Gemini 2.5 Flash ได้รับการออกแบบมาเพื่อส่งมอบการตอบสนองที่รวดเร็วโดยไม่ลดทอนคุณภาพของผลลัพธ์ รองรับอินพุตแบบมัลติโหมด รวมถึงข้อความ รูปภาพ เสียง และวิดีโอ ทำให้เหมาะกับการใช้งานที่หลากหลาย โมเดลสามารถเข้าถึงได้ผ่านแพลตฟอร์มอย่าง Google AI Studio และ Vertex AI มอบเครื่องมือที่จำเป็นให้แก่นักพัฒนาเพื่อผสานรวมเข้ากับระบบต่างๆ ได้อย่างราบรื่น
ข้อมูลพื้นฐาน (ฟีเจอร์)
Gemini 2.5 Flash นำเสนอ ฟีเจอร์ เด่นหลายประการที่ทำให้โดดเด่นภายในตระกูล Gemini 2.5:
- Hybrid Reasoning: นักพัฒนาสามารถตั้งพารามิเตอร์ thinking_budget เพื่อควบคุมอย่างละเอียดว่าโมเดลจะใช้โทเค็นสำหรับการให้เหตุผลภายในก่อนการเอาต์พุตกี่โทเค็น
- Pareto Frontier: อยู่ในจุด ต้นทุน-ประสิทธิภาพที่เหมาะสมที่สุด ทำให้ Flash มีอัตราส่วนราคาต่อความฉลาดดีที่สุดในบรรดาโมเดล 2.5
- Multimodal Support: ประมวลผล ข้อความ, รูปภาพ, วิดีโอ และ เสียง ได้โดยตรง ช่วยเพิ่มความสามารถในการสนทนาและการวิเคราะห์ที่หลากหลายยิ่งขึ้น
- บริบท 1 ล้านโทเค็น: ความยาวบริบทที่ไร้คู่เทียบช่วยให้วิเคราะห์เชิงลึกและทำความเข้าใจเอกสารยาวได้ภายในคำขอเดียว
การจัดการเวอร์ชันของโมเดล
Gemini 2.5 Flash ได้ผ่านการอัปเดตใน เวอร์ชัน สำคัญดังต่อไปนี้:
- gemini-2.5-flash-lite-preview-09-2025: ปรับปรุงการใช้งานเครื่องมือ: เพิ่มประสิทธิภาพในงานที่ซับซ้อนหลายขั้นตอน โดยคะแนน SWE-Bench Verified เพิ่มขึ้น 5% (จาก 48.9% เป็น 54%). ปรับปรุงประสิทธิภาพ: เมื่อเปิดใช้การให้เหตุผล จะได้ผลลัพธ์คุณภาพสูงขึ้นโดยใช้โทเค็นน้อยลง ลดทั้งเวลาแฝงและต้นทุน
- Preview 04-17: รุ่นเข้าถึงล่วงหน้าพร้อมความสามารถ “thinking” พร้อมใช้งานผ่าน gemini-2.5-flash-preview-04-17
- Stable General Availability (GA): นับตั้งแต่วันที่ 17 มิถุนายน 2025 เอนด์พอยต์เสถียร gemini-2.5-flash แทนที่รุ่นพรีวิว รับประกันความเสถียรระดับผลิตจริง โดยไม่มีการเปลี่ยนแปลง API จากพรีวิววันที่ 20 พฤษภาคม
- Deprecation of Preview: เอนด์พอยต์พรีวิวถูกกำหนดให้ปิดใช้งานในวันที่ 15 กรกฎาคม 2025; ผู้ใช้ต้องย้ายไปยังเอนด์พอยต์ GA ก่อนวันดังกล่าว
ณ เดือนกรกฎาคม 2025 Gemini 2.5 Flash เปิดให้ใช้งานสาธารณะและมีเสถียรภาพแล้ว (ไม่มีการเปลี่ยนแปลงจาก gemini-2.5-flash-preview-05-20). หากคุณกำลังใช้ gemini-2.5-flash-preview-04-17 การคิดราคาสำหรับพรีวิวเดิมจะคงอยู่จนถึงวันที่ 15 กรกฎาคม 2025 ซึ่งเป็นกำหนดเลิกใช้เอนด์พอยต์ของโมเดล หลังจากนั้นจะถูกปิด คุณสามารถย้ายไปใช้โมเดลที่เปิดให้ใช้งานทั่วไป "gemini-2.5-flash"
เร็วขึ้น ถูกลง ฉลาดขึ้น:
- เป้าหมายการออกแบบ: latency ต่ำ + throughput สูง + ต้นทุนต่ำ;
- ความเร็วโดยรวมดีขึ้นในการให้เหตุผล การประมวลผลมัลติโหมด และงานข้อความยาว;
- การใช้โทเค็นลดลง 20–30% ลดต้นทุนการให้เหตุผลลงอย่างมีนัยสำคัญ
ข้อกำหนดทางเทคนิค
ขอบเขตบริบทอินพุต: สูงสุด 1 ล้านโทเค็น ช่วยคงบริบทได้อย่างกว้างขวาง.
