

Kling O1 ซึ่งเปิดตัวในสัปดาห์เปิดตัว “Omni” ของ Kling AI วางตำแหน่งตัวเองเป็นโมเดลพื้นฐานวิดีโอมัลติโหมดแบบรวมศูนย์ที่รับข้อความ รูปภาพ และวิดีโอในคำขอเดียวกัน และสามารถสร้างและตัดต่อวิดีโอในเวิร์กโฟลว์แบบวนซ้ำระดับผู้กำกับได้ ทีมงานของ Kling ยกย่อง O1 ว่าเป็น “โมเดลวิดีโอมัลติโหมดขนาดใหญ่แบบรวมศูนย์ตัวแรกของโลก” การทดสอบภายในของ Kling แสดงให้เห็นถึงชัยชนะเหนือ Veo 3.1 และ Runway Aleph ของ Google อย่างมาก
Kling O1 คืออะไร?
Kling O1 (มักทำตลาดในชื่อ วิดีโอ O1 or ออมนิวัน) คือโมเดลพื้นฐานวิดีโอที่เพิ่งเปิดตัวใหม่จาก Kling AI ซึ่งรวมการสร้างและการตัดต่อข้อความ รูปภาพ และวิดีโอไว้ด้วยกันภายในเฟรมเวิร์กเดียวที่ขับเคลื่อนด้วยพรอมต์ แทนที่จะแยกกระบวนการแปลงข้อความเป็นวิดีโอ รูปภาพเป็นวิดีโอ และการตัดต่อวิดีโอเป็นกระบวนการที่แยกจากกัน Kling O1 จะรับอินพุตแบบผสม (ข้อความ + รูปภาพหลายรูป + วิดีโออ้างอิงเสริม) ในพรอมต์เดียว จากนั้นจึงให้เหตุผลประกอบ และสร้างคลิปสั้นๆ ที่สอดคล้องกัน หรือตัดต่อฟุตเทจที่มีอยู่ด้วยการควบคุมที่ละเอียด บริษัทวางตำแหน่งการเปิดตัวนี้เป็นส่วนหนึ่งของ "Omni Launch" และอธิบายว่า O1 เป็น "เอ็นจิ้นวิดีโอแบบมัลติโมดัล" ที่สร้างขึ้นจากกระบวนทัศน์ภาษาภาพแบบมัลติโมดัล (MVL) และเส้นทางการให้เหตุผลแบบโซ่แห่งความคิด (CoT) เพื่อตีความคำสั่งสร้างสรรค์ที่ซับซ้อนและมีหลายส่วน
ข้อความของคลิงเน้นขั้นตอนการทำงานจริงสามขั้นตอน ได้แก่ (1) การสร้างข้อความ → วิดีโอ (2) ภาพ/องค์ประกอบ → วิดีโอ (การผสมภาพและการสลับวัตถุ/อุปกรณ์ประกอบฉากโดยใช้การอ้างอิงที่ชัดเจน) และ (3) การตัดต่อวิดีโอ/การต่อภาพ (การปรับแต่งภาพ การเพิ่ม/ลบวัตถุ การควบคุมเฟรมเริ่มต้น/เฟรมสิ้นสุด) โมเดลนี้รองรับพรอมต์แบบหลายองค์ประกอบ (รวมถึงรูปแบบ "@" สำหรับการกำหนดเป้าหมายภาพอ้างอิงเฉพาะ) และมีการควบคุมแบบผู้กำกับ เช่น การยึดเฟรมเริ่มต้น/เฟรมสิ้นสุด และการต่อภาพเพื่อสร้างลำดับภาพแบบหลายช็อต
5 ไฮไลท์สำคัญของ Kling O1
1) อินพุตมัลติโหมดรวมที่แท้จริง (MVL)
