

เมื่อวันที่ 17 มิถุนายน เซี่ยงไฮ้เปิดตัว MiniMax อย่างเป็นทางการ มินิแม็กซ์‑M1โมเดลอนุมานแบบไฮบริดที่มีน้ำหนักเปิดขนาดใหญ่รุ่นแรกของโลก โดยการผสมผสานสถาปัตยกรรม Mixture‑of‑Experts (MoE) เข้ากับกลไก Lightning Attention ใหม่ MiniMax‑M1 จึงมอบความได้เปรียบอย่างมากในด้านความเร็วในการอนุมาน การจัดการบริบทที่ยาวนานเป็นพิเศษ และประสิทธิภาพการทำงานที่ซับซ้อน
ความเป็นมาและวิวัฒนาการ
สร้างขึ้นบนรากฐานของ มินิแม็กซ์-เท็กซ์-01ซึ่งเปิดตัวการให้ความสนใจอย่างรวดเร็วในกรอบงาน Mixture-of-Experts (MoE) เพื่อให้ได้บริบท 1 ล้านโทเค็นระหว่างการฝึกและมากถึง 4 ล้านโทเค็นในการอนุมาน MiniMax-M1 เป็นตัวแทนของรุ่นต่อไปของซีรีส์ MiniMax-01 โมเดลก่อนหน้า MiniMax-Text-01 มีพารามิเตอร์ทั้งหมด 456 พันล้านตัวโดยมีการเปิดใช้งาน 45.9 พันล้านตัวต่อโทเค็น แสดงให้เห็นถึงประสิทธิภาพที่เท่าเทียมกับ LLM ระดับสูงสุดในขณะที่ขยายความสามารถของบริบทได้อย่างมาก
คุณสมบัติหลักของ MiniMax‑M1
- ไฮบริด MoE + สายฟ้า ความสนใจ:MiniMax‑M1 ผสมผสานการออกแบบแบบผสมผสานของผู้เชี่ยวชาญแบบเบาบาง ซึ่งมีพารามิเตอร์ทั้งหมด 456 พันล้านตัว แต่มีการเปิดใช้งานเพียง 45.9 พันล้านตัวต่อโทเค็น เข้ากับ Lightning Attention ซึ่งเป็นการใส่ใจในความซับซ้อนเชิงเส้นที่ได้รับการปรับให้เหมาะสมสำหรับลำดับที่ยาวมาก
- บริบทที่ยาวเป็นพิเศษ: รองรับได้ถึง 1ล้าน โทเค็นอินพุต—ประมาณแปดเท่าของขีดจำกัด 128 K ของ DeepSeek‑R1—ช่วยให้เข้าใจเอกสารจำนวนมากได้อย่างลึกซึ้ง
- ประสิทธิภาพที่เหนือกว่า:เมื่อสร้างโทเค็น 100 โทเค็น Lightning Attention ของ MiniMax‑M1 ต้องใช้เพียง ~25–30% ของการประมวลผลที่ใช้โดย DeepSeek‑R1 เท่านั้น
รุ่น Variants
- มินิแม็กซ์‑M1‑40K:บริบทโทเค็น 1 M งบประมาณอนุมานโทเค็น 40 K
- มินิแม็กซ์‑M1‑80K:บริบทโทเค็น 1 M งบประมาณอนุมานโทเค็น 80 K
ในสถานการณ์การใช้งานเครื่องมือ TAU-bench รุ่น 40K เหนือกว่ารุ่นน้ำหนักเปิดทั้งหมด รวมถึง Gemini 2.5 Pro ซึ่งแสดงให้เห็นถึงความสามารถของตัวแทน
