

ในภูมิทัศน์ของปัญญาประดิษฐ์ที่เปลี่ยนแปลงอย่างรวดเร็ว ปี 2025 ได้เห็นความก้าวหน้าที่สำคัญในโมเดลภาษาขนาดใหญ่ (LLM) โมเดลที่เป็นผู้นำ ได้แก่ Qwen2.5 ของ Alibaba โมเดล V3 และ R1 ของ DeepSeek และ ChatGPT ของ OpenAI โมเดลเหล่านี้แต่ละโมเดลล้วนมีความสามารถและนวัตกรรมที่เป็นเอกลักษณ์ บทความนี้จะเจาะลึกถึงการพัฒนาล่าสุดที่เกี่ยวข้องกับ Qwen2.5 โดยเปรียบเทียบคุณสมบัติและประสิทธิภาพกับ DeepSeek และ ChatGPT เพื่อพิจารณาว่าโมเดลใดเป็นผู้นำในการแข่งขันด้าน AI ในปัจจุบัน
Qwen2.5 คืออะไร?
ภาพรวมสินค้า
Qwen 2.5 คือโมเดลภาษาขนาดใหญ่ที่เข้ารหัสเฉพาะตัวถอดรหัสล่าสุดจาก Alibaba Cloud มีให้เลือกหลายขนาดตั้งแต่ 0.5B ถึง 72B พารามิเตอร์ โดยได้รับการปรับให้เหมาะสมสำหรับการปฏิบัติตามคำสั่ง เอาต์พุตที่มีโครงสร้าง (เช่น JSON ตาราง) การเข้ารหัส และการแก้ปัญหาทางคณิตศาสตร์ Qwen29 ได้รับการออกแบบมาเพื่อการใช้งานหลายภาษาและเฉพาะโดเมน โดยรองรับภาษาต่างๆ มากกว่า 128 ภาษาและความยาวบริบทสูงสุดถึง 2.5K
Key Features
- รองรับหลายภาษารองรับมากกว่า 29 ภาษา ตอบสนองฐานผู้ใช้ทั่วโลก
- ขยายความยาวบริบท:รองรับโทเค็นสูงสุด 128 รายการ ช่วยให้สามารถประมวลผลเอกสารและบทสนทนายาวๆ ได้
- ตัวแปรพิเศษ:รวมถึงโมเดลเช่น Qwen2.5-Coder สำหรับงานการเขียนโปรแกรมและ Qwen2.5-Math สำหรับการแก้ปัญหาทางคณิตศาสตร์
- การเข้าถึง:มีให้บริการผ่านแพลตฟอร์มต่างๆ เช่น Hugging Face, GitHub และอินเทอร์เฟซเว็บที่เปิดตัวใหม่ที่ แชท.qwenlm.ai.
วิธีการใช้ Qwen 2.5 ภายในเครื่อง?
ด้านล่างนี้เป็นคำแนะนำทีละขั้นตอนสำหรับ 7 บี แชท จุดตรวจสอบ ขนาดที่ใหญ่กว่าจะแตกต่างกันเพียงแค่ข้อกำหนดของ GPU เท่านั้น
1. ข้อกำหนดเบื้องต้นของฮาร์ดแวร์
| รุ่น | vRAM สำหรับ 8 บิต | vRAM สำหรับ 4 บิต (QLoRA) | ขนาดดิสก์ |
|---|---|---|---|
| คิวเวน 2.5‑7B | 14GB | 10GB | 13GB |
| คิวเวน 2.5‑14B | 26GB | 18GB | 25GB |
RTX 4090 ตัวเดียว (24 GB) เพียงพอสำหรับการอนุมาน 7 B ที่ความแม่นยำ 16 บิตเต็มรูปแบบ การ์ดดังกล่าวสองใบหรือการออฟโหลด CPU บวกกับการควอนไทซ์สามารถจัดการ 14 B ได้
2 การติดตั้ง
bashconda create -n qwen25 python=3.11 && conda activate qwen25
pip install transformers>=4.40 accelerate==0.28 peft auto-gptq optimum flash-attn==2.5
3. สคริปต์การอนุมานอย่างรวดเร็ว
pythonfrom transformers import AutoModelForCausalLM, AutoTokenizer
import torch, transformers
model_id = "Qwen/Qwen2.5-7B-Chat"
device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "You are an expert legal assistant. Draft a concise NDA clause on data privacy."
