flow)
from google import genai
from PIL import Image
client = genai.Client()
prompt = "Remove the person on the left and add a small red 'Nano Banana Pro' sticker on the top-right of the speaker"
# contents can include Image objects or binary data per SDK; see doc for exact call
response = client.models.generate_content(
model="gemini-3-pro-image-preview",
contents=, # order matters: image + instruction
)
# Save result as before
การแก้ไขแบบสนทนานี้ช่วยให้คุณค่อย ๆ ปรับผลลัพธ์จนได้ asset ที่พร้อมใช้งานจริง
ตัวอย่าง Node.js — แก้ไขภาพด้วย mask และภาพอ้างอิงหลายภาพ
// npm install google-auth-library node-fetch
const { GoogleAuth } = require('google-auth-library');
const fetch = require('node-fetch');
const auth = new GoogleAuth({ scopes: });
async function runEdit() {
const client = await auth.getClient();
const token = await client.getAccessToken();
const API_URL = "https://api.generativemodels.googleapis.com/v1alpha/gemini:editImage";
const MODEL = "gemini-3-pro-image";
// Attach binary image content or URLs depending on API.
const payload = {
model: MODEL,
prompt: { text: "Replace background with an indoor studio set, keep subject, add rim light." },
inputs: {
referenceImages: [
{ uri: "gs://my-bucket/photo_subject.jpg" },
{ uri: "gs://my-bucket/target_studio.jpg" }
],
mask: { uri: "gs://my-bucket/mask.png" },
imageConfig: { resolution: "2048x2048", format: "png" }
},
options: { preserveIdentity: true }
};
const res = await fetch(API_URL, {
method: 'POST',
headers: {
'Authorization': `Bearer ${token.token}`,
'Content-Type': 'application/json'
},
body: JSON.stringify(payload)
});
const out = await res.json();
console.log(JSON.stringify(out, null, 2));
}
runEdit();
(บางครั้ง API อาจรับ Cloud Storage URI หรือ payload ภาพแบบ base64; โปรดตรวจสอบเอกสาร Gemini API สำหรับรูปแบบอินพุตที่แน่นอน)
สำหรับข้อมูลเกี่ยวกับการสร้างและแก้ไขภาพโดยใช้ CometAPI โปรดดูที่ Guide to calling gemini-3-pro-image .
บทสรุป
Nano Banana Pro (Gemini 3 Pro Image) คือก้าวกระโดดระดับ production ในการสร้างภาพ: เป็นเครื่องมือสำหรับการทำให้ข้อมูลมองเห็นได้ การสร้างการแก้ไขแบบ localized และการขับเคลื่อนเวิร์กโฟลว์ของนักพัฒนา ใช้แอป Gemini สำหรับการสร้างต้นแบบอย่างรวดเร็ว ใช้ API สำหรับการผสานเข้ากับระบบ production และปฏิบัติตามคำแนะนำข้างต้นเพื่อควบคุมต้นทุน รักษาความปลอดภัย และคงคุณภาพของแบรนด์ ควรทดสอบกับเวิร์กโฟลว์ของผู้ใช้จริงเสมอ และจัดเก็บ provenance metadata เพื่อให้เป็นไปตามข้อกำหนดด้านความโปร่งใสและการตรวจสอบย้อนหลัง
ใช้ Nano Banana Pro เมื่อคุณต้องการ asset คุณภาพระดับสตูดิโอ การควบคุมองค์ประกอบอย่างแม่นยำ การเรนเดอร์ข้อความในภาพที่ดีขึ้น และความสามารถในการผสานภาพอ้างอิงหลายภาพให้เป็นเอาต์พุตที่สอดคล้องกันหนึ่งชิ้น
นักพัฒนาสามารถเข้าถึง Gemini 3 Pro Image( Nano Banana Pro) API ผ่าน CometAPI ได้ หากต้องการเริ่มต้น ให้สำรวจความสามารถของโมเดลของ CometAPI ใน Playground และศึกษา API guide สำหรับคำแนะนำโดยละเอียด ก่อนเข้าถึง โปรดตรวจสอบว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับ API key แล้ว CometAPI เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยให้คุณผสานระบบได้ง่ายขึ้น
พร้อมเริ่มใช้งานหรือยัง?→ สมัครใช้งาน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คู่มือ และข่าวสารเกี่ยวกับ AI เพิ่มเติม ติดตามเราได้ที่ VK, X และ Discord!