ความสามารถหลักของ Kling O1 คือการจัดการข้อความ ภาพนิ่ง (อ้างอิงหลายรายการ) และวิดีโอให้เป็นอินพุตชั้นยอดพร้อมกัน ผู้ใช้สามารถส่งภาพอ้างอิงหลายภาพ (หรือคลิปอ้างอิงสั้นๆ) ได้ และ คำสั่งภาษาธรรมชาติ โมเดลจะวิเคราะห์อินพุตทั้งหมดเข้าด้วยกันเพื่อสร้างหรือแก้ไขเอาต์พุตที่สอดคล้องกัน ซึ่งจะช่วยลดความขัดข้องระหว่างเครื่องมือและช่วยให้สามารถใช้งานเวิร์กโฟลว์ต่างๆ เช่น "ใช้ subject จาก @image1, วางไว้ในสิ่งแวดล้อมจาก @image2, จับคู่การเคลื่อนไหวกับ ref_video.mp4และใช้เกรดสีภาพยนตร์ X” การจัดกรอบ “ภาษาภาพหลายโหมด” (Multimodal Visual Language: MVL) นี้เป็นแกนหลักของการนำเสนอของ Kling
ทำไมมันเรื่อง: เวิร์กโฟลว์การสร้างสรรค์ที่แท้จริงมักต้องการการผสมผสานการอ้างอิงต่างๆ เช่น ตัวละครจากทรัพยากรหนึ่ง การเคลื่อนที่ของกล้องจากอีกทรัพยากรหนึ่ง และคำแนะนำการบรรยายในข้อความ การรวมอินพุตเหล่านี้เข้าด้วยกันจะช่วยให้สามารถสร้างข้อมูลได้เพียงครั้งเดียวและลดขั้นตอนการประมวลผลด้วยตนเอง
2) การแก้ไข + การสร้างในโมเดลเดียว (โหมดหลายองค์ประกอบ)
ระบบก่อนหน้านี้ส่วนใหญ่แยกการสร้าง (ข้อความ→วิดีโอ) ออกจากการตัดต่อแบบเฟรมที่แม่นยำ O1 ตั้งใจรวมทั้งสองระบบเข้าด้วยกัน: โมเดลเดียวกันที่สร้างคลิปตั้งแต่ต้นสามารถตัดต่อฟุตเทจที่มีอยู่ได้ เช่น สลับวัตถุ จัดแต่งเสื้อผ้าใหม่ ถอดอุปกรณ์ประกอบฉาก หรือขยายช็อต ทั้งหมดนี้ผ่านคำสั่งภาษาธรรมชาติ การรวมกันนี้ช่วยลดความซับซ้อนของเวิร์กโฟลว์สำหรับทีมงานฝ่ายผลิต
โมเดล O1 ประสบความสำเร็จในการผสานรวมงานวิดีโอหลายๆ อย่างเข้าไว้ด้วยกันอย่างลึกซึ้ง:
- การสร้างข้อความเป็นวิดีโอ
- การสร้างการอ้างอิงรูปภาพ/เรื่อง
- การตัดต่อวิดีโอและการลงสีใหม่
- การรีสไตล์วิดีโอ
- การสร้างช็อตถัดไป/ก่อนหน้า
- การสร้างวิดีโอที่จำกัดคีย์เฟรม
ความสำคัญสูงสุดของการออกแบบนี้อยู่ที่: กระบวนการที่ซับซ้อนซึ่งก่อนหน้านี้ต้องใช้แบบจำลองหลายแบบหรือเครื่องมืออิสระ ตอนนี้สามารถเสร็จสมบูรณ์ได้ภายในเอนจินเดียว ซึ่งไม่เพียงแต่ช่วยลดต้นทุนการสร้างและการคำนวณได้อย่างมาก แต่ยังเป็นการวางรากฐานสำหรับการพัฒนา "แบบจำลองการทำความเข้าใจและสร้างวิดีโอแบบรวม" อีกด้วย
3) ความสอดคล้องของการสร้างวิดีโอ
ความสอดคล้องของเอกลักษณ์: แบบจำลอง O1 ช่วยเพิ่มความสามารถในการสร้างแบบจำลองความสอดคล้องแบบข้ามโหมด โดยรักษาเสถียรภาพของโครงสร้าง วัสดุ แสง และรูปแบบของวัตถุอ้างอิงในระหว่างกระบวนการสร้าง:
- รองรับภาพอ้างอิงหลายมุมมองสำหรับการสร้างแบบจำลองเรื่อง
- รองรับความสอดคล้องของวัตถุในช็อตที่แตกต่างกัน (ตัวละคร วัตถุ และคุณลักษณะของฉากยังคงต่อเนื่องกันในช็อตที่แตกต่างกัน)
- รองรับการอ้างอิงแบบไฮบริดหลายเรื่อง ช่วยให้สามารถสร้างภาพกลุ่มและสร้างฉากแบบโต้ตอบได้
กลไกนี้ช่วยปรับปรุงความสอดคล้องและ "ความสอดคล้องของตัวตน" ของการสร้างวิดีโอได้อย่างมีนัยสำคัญ ทำให้เหมาะกับสถานการณ์ที่มีความต้องการความสอดคล้องที่สูงมาก เช่น การโฆษณาและการสร้างช็อตระดับภาพยนตร์
ปรับปรุงหน่วยความจำ: แบบจำลอง O1 ยังมี "หน่วยความจำ" ซึ่งป้องกันไม่ให้รูปแบบเอาต์พุตไม่เสถียรเนื่องจากบริบทที่ยาวหรือคำสั่งที่เปลี่ยนแปลง แบบจำลอง O1 ยังสามารถทำได้:
- จดจำตัวอักษรได้หลายตัวพร้อมกัน
- ให้ตัวละครต่าง ๆ โต้ตอบกันในวิดีโอได้
- รักษาความสม่ำเสมอในเรื่องสไตล์ การแต่งกาย และการวางตัว
4) การจัดองค์ประกอบที่แม่นยำด้วยรูปแบบ "@" และการควบคุมเฟรมเริ่มต้น/สิ้นสุด
Kling แนะนำระบบย่อสำหรับการจัดองค์ประกอบ (รายงานเป็นระบบการกล่าวถึง "@") เพื่อให้คุณสามารถอ้างอิงรูปภาพเฉพาะในพรอมต์ได้ (เช่น @image1, @image2) เพื่อกำหนดบทบาทให้กับสินทรัพย์ได้อย่างน่าเชื่อถือ เมื่อรวมกับข้อกำหนดเฟรมเริ่มต้นและสิ้นสุดที่ชัดเจน ทำให้สามารถควบคุมระดับผู้กำกับได้ว่าองค์ประกอบต่างๆ จะเปลี่ยนแปลง เคลื่อนที่ หรือเปลี่ยนรูปร่างอย่างไรในคลิปที่สร้างขึ้น ซึ่งเป็นชุดฟีเจอร์ที่เน้นการผลิต ซึ่งทำให้ O1 แตกต่างจากโปรแกรมสร้างวิดีโอที่เน้นผู้บริโภคทั่วไป
5) เอาต์พุตที่มีความเที่ยงตรงสูง ความยาวค่อนข้างมาก และการซ้อนข้อมูลแบบมัลติทาสก์
มีรายงานว่า Kling O1 สามารถผลิตวิดีโอความละเอียด 1080p ระดับภาพยนตร์ (30fps) และ — ด้วยเวอร์ชันก่อนหน้าของ Kling ที่เป็นพื้นฐาน — บริษัทจึงได้นำเสนอวิดีโอที่มีความยาวมากขึ้น (รายงานสูงสุด 2 นาทีในบทความผลิตภัณฑ์ล่าสุด) นอกจากนี้ยังรองรับการซ้อนงานสร้างสรรค์หลายงานไว้ในคำขอเดียว (สร้าง เพิ่มหัวเรื่อง เปลี่ยนแสง และแก้ไของค์ประกอบ) คุณสมบัติเหล่านี้ทำให้ Kling O1 สามารถแข่งขันกับเอ็นจิ้นข้อความ→วิดีโอระดับสูงกว่าได้
ทำไมมันเรื่อง: คลิปที่มีความเที่ยงตรงสูงและยาวขึ้น รวมถึงความสามารถในการรวมการตัดต่อ ช่วยลดความจำเป็นในการเย็บคลิปสั้นๆ จำนวนมากเข้าด้วยกัน และทำให้การผลิตแบบครบวงจรง่ายขึ้น
Kling O1 ได้รับการออกแบบสถาปัตยกรรมมาอย่างไร และมีกลไกพื้นฐานอะไรบ้าง
O1 รอบ ๆ ภาษาภาพหลายโหมด (MVL) แกนหลัก: แบบจำลองที่เรียนรู้การฝังตัวร่วมสำหรับภาษา + ภาพ + สัญญาณการเคลื่อนไหว (เฟรมวิดีโอและคุณลักษณะแบบออปติคัลโฟลว์) จากนั้นจึงใช้ตัวถอดรหัสแบบกระจายหรือแบบหม้อแปลงเพื่อสังเคราะห์เฟรมที่มีความสอดคล้องกันตามเวลา แบบจำลองนี้อธิบายว่าดำเนินการ ปรับอากาศ จากการอ้างอิงหลายรายการ (ข้อความ รูปภาพแบบหนึ่งต่อหลายรายการ วิดีโอคลิปสั้น) เพื่อสร้างการแสดงวิดีโอแฝงซึ่งจากนั้นจะถอดรหัสเป็นรูปภาพต่อเฟรมในขณะที่รักษาความสอดคล้องตามเวลาผ่านความสนใจข้ามเฟรมหรือโมดูลเวลาเฉพาะทาง
1. หม้อแปลงหลายโหมด + สถาปัตยกรรมบริบทยาว
โมเดล O1 ใช้สถาปัตยกรรม Transformer หลายโหมดที่ Keling พัฒนาขึ้นเอง โดยผสานรวมสัญญาณข้อความ รูปภาพ และวิดีโอ และรองรับหน่วยความจำบริบทชั่วคราวแบบยาว (Multimodal Long Context)
สิ่งนี้ทำให้โมเดลสามารถเข้าใจความต่อเนื่องตามเวลาและความสอดคล้องเชิงพื้นที่ในระหว่างการสร้างวิดีโอ
2. MVL: ภาษาภาพแบบหลายโหมด
MVL คือแกนนวัตกรรมของสถาปัตยกรรมนี้
มันจัดวางภาษาและสัญญาณภาพอย่างลึกซึ้งภายใน Transformer ผ่านเลเยอร์กลางความหมายที่เป็นหนึ่งเดียว ดังนี้:
- อนุญาตให้กล่องอินพุตเดียวเพื่อผสมคำสั่งหลายโหมด
- การปรับปรุงความเข้าใจที่ถูกต้องของโมเดลเกี่ยวกับคำอธิบายภาษาธรรมชาติ
- รองรับการสร้างวิดีโอแบบโต้ตอบที่มีความยืดหยุ่นสูง
