GLM-4.6 เป็นรุ่นสำคัญล่าสุดในตระกูล GLM ของ Z.ai (เดิมชื่อ Zhipu AI): โมเดลภาษาขนาดใหญ่รุ่นที่ 4 แบบ MoE (Mixture-of-Experts) ที่ปรับจูนเพื่อ เวิร์กโฟลว์เชิงเอเยนต์ การให้เหตุผลบริบทยาว และการเขียนโค้ดในโลกจริง การออกแบบรุ่นนี้เน้นการผสานใช้งานเอเยนต์/เครื่องมือจริง หน้าต่าง บริบท ที่ใหญ่มาก และน้ำหนักโมเดลแบบเปิดสำหรับการติดตั้งภายในองค์กร
คุณสมบัติสำคัญ
- บริบทยาว — หน้าต่างบริบทแบบเนทีฟ 200K token (ขยายจาก 128K). (docs.z.ai)
- ความสามารถด้านโค้ดและเอเยนต์ — ประสิทธิภาพที่โฆษณาว่าดีขึ้นในงานเขียนโค้ดโลกจริง และการเรียกใช้เครื่องมือของเอเยนต์ที่ดีขึ้น
- ประสิทธิภาพ — รายงานว่า ~30% ใช้โทเค็นน้อยลง เมื่อเทียบกับ GLM-4.5 ตามการทดสอบของ Z.ai
- การติดตั้งใช้งานและการควอนไทซ์ — ประกาศครั้งแรกการผสาน FP8 และ Int4 สำหรับชิป Cambricon; รองรับ FP8 แบบเนทีฟบน Moore Threads ผ่าน vLLM
- ขนาดโมเดลและชนิดเทนเซอร์ — อาร์ติแฟกต์ที่เผยแพร่ระบุโมเดล ~357B-parameter (เทนเซอร์ BF16 / F32) บน Hugging Face
รายละเอียดทางเทคนิค
โมดาลิตีและรูปแบบ. GLM-4.6 เป็น LLM แบบ เฉพาะข้อความ (โมดาลิตีอินพุตและเอาต์พุต: ข้อความ). ความยาวบริบท = 200K tokens; เอาต์พุตสูงสุด = 128K tokens.
การควอนไทซ์และการรองรับฮาร์ดแวร์. ทีมรายงาน FP8/Int4 quantization บนชิป Cambricon และการรัน FP8 แบบเนทีฟ บน GPU ของ Moore Threads โดยใช้ vLLM สำหรับอินเฟอเรนซ์ — สำคัญต่อการลดต้นทุนอินเฟอเรนซ์และเปิดทางให้การติดตั้งบนระบบภายในและคลาวด์ภายในประเทศ
เครื่องมือและการผสานระบบ. GLM-4.6 เผยแพร่ผ่าน API ของ Z.ai เครือข่ายผู้ให้บริการบุคคลที่สาม (เช่น CometAPI) และถูกผสานในเอเยนต์สำหรับเขียนโค้ด (Claude Code, Cline, Roo Code, Kilo Code).
รายละเอียดทางเทคนิค
โมดาลิตีและรูปแบบ. GLM-4.6 เป็น LLM แบบ เฉพาะข้อความ (โมดาลิตีอินพุตและเอาต์พุต: ข้อความ). ความยาวบริบท = 200K tokens; เอาต์พุตสูงสุด = 128K tokens.
การควอนไทซ์และการรองรับฮาร์ดแวร์. ทีมรายงาน FP8/Int4 quantization บนชิป Cambricon และการรัน FP8 แบบเนทีฟ บน GPU ของ Moore Threads โดยใช้ vLLM สำหรับอินเฟอเรนซ์ — สำคัญต่อการลดต้นทุนอินเฟอเรนซ์และเปิดทางให้การติดตั้งบนระบบภายในและคลาวด์ภายในประเทศ
เครื่องมือและการผสานระบบ. GLM-4.6 เผยแพร่ผ่าน API ของ Z.ai เครือข่ายผู้ให้บริการบุคคลที่สาม (เช่น CometAPI) และถูกผสานในเอเยนต์สำหรับเขียนโค้ด (Claude Code, Cline, Roo Code, Kilo Code).