tokens = tokenizer(prompt, return_tensors="pt").to(device)
with torch.no_grad():
out = model.generate(**tokens, max_new_tokens=256, temperature=0.2)
print(tokenizer.decode(out, skip_special_tokens=True))
การขอ trust_remote_code=True จำเป็นต้องมีธงเนื่องจาก Qwen จัดส่งสินค้าแบบกำหนดเอง การฝังตำแหน่งโรตารี กระดาษห่อ
4. ปรับแต่งด้วย LoRA
ด้วยอะแดปเตอร์ LoRA ที่มีประสิทธิภาพด้านพารามิเตอร์ คุณจึงสามารถฝึก Qwen เฉพาะทางในโดเมนประมาณ 50 คู่ (เช่น ทางการแพทย์) ได้ในเวลาไม่ถึงสี่ชั่วโมงบน GPU 24 GB ตัวเดียว:
bashpython -m bitsandbytes
accelerate launch finetune_lora.py \
--model_name_or_path Qwen/Qwen2.5-7B-Chat \
--dataset openbook_qa \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lora_r 8 --lora_alpha 16
ไฟล์อะแดปเตอร์ที่ได้ (~120 MB) สามารถรวมกลับหรือโหลดตามต้องการได้
ทางเลือก: เรียกใช้ Qwen 2.5 เป็น API
CometAPI ทำหน้าที่เป็นศูนย์กลางสำหรับ API ของโมเดล AI ชั้นนำหลายรุ่น โดยไม่จำเป็นต้องทำงานร่วมกับผู้ให้บริการ API หลายรายแยกกัน โคเมทเอพีไอ เสนอราคาที่ต่ำกว่าราคาอย่างเป็นทางการมากเพื่อช่วยให้คุณผสานรวม Qwen API และคุณจะได้รับ $1 ในบัญชีของคุณหลังจากลงทะเบียนและเข้าสู่ระบบ! ยินดีต้อนรับสู่การลงทะเบียนและสัมผัสประสบการณ์ CometAPI สำหรับนักพัฒนาที่ต้องการผสานรวม Qwen 2.5 เข้ากับแอปพลิเคชัน:
ขั้นตอนที่ 1: ติดตั้งไลบรารีที่จำเป็น:
bash
pip install requests
ขั้นตอนที่ 2: รับรหัส API
- นำทางไปยัง โคเมทเอพีไอ.
- ลงชื่อเข้าใช้ด้วยบัญชี CometAPI ของคุณ
- เลือก แดชบอร์ด.
- คลิกที่ “รับรหัส API” และทำตามคำแนะนำเพื่อสร้างรหัสของคุณ
ขั้นตอนที่ 3: นำการเรียก API มาใช้
ใช้ข้อมูลประจำตัว API เพื่อทำการร้องขอไปยัง Qwen 2.5.แทนที่ ด้วยคีย์ CometAPI จริงจากบัญชีของคุณ
ตัวอย่างเช่นใน Python:
pythonimport requests API_KEY = "your_api_key_here"
API_URL = "https://api.cometapi.com/v1/chat/completions"
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
data = { "prompt": "Explain quantum physics in simple terms.", "max_tokens": 200 }
response = requests.post(API_URL, json=data, headers=headers) print(response.json())
การบูรณาการนี้ช่วยให้สามารถรวมความสามารถของ Qwen 2.5 เข้ากับแอปพลิเคชันต่างๆ ได้อย่างราบรื่น ช่วยเพิ่มฟังก์ชันการทำงานและประสบการณ์ของผู้ใช้ เลือก “qwen-max-2025-01-25″,”qwen2.5-72b-instruct” “qwen-max” จุดสิ้นสุดในการส่งคำขอ API และกำหนดเนื้อหาคำขอ วิธีการคำขอและเนื้อหาคำขอได้รับจากเอกสาร API ของเว็บไซต์ของเรา เว็บไซต์ของเรายังมีการทดสอบ Apifox เพื่อความสะดวกของคุณอีกด้วย
โปรดดูที่ Qwen 2.5 แม็กซ์ API สำหรับรายละเอียดการรวมระบบ CometAPI ได้อัปเดตเป็นเวอร์ชันล่าสุดแล้ว QwQ-32B เอพีไอสำหรับข้อมูลโมเดลเพิ่มเติมใน Comet API โปรดดู เอกสาร API.