การแนะนำ MVL ถือเป็นการเปลี่ยนแปลงในการสร้างวิดีโอจาก "การขับเคลื่อนด้วยข้อความ" ไปเป็น "การขับเคลื่อนด้วยความหมายและภาพร่วมกัน"
3. กลไกการอนุมานแบบห่วงโซ่แห่งความคิด
โมเดล O1 แนะนำเส้นทางการอนุมานแบบ “ห่วงโซ่แห่งความคิด” ในระหว่างขั้นตอนการสร้างวิดีโอ
กลไกนี้ช่วยให้โมเดลสามารถดำเนินการตรรกะของเหตุการณ์และการหักเวลาได้ก่อนการสร้าง จึงรักษาการเชื่อมต่อตามธรรมชาติระหว่างการดำเนินการและเหตุการณ์ภายในวิดีโอ
การอนุมานและแก้ไขไปป์ไลน์
- รุ่น: ฟีด: (ข้อความ + การอ้างอิงรูปภาพที่เป็นทางเลือก + การอ้างอิงวิดีโอที่เป็นทางเลือก + การตั้งค่าการสร้าง) → โมเดลสร้างเฟรมวิดีโอแฝง → ถอดรหัสเป็นเฟรม → การประมวลผลสี/เวลาทางเลือก
- การแก้ไขตามคำสั่ง: ฟีด: (วิดีโอต้นฉบับ + คำแนะนำข้อความ + อ้างอิงรูปภาพเสริม) → โมเดลจะแมปการแก้ไขที่ร้องขอไปยังชุดการแปลงพื้นที่พิกเซลภายใน แล้วสังเคราะห์เฟรมที่แก้ไขแล้วโดยยังคงเนื้อหาที่ไม่เปลี่ยนแปลง เนื่องจากทุกอย่างอยู่ในโมเดลเดียว จึงใช้โมดูลการปรับสภาพและโมดูลเวลาเดียวกันสำหรับทั้งการสร้างและการแก้ไข
Kling Viedo o1 เทียบกับ Veo 3.1 เทียบกับ Runway Aleph
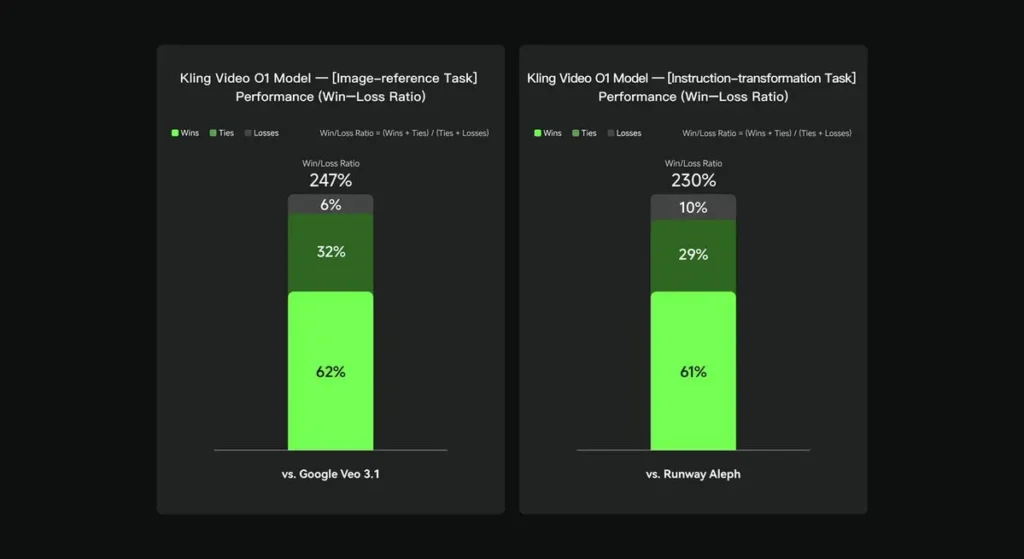
ในการประเมินภายใน Keling Video O1 มีประสิทธิภาพเหนือกว่าคู่แข่งระดับนานาชาติที่มีอยู่เดิมอย่างมีนัยสำคัญในหลายมิติสำคัญ ผลลัพธ์ประสิทธิภาพ (อ้างอิงจากชุดการประเมินที่สร้างขึ้นเองโดย Keling AI):
- งาน "อ้างอิงรูปภาพ": O1 เหนือกว่า Google Veo 3.1 โดยรวม โดยมีอัตราการชนะ 247%
- ภารกิจ “การเปลี่ยนแปลงคำสั่ง”: O1 เอาชนะ Runway Aleph ด้วยอัตราการชนะ 230%
ภาพรวมของคู่แข่ง (การเปรียบเทียบระดับคุณสมบัติ)
| ความสามารถ / รุ่น | คลิง O1 | กูเกิล วีโอ 3.1 | รันเวย์ (Aleph / Gen-4.5) |
|---|---|---|---|
| การแจ้งเตือนแบบหลายโหมดแบบรวม (ข้อความ+รูปภาพ+วิดีโอ) | ใช่ (จุดขายหลัก). กระแสข้อมูลแบบหลายโหมดที่มีการร้องขอครั้งเดียว | บางส่วน — มีข้อความ→วิดีโอ + การอ้างอิง; เน้น MVL แบบรวมเดี่ยวน้อยลง | Runway มุ่งเน้นไปที่การสร้างและแก้ไขแต่บ่อยครั้งเป็นโหมดที่แยกจากกัน Gen-4.5 ล่าสุดช่วยลดช่องว่างลง |