ผลการทดสอบเชิงเปรียบเทียบ
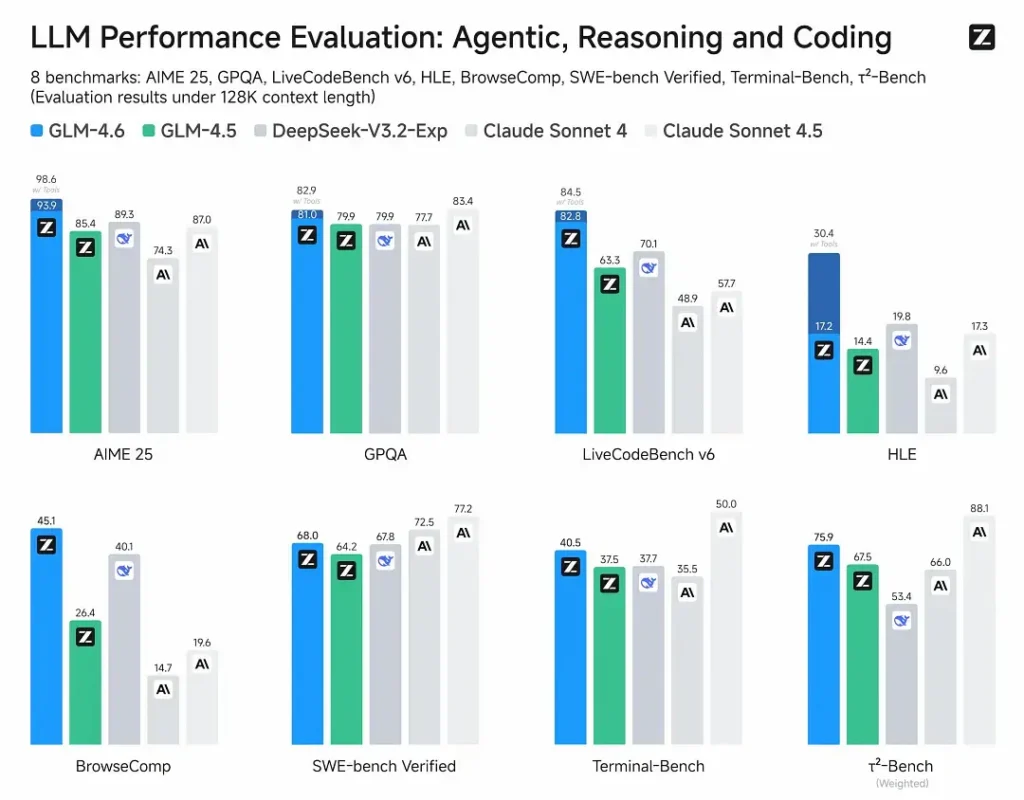
- การประเมินที่เผยแพร่: GLM-4.6 ถูกทดสอบบนเบนช์มาร์กสาธารณะ 8 รายการครอบคลุมเอเยนต์ การให้เหตุผล และการเขียนโค้ด และแสดงให้เห็นว่า เหนือกว่า GLM-4.5 อย่างชัดเจน ในการทดสอบการเขียนโค้ดโลกจริงที่ประเมินโดยมนุษย์ (extended CC-Bench) GLM-4.6 ใช้โทเค็น ~15% น้อยกว่า เทียบกับ GLM-4.5 และทำ อัตราชนะ ~48.6% เทียบกับ Claude Sonnet 4 ของ Anthropic (ใกล้เคียงในหลายตารางจัดอันดับ).
- การจัดวางตำแหน่ง: ผลการทดสอบระบุว่า GLM-4.6 แข่งขันได้กับโมเดลชั้นนำทั้งในประเทศและต่างประเทศ (ตัวอย่างที่อ้างถึงเช่น DeepSeek-V3.1 และ Claude Sonnet 4).
ข้อจำกัดและความเสี่ยง
- ฮัลลูซิเนชันและความผิดพลาด: เช่นเดียวกับ LLM ปัจจุบันทั้งหมด GLM-4.6 อาจทำผิดข้อเท็จจริง — เอกสารของ Z.ai เตือนอย่างชัดเจนว่าผลลัพธ์อาจมีข้อผิดพลาด ผู้ใช้ควรใช้การตรวจสอบและการดึงข้อมูล/RAG สำหรับเนื้อหาที่มีความสำคัญ
- ความซับซ้อนของโมเดลและต้นทุนการให้บริการ: บริบท 200K และเอาต์พุตขนาดใหญ่มากเพิ่มความต้องการหน่วยความจำและเวลาแฝงอย่างมาก และอาจเพิ่มต้นทุนอินเฟอเรนซ์; จำเป็นต้องมีการควอนไทซ์/วิศวกรรมอินเฟอเรนซ์เพื่อรันในสเกลใหญ่
- ช่องว่างตามโดเมน: แม้ GLM-4.6 รายงานประสิทธิภาพเอเยนต์/โค้ดที่แข็งแรง รายงานสาธารณะบางส่วนระบุว่ายัง ตามหลังบางเวอร์ชัน ของโมเดลคู่แข่งในไมโครบันช์มาร์กบางรายการ (เช่น เมตริกโค้ดบางอย่างเทียบกับ Sonnet 4.5) ควรประเมินตามงานก่อนแทนที่โมเดลโปรดักชัน
- ความปลอดภัยและนโยบาย: น้ำหนักแบบเปิดเพิ่มการเข้าถึงแต่ก็สร้างคำถามด้านการกำกับดูแล (การบรรเทา การป้องกัน และการทดสอบเชิงรุกยังเป็นความรับผิดชอบของผู้ใช้)
กรณีใช้งาน
- ระบบเชิงเอเยนต์และการจัดการเครื่องมือ: เทรซเอเยนต์ยาว การวางแผนหลายเครื่องมือ การเรียกใช้เครื่องมือแบบไดนามิก; การปรับจูนเชิงเอเยนต์ของโมเดลเป็นจุดขายสำคัญ
- ผู้ช่วยเขียนโค้ดในโลกจริง: การสร้างโค้ดหลายรอบการสนทนา การรีวิวโค้ด และผู้ช่วย IDE แบบโต้ตอบ (ผสานใน Claude Code, Cline, Roo Code—ตาม Z.ai) การปรับปรุงประสิทธิภาพโทเค็น ทำให้เหมาะกับแผนใช้งานหนักของนักพัฒนา
- เวิร์กโฟลว์เอกสารยาว: สรุปเนื้อหา การสังเคราะห์หลายเอกสาร การรีวิวด้านกฎหมาย/เทคนิคขนาดยาว ด้วยหน้าต่าง 200K
- การสร้างคอนเทนต์และตัวละครเสมือน: บทสนทนายาว การคงบุคลิกที่สอดคล้องในสถานการณ์หลายรอบ
การเปรียบเทียบ GLM-4.6 กับโมเดลอื่น
- GLM-4.5 → GLM-4.6: การเปลี่ยนแปลงแบบก้าวกระโดดใน ขนาดบริบท (128K → 200K) และ ประสิทธิภาพโทเค็น (~15% ใช้โทเค็นน้อยลงบน CC-Bench); การใช้เอเยนต์/เครื่องมือที่ดีขึ้น
- GLM-4.6 vs Claude Sonnet 4 / Sonnet 4.5: Z.ai รายงานว่า ใกล้เคียงกันบนหลายตารางจัดอันดับ และมีอัตราชนะ ~48.6% บนงานโค้ดโลกจริงของ CC-Bench (กล่าวคือ แข่งขันกันสูสี โดยที่บางไมโครบันช์มาร์ก Sonnet ยังนำอยู่) สำหรับหลายทีมวิศวกรรม GLM-4.6 ถูกวางตำแหน่งเป็นตัวเลือกที่คุ้มค่า
- GLM-4.6 vs โมเดลบริบทยาวอื่นๆ (DeepSeek, สายพันธุ์ Gemini, ตระกูล GPT-4): GLM-4.6 เน้นบริบทขนาดใหญ่และเวิร์กโฟลว์โค้ดเชิงเอเยนต์; จุดแข็งสัมพัทธ์ขึ้นกับเมตริก (ประสิทธิภาพโทเค็น/การผสานเอเยนต์ เทียบกับความแม่นยำการสังเคราะห์โค้ดดิบหรือสายงานความปลอดภัย) การเลือกโดยอิงหลักฐานควรขับเคลื่อนด้วยงาน
Zhipu AI’s โมเดลเรือธงล่าสุด GLM-4.6 เปิดตัวแล้ว: พารามิเตอร์รวม 355B, พารามิเตอร์ที่แอคทีฟ 32B. เหนือกว่า GLM-4.5 ในความสามารถหลักทั้งหมด.
- การเขียนโค้ด: ใกล้เคียงกับ Claude Sonnet 4, ดีที่สุดในจีน.
- บริบท: ขยายเป็น 200K (จาก 128K).
- การให้เหตุผล: ดีขึ้น รองรับการเรียกใช้เครื่องมือระหว่างอินเฟอเรนซ์.
- การค้นหา: ปรับปรุงการเรียกใช้เครื่องมือและประสิทธิภาพเอเยนต์.
- การเขียน: สอดคล้องกับความชอบของมนุษย์มากขึ้นในด้านสไตล์ ความอ่านง่าย และการสวมบทบาท.
- หลายภาษา: ยกระดับการแปลข้ามภาษา.