ต้นทุนการฝึกอบรมและการตั้งค่า
MiniMax-M1 ได้รับการฝึกแบบครบวงจรโดยใช้การเรียนรู้การเสริมแรงขนาดใหญ่ (RL) ในชุดงานที่หลากหลาย ตั้งแต่การใช้เหตุผลทางคณิตศาสตร์ขั้นสูงไปจนถึงสภาพแวดล้อมทางวิศวกรรมซอฟต์แวร์ที่ใช้แซนด์บ็อกซ์ อัลกอริทึมใหม่ ซีเอสพีโอ (การสุ่มตัวอย่างความสำคัญแบบตัดทอนเพื่อเพิ่มประสิทธิภาพนโยบาย) ช่วยเพิ่มประสิทธิภาพการฝึกอบรมเพิ่มเติมด้วยการตัดน้ำหนักการสุ่มตัวอย่างความสำคัญแทนการอัปเดตระดับโทเค็น แนวทางนี้เมื่อรวมกับการใส่ใจแบบรวดเร็วของโมเดล ทำให้สามารถฝึกอบรม RL เต็มรูปแบบบน GPU H512 จำนวน 800 ตัวได้สำเร็จภายในเวลาเพียงสามสัปดาห์ โดยมีค่าเช่ารวมอยู่ที่ $534,700
ความพร้อมและราคา
MiniMax-M1 เปิดตัวภายใต้ อาปาเช่ 2.0 ใบอนุญาตโอเพ่นซอร์สและสามารถเข้าถึงได้ทันทีผ่าน:
- พื้นที่เก็บข้อมูล GitHubรวมถึงน้ำหนักโมเดล สคริปต์การฝึก และเกณฑ์มาตรฐานการประเมิน
- ซิลิคอนคลาวด์ โฮสติ้ง โดยนำเสนอสองรูปแบบ ได้แก่ 40 K‑token (“M1‑40K”) และ 80 K‑token (“M1‑80K”) พร้อมแผนที่จะเปิดใช้งานช่องทาง 1 M token เต็มรูปแบบ
- ราคาปัจจุบันกำหนดไว้ที่ 4 เยนต่อล้าน โทเค็นสำหรับการป้อนข้อมูลและ 16 เยนต่อล้าน โทเค็นสำหรับการส่งออก พร้อมส่วนลดปริมาณสำหรับลูกค้าองค์กร
นักพัฒนาและองค์กรสามารถบูรณาการ MiniMax-M1 ผ่าน API มาตรฐาน ปรับแต่งข้อมูลเฉพาะโดเมน หรือปรับใช้ภายในสถานที่สำหรับเวิร์กโหลดที่ละเอียดอ่อน
การปฏิบัติงานในระดับงาน
| หมวดหมู่งาน | เน้น | ประสิทธิภาพสัมพัทธ์ |
|---|---|---|
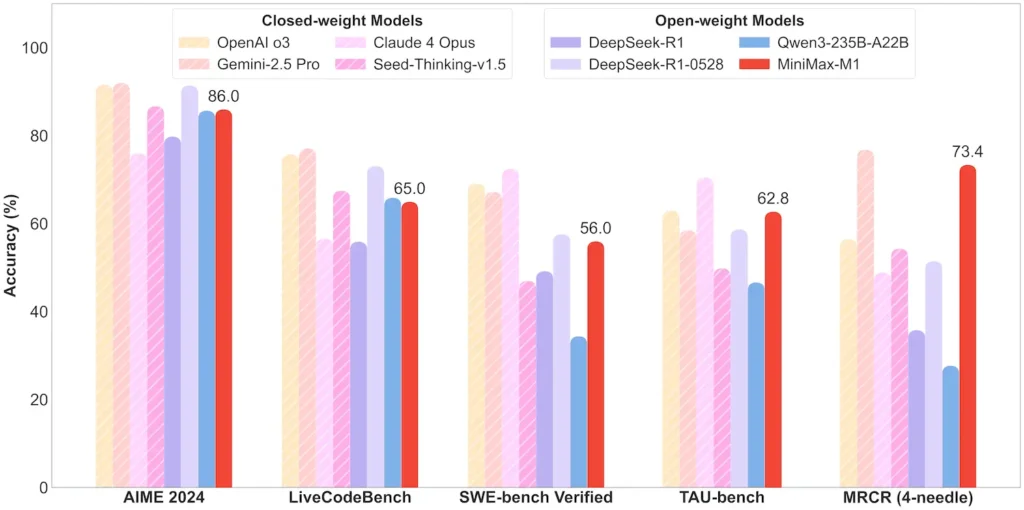
| คณิตศาสตร์และตรรกะ | เอไอเอ็ม 2024: 86.0% | > Qwen 3, DeepSeek‑R1; ใกล้แหล่งปิด |
| ความเข้าใจในบริบทยาว | ไม้บรรทัด (โทเค็น 4 K–1 M): ระดับบนสุดที่มั่นคง | เหนือกว่า GPT‑4 ที่มีความยาวโทเค็นเกิน 128 K |
| วิศวกรรมซอฟต์แวร์ | SWE‑bench (ข้อบกพร่องจริงของ GitHub): 56% | ดีที่สุดในรุ่นเปิด รองจากรุ่นปิด |
| ตัวแทนและการใช้เครื่องมือ | TAU‑bench (จำลอง API) | 62–63.5% เทียบกับเมถุน 2.5, คลอดด์ 4 |