| การแก้ไขพิกเซลแบบสนทนา/ข้อความ | ใช่ — “แก้ไขเหมือนการสนทนา” (ไม่มีหน้ากาก) | บางส่วน — มีการแก้ไขอยู่ แต่เวิร์กโฟลว์หน้ากาก/คีย์เฟรมยังคงเป็นเรื่องปกติ | Runway มีเครื่องมือตัดต่อที่แข็งแกร่ง Runway อ้างว่าการแปลงคำแนะนำมีความแข็งแกร่ง (แตกต่างกันไปในแต่ละรุ่น) |
| การควบคุมเฟรมเริ่มต้น/สิ้นสุดและการอ้างอิงกล้อง | ใช่ — อธิบายการเริ่ม/สิ้นสุดเฟรมและการเคลื่อนไหวของกล้องอ้างอิงอย่างชัดเจน | จำกัด / กำลังพัฒนา | รันเวย์: ปรับปรุงการควบคุม ไม่เหมือนกับ UX เดิม |
| การสร้างคลิปแบบยาว (ความเที่ยงตรงสูง) | นานถึง ~2 นาที (1080p, 30fps) ในเนื้อหาผลิตภัณฑ์และโพสต์ชุมชน | Veo 3.1: มีความสอดคล้องกันที่แข็งแกร่ง แต่เวอร์ชันก่อนหน้ามีค่าเริ่มต้นที่สั้นกว่า แตกต่างกันไปตามรุ่น/การตั้งค่า | Runway Gen-4.5: มุ่งเน้นคุณภาพสูง ความยาว/ความเที่ยงตรงแตกต่างกันไป |
สรุป:
การอ้างชื่อเสียงต่อสาธารณะของ Kling O1 คือ การรวมเวิร์กโฟลว์: การให้โมเดลเดียวทำหน้าที่ในการทำความเข้าใจข้อความ รูปภาพ และวิดีโอ และดำเนินการทั้งการสร้างและการแก้ไขตามคำสั่งที่ซับซ้อนภายในระบบความหมายเดียวกัน สำหรับผู้สร้างและทีมที่มักสลับไปมาระหว่างขั้นตอน "สร้าง" "แก้ไข" และ "ขยาย" การรวมข้อมูลดังกล่าวสามารถลดความซับซ้อนของความเร็วในการวนซ้ำและเครื่องมือได้อย่างมาก ปรับปรุงความสอดคล้องของเวลา การควบคุมเฟรมเริ่มต้น/สิ้นสุด และการผสานรวมแพลตฟอร์มที่ใช้งานได้จริง ซึ่งทำให้ผู้สร้างเข้าถึงได้
API ของ Kling Video o1 จะพร้อมใช้งานบน CometAPI เร็วๆ นี้
นักพัฒนาสามารถเข้าถึงได้ คลิง 2.5 เทอร์บ และ วีโอ 3.1 API ตลอด โคเมทเอพีไอรุ่นล่าสุดที่แสดงไว้เป็นข้อมูล ณ วันที่เผยแพร่บทความ ในการเริ่มต้น ให้สำรวจความสามารถของรุ่นใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว โคเมทเอพีไอ เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยคุณบูรณาการ
พร้อมไปหรือยัง?→ ลงทะเบียน CometAPI วันนี้ !
หากคุณต้องการทราบเคล็ดลับ คำแนะนำ และข่าวสารเกี่ยวกับ AI เพิ่มเติม โปรดติดตามเราที่ VK, X และ ไม่ลงรอยกัน!