โทเค็นเอาต์พุต: สร้างได้สูงสุด 8,192 โทเค็นต่อการตอบหนึ่งครั้ง.
โมดาลิตีที่รองรับ: ข้อความ รูปภาพ เสียง และวิดีโอ.
แพลตฟอร์มการผสานรวม: ใช้ได้ผ่าน Google AI Studio และ Vertex AI.
การกำหนดราคา: โมเดลคิดราคาแบบโทเค็นที่มีความสามารถในการแข่งขัน ช่วยให้ปรับใช้ได้คุ้มค่า.
รายละเอียดทางเทคนิค
เบื้องหลัง Gemini 2.5 Flash เป็นแบบจำลองภาษาขนาดใหญ่แบบ transformer-based ที่ผ่านการฝึกด้วยชุดข้อมูลผสมผสานจากเว็บ โค้ด รูปภาพ และวิดีโอ ข้อกำหนดด้าน เทคนิค ที่สำคัญ ได้แก่:
การฝึกแบบมัลติโหมด: ได้รับการฝึกให้จัดแนวโมดาลิตีหลายแบบ ทำให้ Flash ผสานข้อความกับ รูปภาพ, วิดีโอ หรือ เสียง ได้อย่างไร้รอยต่อ เหมาะกับงานอย่างการสรุปวิดีโอหรือการพรรณนาเสียง
กระบวนการคิดแบบไดนามิก: ใช้วงจรการให้เหตุผลภายในที่โมเดลจะ วางแผน และ แตกโจทย์ที่ซับซ้อน ก่อนการเอาต์พุตสุดท้าย
กำหนดงบการคิดได้: สามารถตั้งค่า thinking_budget ได้ตั้งแต่ 0 (ไม่ให้เหตุผล) ไปจนถึง 24,576 โทเค็น ช่วยปรับสมดุลระหว่างเวลาแฝงกับคุณภาพคำตอบ
การผสานรวมเครื่องมือ: รองรับ Grounding with Google Search, Code Execution, URL Context และ Function Calling ช่วยให้ดำเนินการในโลกจริงได้โดยตรงจากพรอมป์ภาษาธรรมชาติ
ผลการทดสอบมาตรฐาน
ในการประเมินอย่างเข้มงวด Gemini 2.5 Flash แสดงประสิทธิภาพระดับ แนวหน้าของอุตสาหกรรม:
- LMArena Hard Prompts: ได้คะแนน เป็นรองเพียง 2.5 Pro บนเบนช์มาร์ก Hard Prompts ที่ท้าทาย แสดงให้เห็นความสามารถในการให้เหตุผลหลายขั้นตอนที่แข็งแกร่ง
- คะแนน MMLU ที่ 0.809: สูงกว่าค่าเฉลี่ยของโมเดล ด้วยความแม่นยำ MMLU ที่ 0.809 สะท้อนถึงคลังความรู้ข้ามโดเมนที่กว้างและความสามารถด้านการให้เหตุผล
- Latency และ Throughput: ทำความเร็วถอดรหัสได้ 271.4 tokens/sec พร้อม 0.29 s Time-to-First-Token เหมาะกับงานที่ไวต่อเวลาแฝง
- ผู้นำด้านราคาเทียบประสิทธิภาพ: ที่ \$0.26/1 M tokens Flash มีราคาดีกว่าคู่แข่งหลายราย พร้อมทำได้ทัดเทียมหรือเหนือกว่าบนเบนช์มาร์กหลัก
ผลลัพธ์เหล่านี้บ่งชี้ถึงความได้เปรียบในการแข่งขันของ Gemini 2.5 Flash ในด้านการให้เหตุผล ความเข้าใจทางวิทยาศาสตร์ การแก้ปัญหาทางคณิตศาสตร์ การเขียนโค้ด การตีความด้วยภาพ และความสามารถหลายภาษา:
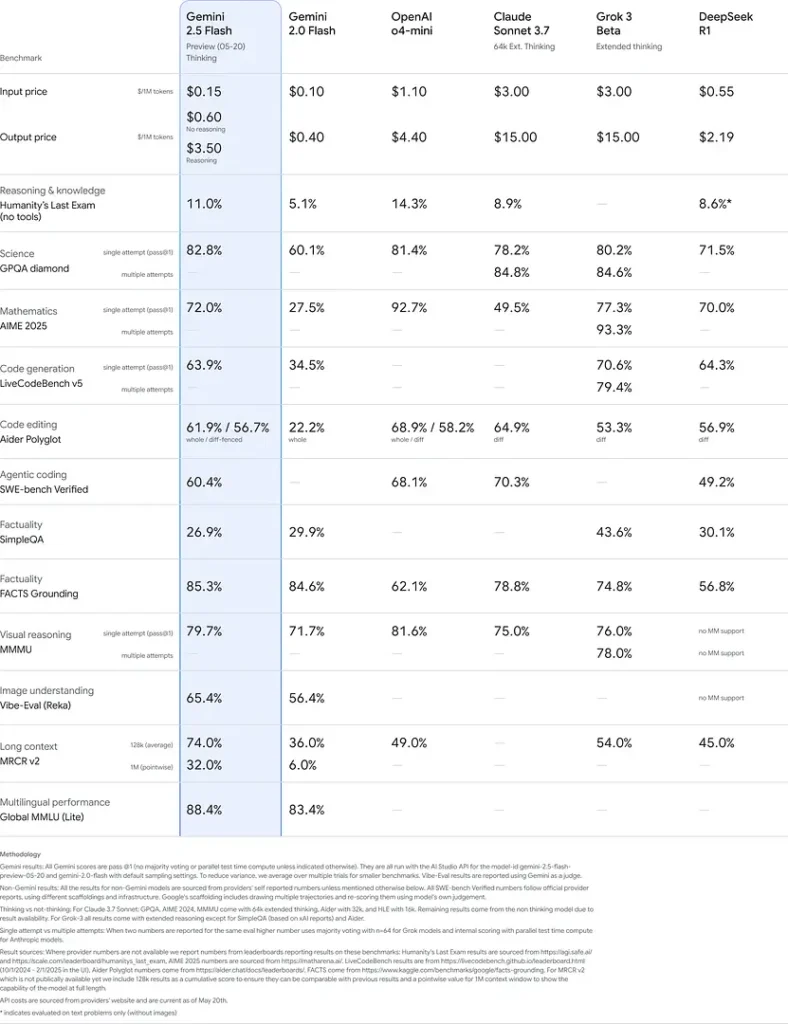
ข้อจำกัด
แม้จะทรงพลัง แต่ Gemini 2.5 Flash ก็มี ข้อจำกัด บางประการ:
- ความเสี่ยงด้านความปลอดภัย: โมเดลอาจแสดงน้ำเสียง “สั่งสอน” และอาจสร้างผลลัพธ์ที่ฟังดูน่าเชื่อถือแต่ไม่ถูกต้องหรือมีอคติ (hallucinations) โดยเฉพาะกับคำถามขอบเคส การกำกับดูแลโดยมนุษย์อย่างเข้มงวดยังคงจำเป็น
- ขีดจำกัดอัตรา: การใช้งาน API ถูกจำกัดด้วย rate limits (10 RPM, 250,000 TPM, 250 RPD ในระดับเริ่มต้น) ซึ่งอาจส่งผลต่อการประมวลผลแบบแบตช์หรือแอปพลิเคชันปริมาณสูง
- ระดับความฉลาดขั้นต่ำ: แม้จะมีความสามารถโดดเด่นสำหรับโมเดลแบบ flash แต่ยังแม่นยำน้อยกว่า 2.5 Pro ในงาน agentic ที่ยากที่สุด เช่น การเขียนโค้ดขั้นสูงหรือการประสานงานหลายเอเจนต์
- การแลกเปลี่ยนด้านต้นทุน: แม้จะให้ ราคา-ประสิทธิภาพ ที่ดีที่สุด แต่การใช้โหมด thinking อย่างหนักจะเพิ่มการใช้โทเค็นโดยรวม ทำให้ต้นทุนสูงขึ้นสำหรับพรอมป์ที่ต้องการการให้เหตุผลเชิงลึก