แนวทางปฏิบัติที่ดีที่สุดและเคล็ดลับ
| สถานการณ์ | แนะนำ |
|---|---|
| คำถามและคำตอบเกี่ยวกับเอกสารยาว | แบ่งข้อความออกเป็นโทเค็นขนาด ≤16 และใช้คำเตือนเพิ่มเติมในการเรียกข้อมูลแทนบริบทแบบไร้เดียงสา 100 รายการเพื่อลดเวลาแฝง |
| ผลลัพธ์ที่มีโครงสร้าง | คำนำหน้าข้อความระบบด้วย: You are an AI that strictly outputs JSON. การฝึกจัดตำแหน่งของ Qwen 2.5 โดดเด่นในการสร้างแบบจำกัด |
| การเติมโค้ดให้สมบูรณ์ | ชุด temperature=0.0 และ top_p=1.0 เพื่อให้ได้ความแน่นอนสูงสุด ให้สุ่มตัวอย่างลำแสงหลายๆ ลำ (num_return_sequences=4) เพื่อการจัดอันดับ |
| การกรองความปลอดภัย | ใช้ชุด regex “Qwen‑Guardrails” โอเพนซอร์สของ Alibaba หรือ text‑moderation‑004 ของ OpenAI เป็นการผ่านครั้งแรก |
ข้อจำกัดที่ทราบของ Qwen 2.5
- ความไวต่อการฉีดอย่างทันท่วงที การตรวจสอบภายนอกแสดงให้เห็นอัตราความสำเร็จในการเจลเบรกที่ 18% ใน Qwen 2.5‑VL ซึ่งเป็นเครื่องเตือนใจว่าขนาดโมเดลเพียงอย่างเดียวไม่สามารถป้องกันคำสั่งที่เป็นปฏิปักษ์ได้
- สัญญาณรบกวน OCR ที่ไม่ใช่ภาษาละติน เมื่อปรับแต่งให้เหมาะกับงานด้านภาษาภาพ กระบวนการครบวงจรของโมเดลอาจสร้างความสับสนระหว่างภาพอักษรจีนแบบดั้งเดิมกับแบบย่อได้ จึงต้องใช้เลเยอร์การแก้ไขเฉพาะโดเมน
- หน่วยความจำ GPU อยู่ที่ 128 K FlashAttention‑2 ชดเชย RAM แต่การส่งไปข้างหน้าแบบหนาแน่น 72 B ผ่านโทเค็น 128 K ยังคงต้องการ vRAM มากกว่า 120 GB ผู้ปฏิบัติควรใช้ window‑attend หรือ KV‑cache
แผนงานและระบบนิเวศชุมชน
ทีม Qwen ได้ให้คำใบ้ว่า คิวเวน 3.0โดยกำหนดเป้าหมายไปที่โครงข่ายการกำหนดเส้นทางแบบไฮบริด (Dense + MoE) และการฝึกอบรมล่วงหน้าแบบรวมคำพูด-การมองเห็น-ข้อความ ในขณะเดียวกัน ระบบนิเวศน์ยังรองรับ:
- คิว-เอเจนท์ – ตัวแทนห่วงโซ่ความคิดสไตล์ ReAct ที่ใช้ Qwen 2.5-14B เป็นนโยบาย
- อัลปาก้าทางการเงินของจีน – LoRA บน Qwen2.5‑7B ที่ได้รับการฝึกด้วยการยื่นขอตามข้อบังคับ 1 M
- เปิดปลั๊กอินล่าม – สลับ GPT‑4 สำหรับจุดตรวจ Qwen ในพื้นที่ใน VS Code
ตรวจสอบหน้า "คอลเลกชัน Qwen2.5" ของ Hugging Face เพื่อดูรายการจุดตรวจสอบ อะแดปเตอร์ และสายรัดประเมินผลที่อัปเดตอย่างต่อเนื่อง
การวิเคราะห์เชิงเปรียบเทียบ: Qwen2.5 เทียบกับ DeepSeek และ ChatGPT
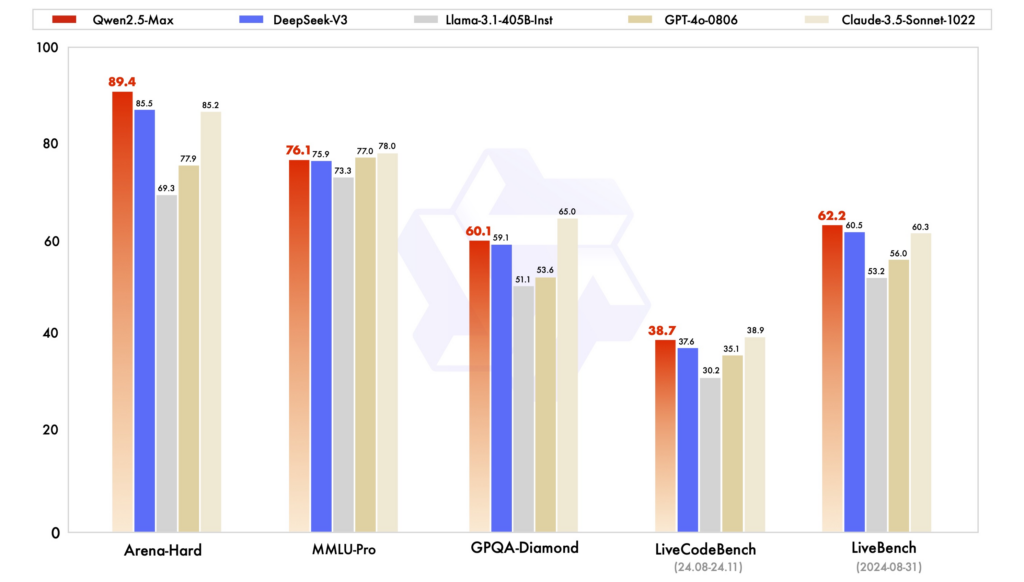
เกณฑ์มาตรฐานประสิทธิภาพ: ในการประเมินต่างๆ Qwen2.5 ได้แสดงให้เห็นถึงประสิทธิภาพที่แข็งแกร่งในงานที่ต้องใช้เหตุผล การเข้ารหัส และความเข้าใจในหลายภาษา DeepSeek-V3 ที่มีสถาปัตยกรรม MoE โดดเด่นในด้านประสิทธิภาพและความสามารถในการปรับขนาด โดยมอบประสิทธิภาพสูงด้วยทรัพยากรการคำนวณที่ลดลง ChatGPT ยังคงเป็นโมเดลที่แข็งแกร่ง โดยเฉพาะในงานภาษาที่มีวัตถุประสงค์ทั่วไป
ประสิทธิภาพและต้นทุน: โมเดลของ DeepSeek โดดเด่นในเรื่องการฝึกอบรมและการอนุมานที่คุ้มต้นทุน โดยใช้ประโยชน์จากสถาปัตยกรรม MoE เพื่อเปิดใช้งานพารามิเตอร์ที่จำเป็นต่อโทเค็นเท่านั้น Qwen2.5 แม้จะมีความหนาแน่น แต่ก็มีตัวแปรเฉพาะเพื่อเพิ่มประสิทธิภาพการทำงานสำหรับงานเฉพาะ การฝึกอบรมของ ChatGPT เกี่ยวข้องกับทรัพยากรการคำนวณจำนวนมาก ซึ่งสะท้อนให้เห็นในต้นทุนการดำเนินงาน
การเข้าถึงและความพร้อมใช้งานของโอเพ่นซอร์ส: Qwen2.5 และ DeepSeek ได้นำหลักการโอเพ่นซอร์สมาใช้ในระดับต่างๆ โดยมีโมเดลที่พร้อมใช้งานบนแพลตฟอร์มต่างๆ เช่น GitHub และ Hugging Face การเปิดตัวอินเทอร์เฟซเว็บล่าสุดของ Qwen2.5 ช่วยให้เข้าถึงได้ง่ายขึ้น แม้ว่า ChatGPT จะไม่ใช่โอเพ่นซอร์ส แต่ก็สามารถเข้าถึงได้อย่างกว้างขวางผ่านแพลตฟอร์มและการผสานรวมของ OpenAI
สรุป
Qwen 2.5 อยู่ในจุดที่เหมาะสมระหว่าง บริการพรีเมียมแบบน้ำหนักปิด และ โมเดลสำหรับนักเล่นอดิเรกแบบเปิดเต็มตัวการผสมผสานระหว่างการออกใบอนุญาตแบบอนุญาต ความแข็งแกร่งในหลายภาษา ความสามารถในการรองรับบริบทระยะยาว และช่วงพารามิเตอร์ที่กว้างขวาง ทำให้กลายเป็นรากฐานที่น่าสนใจสำหรับทั้งการวิจัยและการผลิต
ในขณะที่ภูมิทัศน์ LLM โอเพนซอร์สก้าวหน้าอย่างรวดเร็ว โปรเจ็กต์ Qwen แสดงให้เห็นว่า ความโปร่งใสและประสิทธิภาพสามารถอยู่ร่วมกันได้สำหรับนักพัฒนา นักวิทยาศาสตร์ข้อมูล และผู้กำหนดนโยบาย การเชี่ยวชาญ Qwen 2.5 ในวันนี้ถือเป็นการลงทุนในอนาคตด้าน AI ที่มีความหลากหลายและเป็นมิตรต่อนวัตกรรมมากขึ้น