| บทสนทนาและผู้ช่วย | มัลติชาเลนจ์: 44.7% | แมตช์ Claude 4, DeepSeek‑R1 |
| ข้อเท็จจริง QA | SimpleQA: 18.5% | พื้นที่สำหรับการปรับปรุงในอนาคต |
หมายเหตุ: เปอร์เซ็นต์และเกณฑ์มาตรฐานจากการเปิดเผยข้อมูลอย่างเป็นทางการของ MiniMax และรายงานข่าวอิสระ
นวัตกรรมทางเทคนิค
- ไฮบริดเอ็ฟเฟ็กต์สแต็ก: ความสนใจแบบสายฟ้า ชั้นต่างๆ (ต้นทุนเชิงเส้น) สลับกับ Softmax Attention เป็นระยะๆ (กำลังสองแต่แสดงออกได้มากกว่า) เพื่อสร้างสมดุลระหว่างประสิทธิภาพและพลังในการสร้างแบบจำลอง
- การกำหนดเส้นทาง MoE แบบเบาบาง:โมดูลผู้เชี่ยวชาญ 32 ตัว โทเค็นแต่ละตัวจะเปิดใช้งานเพียง ~10% ของพารามิเตอร์ทั้งหมดเท่านั้น ซึ่งช่วยลดต้นทุนการอนุมานในขณะที่ยังคงรักษาความจุไว้
- การเรียนรู้เสริมแรงของ CISPO:อัลกอริทึม “การเพิ่มประสิทธิภาพนโยบายน้ำหนัก IS ที่ถูกตัด” แบบใหม่ที่ยังคงโทเค็นที่หายากแต่สำคัญไว้ในสัญญาณการเรียนรู้ ช่วยเร่งความเสถียรและความเร็วของ RL
การเปิดตัวรุ่นน้ำหนักเปิดของ MiniMax‑M1 ช่วยปลดล็อกการอนุมานในบริบทที่ยาวนานและมีประสิทธิภาพสูงสำหรับทุกคน โดยช่วยเชื่อมช่องว่างระหว่างการวิจัยและ AI ขนาดใหญ่ที่ปรับใช้ได้
เริ่มต้นใช้งาน
CometAPI มอบอินเทอร์เฟซ REST แบบรวมที่รวบรวมโมเดล AI หลายร้อยโมเดล รวมถึงกลุ่ม ChatGPT ภายใต้จุดสิ้นสุดที่สอดคล้องกัน พร้อมการจัดการคีย์ API ในตัว โควตาการใช้งาน และแดชบอร์ดการเรียกเก็บเงิน แทนที่จะต้องจัดการ URL และข้อมูลรับรองของผู้ขายหลายราย
เริ่มต้นด้วยการสำรวจความสามารถของโมเดลใน สนามเด็กเล่น และปรึกษา คู่มือ API สำหรับคำแนะนำโดยละเอียด ก่อนเข้าใช้งาน โปรดตรวจสอบให้แน่ใจว่าคุณได้เข้าสู่ระบบ CometAPI และได้รับรหัส API แล้ว
API ของ MiniMax‑M1 ที่ผสานรวมล่าสุดจะปรากฏบน CometAPI เร็วๆ นี้ โปรดติดตาม! ในขณะที่เรากำลังสรุปการอัปโหลดโมเดล MiniMax‑M1 ให้สำรวจโมเดลอื่นๆ ของเราใน หน้าโมเดล หรือลองพวกเขาใน เอไอ เพลย์กราวด์. รุ่นล่าสุดของ MiniMax ใน CometAPI คือ Minimax ABAB7-ตัวอย่าง API และ มินิแม็กซ์วีดีโอ-01 API ,อ้างถึง:
